

阿里云开发者社区






























综合
最新
有奖励
免费用
2025阿里云PolarDB开发者大会等你赴约!
在数字化浪潮中,AI与数据库的融合正重塑行业格局。2025年2月26日(周三),诚邀您在北京朝阳区嘉瑞文化中心参会,探讨数据技术发展与AI时代的无限可能。席位有限,立即免费报名!
PAI Model Gallery 支持云上一键部署 DeepSeek-V3、DeepSeek-R1 系列模型
DeepSeek 系列模型以其卓越性能在全球范围内备受瞩目,多次评测中表现优异,性能接近甚至超越国际顶尖闭源模型(如OpenAI的GPT-4、Claude-3.5-Sonnet等)。企业用户和开发者可
别再熬夜调模型——从构想到落地,我们都管了!
本文将以 Qwen2.5 : 7B 为例进行演示,介绍如何通过人工智能平台 PAI实现AI 研发的全链路支持,覆盖了从数据标注、模型开发、训练、评估、部署和运维管控的整个AI研发生命周期。
摊牌了,代码不是我自己写的
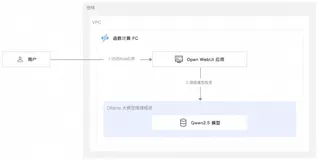
本文介绍了如何使用阿里云函数计算FC部署Qwen2.5开源大模型。Qwen2.5支持128K上下文长度和92种编程语言,通过Ollama托管和Open WebUI交互界面实现快速部署与高效调用。函数计

阿里云百炼xWaytoAGI共学课DAY3 - 更热门的多模态交互案例带练,实操掌握AI应用开发
本文章旨在帮助读者了解并掌握大模型多模态技术的实际应用,特别是如何构建基于多模态的实用场景。文档通过几个具体的多模态应用场景,如拍立淘、探一下和诗歌相机,展示了这些技术在日常生活中的应用潜力。
云原生应用网关进阶:阿里云网络ALB Ingress 全能增强
在过去半年,ALB Ingress Controller推出了多项高级特性,包括支持AScript自定义脚本、慢启动、连接优雅中断等功能,增强了产品的灵活性和用户体验。此外,还推出了ingress2A
云资源运维难?阿里云免费工具来帮忙
阿里云推出免费运维工具——云服务诊断,帮助用户提升对云资源的运维效率、降低门槛、减轻负担。其核心功能包括「健康状态」和「诊断」。通过「健康状态」可实时查看云资源是否正常;「诊断」功能则能快速排查网络、
从大数据到大模型:如何做到“心无桎梏,身无藩篱”
在大数据和大模型的加持下,现代数据技术释放了巨大的技术红利,通过多种数据范式解除了数据的桎梏,使得应用程序达到了“心无桎梏,身无藩篱”的自在境界,那么现代应用有哪些数据范式呢?这正是本文尝试回答的问题
回顾·向新:AI 浪潮下的数据存储进化
在AI 驱动的数据时代,阿里云提供了高性能、高可用、深度集成、弹性降本的存储解决方案来满足多样化的企业需求,赋能企业挖掘数据价值。在此,邀您观看《回顾·向新:AI 浪潮下的数据存储进化》年度发布会,共

DeepSeek API 调用没反应,超时后报错 500, 这是啥意思,按照对接文档调用的啊
Error code: 500 - {error: {code: internal_error, param: None, message: An internal error has occure
AI应用开发
deepseek部署的详细步骤和方法,基于Ollama获取顶级推理能力!
DeepSeek基于Ollama部署教程,助你免费获取顶级推理能力。首先访问ollama.com下载并安装适用于macOS、Linux或Windows的Ollama版本。运行Ollama后,在官网搜索
2025阿里云服务器租用价格表(一年/按月/按小时报价明细)
阿里云服务器多少钱一年上云就上阿里云 很多用户以为阿里云服务器价格比较贵事实上阿里云服务器的价格多次降价云服务器相比其他云厂商有很大的优惠阿小云整理2025年最新的云服务器租用价格表包括轻量应用服务
5分钟零门槛、轻松部署您的专属 DeepSeek 模型

云上一键部署 DeepSeek-V3 模型,阿里云 PAI-Model Gallery 最佳实践
本文介绍了如何在阿里云 PAI 平台上一键部署 DeepSeek-V3 模型,通过这一过程,用户能够轻松地利用 DeepSeek-V3 模型进行实时交互和 API 推理,从而加速 AI 应用的开发和部
【活动系列】在阿里云百炼构建企业级多模态应用,发布作品赢取礼品
本次活动旨在鼓励开发者围绕AI应用开发实训课中的音视频交互和多模态RAG能力,在实训群内上传智能体效果截图或视频。活动时间为2025年1月22日至3月31日,分为作品提交、评审和结果公布三个阶段。参与
阿里云PAI部署DeepSeek及调用
本文介绍如何在阿里云PAI EAS上部署DeepSeek模型,涵盖7B模型的部署、SDK和API调用。7B模型只需一张A10显卡,部署时间约10分钟。文章详细展示了模型信息查看、在线调试及通过Open
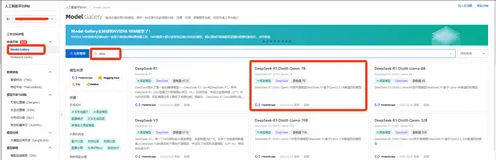
阿里云支持DeepSeek-V3和DeepSeek-R1全自动安装部署,小白也能轻松上手!
阿里云PAI平台支持DeepSeek-V3和DeepSeek-R1大模型的全自动安装部署,零代码一键完成从训练到推理的全流程。用户只需开通PAI服务,在Model Gallery中选择所需模型并点击部
DeepSeek全尺寸模型上线阿里云百炼!
阿里云百炼平台近日上线了DeepSeek-V3、DeepSeek-R1及其蒸馏版本等六款全尺寸AI模型,参数量达671B,提供高达100万免费tokens。这些模型在数学、代码、自然语言推理等任务上表
Qwen2.5-Max:阿里通义千问超大规模 MoE 模型,使用超过20万亿tokens的预训练数据
Qwen2.5-Max是阿里云推出的超大规模MoE模型,具备强大的语言处理能力、编程辅助和多模态处理功能,支持29种以上语言和高达128K的上下文长度。

【保姆级教程】3步搞定DeepSeek本地部署
DeepSeek在2025年春节期间突然爆火出圈。在目前DeepSeek的网站中,极不稳定,总是服务器繁忙,这时候本地部署就可以有效规避问题。本文以最浅显易懂的方式带读者一起完成DeepSeek-r1
很火的DeepSeek到底是什么
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年。因推出开源 AI 模型 DeepSeek-R1 而引起了广泛关注。与ChatGPT相比,大幅降低了推理模型的成本。
低代码+阿里云部署版 DeepSeek,10 分钟速成编剧大师
阿里云部署版DeepSeek重磅发布,钉钉宜搭低代码平台已首发适配,推出官方连接器。用户可轻松调用DeepSeek R1、V3及蒸馏系列模型。通过宜搭低代码技术,结合DeepSeek大模型,仅需10分
零门槛本地部署!手把手教你用Ollama+Chatbox玩转DeepSeek大模型
本教程介绍如何在个人电脑上免费部署DeepSeek模型,无需高端显卡。通过Ollama和Chatbox两款轻量工具,用户可以在普通CPU上流畅运行大型语言模型。Ollama支持跨平台操作,提供一键式安

实战阿里qwen2.5-coder 32B,如何配置Cline的Ollama API接口。
阿里Qwen2.5大模型开源免费,适合编程应用。在Ollama平台下载时,推荐选择带有“cline”字样的Qwen2.5-Coder版本,仅需额外下载适配文件,无需重复下载模型文件。Ollama环境永
用DeepSeek,就在阿里云!四种方式助您快速使用 DeepSeek-R1 满血版!更有内部实战指导!
DeepSeek自发布以来,凭借卓越的技术性能和开源策略迅速吸引了全球关注。DeepSeek-R1作为系列中的佼佼者,在多个基准测试中超越现有顶尖模型,展现了强大的推理能力。然而,由于其爆火及受到黑客
自注意力机制全解析:从原理到计算细节,一文尽览!
自注意力机制(Self-Attention)最早可追溯至20世纪70年代的神经网络研究,但直到2017年Google Brain团队提出Transformer架构后才广泛应用于深度学习。它通过计算序列
如何调用 DeepSeek-R1 API ?图文教程
首先登录 DeepSeek 开放平台,创建并保存 API Key。接着,在 Apifox 中设置环境变量,导入 DeepSeek 提供的 cURL 并配置 Authorization 为 `Beare
轻松在本地部署 DeepSeek 蒸馏模型并无缝集成到你的 IDE
本文将详细介绍如何在本地部署 DeepSeek 蒸馏模型,内容主要包括 Ollama 的介绍与安装、如何通过 Ollama 部署 DeepSeek、在 ChatBox 中使用 DeepSeek 以及在

MNN-LLM App:在手机上离线运行大模型,阿里巴巴开源基于 MNN-LLM 框架开发的手机 AI 助手应用
MNN-LLM App 是阿里巴巴基于 MNN-LLM 框架开发的 Android 应用,支持多模态交互、多种主流模型选择、离线运行及性能优化。
白嫖 DeepSeek ,低代码竟然会一键作诗?
宜搭低代码平台接入 DeepSeek AI 大模型能力竟然这么方便!本教程将揭秘宜搭如何快速接入 DeepSeek API,3 步打造专属作诗机器人,也许你还能开发出更多有意思的智能玩法,让创意在代码
Dify: 一款宝藏大模型开发平台: 部署及基础使用
Dify 是一款开源的大语言模型(LLM)应用开发平台,融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使非技术人员
Cursor 为低代码加速,AI 生成应用新体验!
通过连接 Cursor,打破了传统低代码开发的局限,我们无需编写一行代码,甚至连拖拉拽这种操作都可以抛诸脑后。只需通过与 Cursor 进行自然语言对话,用清晰的文字描述自己的应用需求,就能轻松创建出
一文了解火爆的DeepSeek R1 | AIGC
DeepSeek R1是由DeepSeek公司推出的一款基于强化学习的开源推理模型,无需依赖监督微调或人工标注数据。它在数学、代码和自然语言推理任务上表现出色,具备低成本、高效率和多语言支持等优势,广
ollama+openwebui本地部署deepseek 7b
Ollama是一个开源平台,用于本地部署和管理大型语言模型(LLMs),简化了模型的训练、部署与监控过程,并支持多种机器学习框架。用户可以通过简单的命令行操作完成模型的安装与运行,如下载指定模型并启动
【科普向】我们所说的AI模型训练到底在训练什么?
人工智能(AI)模型训练类似于厨师通过反复实践来掌握烹饪技巧。它通过大量数据输入,自动优化内部参数(如神经网络中的权重和偏置),以最小化预测误差或损失函数,使模型在面对新数据时更加准确。训练过程包括前
DeepSeek安装部署指南,基于阿里云PAI零代码,小白也能轻松搞定!
阿里云PAI平台支持零代码一键部署DeepSeek-V3和DeepSeek-R1大模型,用户可轻松实现从训练到部署再到推理的全流程。通过PAI Model Gallery,开发者只需简单几步即可完成模
[转载] 太神奇了!钉钉低代码×DeepSeek =5分钟手搓出学生个性化习题AI生成器
钉钉低代码宜搭通过拖拉拽让人人都可以成为开发者。未来,在通用人工智能时代,开发更是易于反掌。为了探索如何将 DeepSeek 等最先进的AI大模型融合到自己组织的工作流中,职校覃老师就尝试用钉钉低代码
天天都在说的“算力”到底是个啥?一文全讲透!
算力是数字经济发展的重要支撑,尤其在AI和大数据应用中起着关键作用。阿里云致力于构建全球领先的算力基础设施,助力各行业数字化转型。吴泳铭和马云均强调了算力在未来科技竞争中的核心地位。2023年底,我国
Janus-Pro:DeepSeek 开源的多模态模型,支持图像理解和生成
Janus-Pro是DeepSeek推出的一款开源多模态AI模型,支持图像理解和生成,提供1B和7B两种规模,适配多元应用场景。通过改进的训练策略、扩展的数据集和更大规模的模型,显著提升了文本到图像的

Docker部署RocketMQ5.2.0集群
本文详细介绍了如何使用Docker和Docker Compose部署RocketMQ 5.2.0集群。通过创建配置文件、启动集群和验证容器状态,您可以快速搭建起一个RocketMQ集群环境。希望本文能
【Linux】进程IO|系统调用|open|write|文件描述符fd|封装|理解一切皆文件
本文详细介绍了Linux中的进程IO与系统调用,包括 `open`、`write`、`read`和 `close`函数及其用法,解释了文件描述符(fd)的概念,并深入探讨了Linux中的“一切皆文件”
【linux】Shell脚本中basename和dirname的详细用法教程
本文详细介绍了Linux Shell脚本中 `basename`和 `dirname`命令的用法,包括去除路径信息、去除后缀、批量处理文件名和路径等。同时,通过文件备份和日志文件分离的实践应用,展示了
linux中的目录操作函数
本文详细介绍了Linux系统编程中常用的目录操作函数,包括创建目录、删除目录、读取目录内容、遍历目录树以及获取和修改目录属性。这些函数是进行文件系统操作的基础,通过示例代码展示了其具体用法。希望本文能
python3多线程中使用线程睡眠
本文详细介绍了Python3多线程编程中使用线程睡眠的基本方法和应用场景。通过 `time.sleep()`函数,可以使线程暂停执行一段指定的时间,从而控制线程的执行节奏。通过实际示例演示了如何在多线
ssm026校园美食交流系统(文档+源码)_kaic
本文介绍了基于Java语言和MySQL数据库的校园美食交流系统的设计与实现。该系统采用B/S架构和SSM框架,旨在提高校园美食信息管理的效率与便捷性。主要内容包括:系统的开发背景、目的及内容;对Jav
ssm027学校运动会信息管理系统(文档+源码)_kaic
本文介绍了基于B/S结构的学校运动会信息管理系统开发过程。该系统采用JSP技术和MySQL数据库,确保了系统的安全性和稳定性。系统界面友好、操作简便,涵盖系统概述、分析、设计、数据库设计和测试等环节,
2025年阿里云企业云服务器ECS选购与配置全攻略
本文介绍了阿里云服务器的核心配置选择方法论,涵盖算力需求分析、网络与存储设计、地域部署策略三大维度。针对不同业务场景,如初创企业官网和AI模型训练平台,提供了具体配置方案。同时,详细讲解了购买操作指南
用DeepSeek,就在阿里云!四种方式助您快速使用 DeepSeek-R1 满血版!更有内部实战指导!
DeepSeek自发布以来,凭借卓越的技术性能和开源策略迅速吸引了全球关注。DeepSeek-R1作为系列中的佼佼者,在多个基准测试中超越现有顶尖模型,展现了强大的推理能力。然而,由于其爆火及受到黑客
机器人SLAM建图与自主导航:从基础到实践
通过Gazebo平台和gmapping算法成功生成并保存了一张二维仿真环境地图,为后续的机器人自主导航实验奠定了基础。完整代码及更多细节可参考[GitHub仓库](https://github.com
企业认证购买了云服务器怎样登陆使用
【02】客户端服务端C语言-go语言-web端PHP语言整合内容发布-优雅草网络设备监控系统-2月12日优雅草简化Centos stream8安装zabbix7教程-本搭建教程非docker搭建教程-优雅草solution
【02】客户端服务端C语言-go语言-web端PHP语言整合内容发布-优雅草网络设备监控系统-2月12日优雅草简化Centos stream8安装zabbix7教程-本搭建教程非docker搭建教程-
通义灵码全新上线模型选择功能,新增支持 DeepSeek-V3 和 DeepSeek-R1 模型
阿里云百炼平台推出DeepSeek-V3、DeepSeek-R1等6款新模型,丰富AI模型矩阵。通义灵码随之升级,支持Qwen2.5、DeepSeek-V3和R1系列模型选择,助力AI编程。开发者可通
宜搭 批量导入时,新增或更新数据的校验规则在哪里设置?(请图示)
环境 宜搭轻享版 需求 批量导入时选择“新增或更新数据”可以根据某个字段进行新增或更新。 备注 1现在找不到导入时的校验规则在哪里不知道勾选“触发校验规则、业务规则、集成自动化流、消息通知和
零门槛,轻松体验阿里云 DeepSeek-R1 满血版:快速部署,立享超强推理能力
DeepSeek-R1 是阿里云推出的先进推理模型,专为解决复杂任务设计,尤其在数学推理、代码生成与修复、自然语言处理等领域表现出色。通过阿里云的“零门槛”解决方案,用户无需编写代码即可快速部署 De
VCTGO:一款让开发者直呼“真香”的企业级快速开发平台,你绝对不能错过!
嗨,大家好,我是小华同学。关注我们获取“最新、最全、最优质”的开源项目和高效工作学习方法。今天为大家介绍一款企业级快速开发平台——VCTGO。基于Spring Boot + Vue.js,VCTGO提
阿里云 DeepSeek 模型部署与使用技术评测
随着人工智能技术的不断发展,越来越多的企业和个人开始探索如何利用深度学习模型来提升业务效率和用户体验。阿里云推出的【零门槛、轻松部署您的专属 DeepSeek 模型】解决方案为用户提供了多种便捷的部署
DeepSeek预测:基础编程要凉?炫技赛助你拥有高阶技能!
新的一年想在职场和副业上“狂飙”吗?飞算JavaAI炫技赛助你实现!全球首个完整工程代码生成的AI开发助手,助力高效编程,告别加班。
Flink-CDC同步oracle数据,为什么要授予FLASHBACK权限?
Flink-CDC同步oracle数据为什么要在oracle中授予对应表的FLASHBACK权限呢官方给出的示例授权语句GRANT FLASHBACK ANY TABLE TO flinkuser;
如何实现 MySQL 的读写分离?
本文介绍了 MySQL 读写分离的实现方式及其主从复制原理,解释了如何通过主从架构提升读并发能力。重点分析了主从同步延时问题及解决方案,如半同步复制、并行复制等技术手段,并结合实际案例探讨了高并发场景

MySQL 主从复制
主从复制是 MySQL 实现数据冗余和高可用性的关键技术。主库通过 binlog 记录操作,从库异步获取并回放这些日志,确保数据一致性。搭建主从复制需满足:多个数据库实例、主库开启 binlog、不同

为何长效代理静态IP是网络管理的关键要素
在信息化时代,静态长效IP代理对网络管理至关重要。它能提升网络服务质量,确保远程办公、视频会议等应用的稳定性和连续性;减少延迟和网络拥堵,加快数据传输;提高网络安全,便于设置访问权限,防止未授权访问。
调用钉钉微应用录音功能
调用dd.device.audio.stopRecord报errorCode:7errorMessage: Not authorized 调用开始录音可以成功调用停止录音就报错了
高效销售管理全攻略:如何确保销售目标的精准实现
销售目标设定是销售管理的核心,科学的方法能提高执行力和业绩。本文探讨如何通过目标层级划分、遵循SMART原则、合理分解与资源分配及进度跟踪,确保销售目标的落地执行。借助板栗看板等工具,可进一步优化团队
新用户100万token免费额度!阿里云上线DeepSeek-R1满血版
阿里云推出DeepSeek-R1满血版,新用户可享100万免费Token额度。平台支持多种模型,包括671B参数的DeepSeek-R1和通义千问。结合开源工具Chatbox,用户能轻松对接API,体
2025阿里云PolarDB开发者大会
直播内容:PolarDB开发者大会主论坛 目标人群:开发者、CTO、技术总监、产品总监、架构师等 讲师/嘉宾简介 刘湘雯,阿里云智能集团市场营销总裁 李飞飞,阿里云智能集团副总裁,阿里云智能数据库产品

阿里云《AI 剧本生成与动画创作》解决方案技术评测
随着人工智能技术的发展,越来越多的工具和服务被应用于内容创作领域。阿里云推出的《AI 剧本生成与动画创作》解决方案,利用函数计算 FC 构建 Web 服务,结合百炼模型服务和 ComfyUI 工具,实
《深度学习:图像质量提升的魔法钥匙》
在数字化时代,图像质量常受噪声、雾气等因素影响。深度学习通过卷积神经网络(CNN)、自动编码器和生成对抗网络(GAN)等技术,为图像去噪、去雾和增强提供了高效解决方案。CNN自动提取特征,去除噪声和雾
《探秘目标检测算法:YOLO与Faster R-CNN的原理及发展之旅》
目标检测是计算机视觉的重要任务,旨在识别图像或视频中的目标及其类别。早期依赖滑动窗口和人工特征(如HOG、SIFT),结合SVM等分类器,但计算量大、精度有限。随着深度学习兴起,R-CNN系列(R-C
《深度剖析:人工智能与人类协作模式的未来演变》
人工智能与人类的协作正经历从辅助工具到平等伙伴、特定领域到多领域融合、静态协作到动态自适应、工作场景到全场景渗透的演变。初期,AI作为高效助手处理重复任务;中期成为得力伙伴,参与医疗、科研等领域的深度
《解锁AI芯片新境界:提升专用人工智能芯片通用性与灵活性的热点技术》
在人工智能快速发展的背景下,专用AI芯片虽在特定任务上表现出色,但提升其通用性和灵活性成为关键。热点技术包括:可重构架构(如FPGA),支持动态调整硬件结构;混合精度计算,根据任务需求调整计算精度;多

《探秘AI绿色计算:降低人工智能硬件能耗的热点技术》
在人工智能快速发展的背景下,硬件能耗问题日益突出。为实现绿色计算,降低能耗成为关键课题。新型硬件架构如CRAM、自旋电子器件和量子计算硬件,以及优化的低功耗芯片设计、3D集成技术和液冷散热技术等,正崭
什么是密码疲劳?
密码疲劳是指因频繁管理多个复杂密码而导致的认知超载,常见于混合办公环境中。员工需登录多个系统,常因密码过多、策略复杂而忘记或使用弱密码,导致安全风险和效率低下。解决方案包括单点登录(SSO)、无密码化
Flink+Paimon+Hologres,面向未来的一体化实时湖仓平台架构设计
本文介绍了阿里云实时数仓Hologres负责人姜伟华在Flink Forward Asia 2024上的分享,涵盖实时数仓的发展历程、从实时数仓到实时湖仓的演进,以及总结。文章通过三代实时数仓架构的演

麻烦看下ChaosBlade这条java应用的http故障场景, 没有生效
第一步 挂载 java 进程 ./blade p jvm --pid 1802244http 请求异常 故障注入./blade create http throwCustomException --
1688商品详情数据示例参考,1688API接口系列
在成长的路上,我们都是同行者。这篇关于详情API接口的文章,希望能帮助到您。期待与您继续分享更多API接口的知识,请记得关注Anzexi58哦!
AAAI 2025| S5VH: 基于选择性状态空间的高效自监督视频哈希
AAAI 2025 论文 S5VH 提出基于选择性状态空间模型的高效自监督视频哈希方法,通过双向 Mamba 层和 Self-Local-Global 学习范式,显著提升视频检索性能与推理效率。






活动日历
