


阿里云开发者社区































综合
最新
有奖励
免费用
2025阿里云PolarDB开发者大会来了!
在数字化浪潮中,AI与数据库的融合正重塑行业格局。2025年2月26日(周三),诚邀您在北京朝阳区嘉瑞文化中心参会,探讨数据技术发展与AI时代的无限可能。线上直播同步进行,欢迎参与!

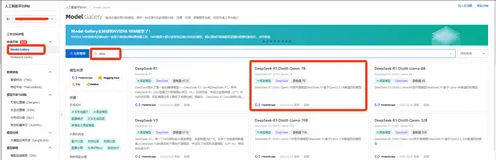
PAI Model Gallery 支持云上一键部署 DeepSeek-V3、DeepSeek-R1 系列模型
DeepSeek 系列模型以其卓越性能在全球范围内备受瞩目,多次评测中表现优异,性能接近甚至超越国际顶尖闭源模型(如OpenAI的GPT-4、Claude-3.5-Sonnet等)。企业用户和开发者可
别再熬夜调模型——从构想到落地,我们都管了!
本文将以 Qwen2.5 : 7B 为例进行演示,介绍如何通过人工智能平台 PAI实现AI 研发的全链路支持,覆盖了从数据标注、模型开发、训练、评估、部署和运维管控的整个AI研发生命周期。
摊牌了,代码不是我自己写的
本文介绍了如何使用阿里云函数计算FC部署Qwen2.5开源大模型。Qwen2.5支持128K上下文长度和92种编程语言,通过Ollama托管和Open WebUI交互界面实现快速部署与高效调用。函数计
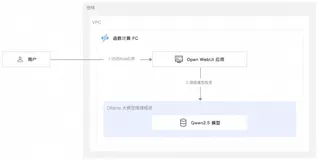
Lindorm作为AI搜索基础设施,助力Kimi智能助手升级搜索体验
月之暗面旗下的Kimi智能助手在PC网页、手机APP、小程序等全平台的月度活跃用户已超过3600万。Kimi发布一年多以来不断进化,在搜索场景推出的探索版引入了搜索意图增强、信源分析和链式思考等三大推

阿里云百炼xWaytoAGI共学课DAY3 - 更热门的多模态交互案例带练,实操掌握AI应用开发
本文章旨在帮助读者了解并掌握大模型多模态技术的实际应用,特别是如何构建基于多模态的实用场景。文档通过几个具体的多模态应用场景,如拍立淘、探一下和诗歌相机,展示了这些技术在日常生活中的应用潜力。
云原生应用网关进阶:阿里云网络ALB Ingress 全能增强
在过去半年,ALB Ingress Controller推出了多项高级特性,包括支持AScript自定义脚本、慢启动、连接优雅中断等功能,增强了产品的灵活性和用户体验。此外,还推出了ingress2A
云资源运维难?阿里云免费工具来帮忙
阿里云推出免费运维工具——云服务诊断,帮助用户提升对云资源的运维效率、降低门槛、减轻负担。其核心功能包括「健康状态」和「诊断」。通过「健康状态」可实时查看云资源是否正常;「诊断」功能则能快速排查网络、
从大数据到大模型:如何做到“心无桎梏,身无藩篱”
在大数据和大模型的加持下,现代数据技术释放了巨大的技术红利,通过多种数据范式解除了数据的桎梏,使得应用程序达到了“心无桎梏,身无藩篱”的自在境界,那么现代应用有哪些数据范式呢?这正是本文尝试回答的问题
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。

DeepSeek个人站点一键部署流程演示

DeepSeek API 调用没反应,超时后报错 500, 这是啥意思,按照对接文档调用的啊
Error code: 500 - {error: {code: internal_error, param: None, message: An internal error has occure
Serverless+AI 轻松玩转高频 AIGC 场景
本书旨在整理和介绍函数计算如何构建各类 AI 应用,以及如何基于函数计算结合其他云产品来部署各种 AI 大模型。主要内容包括:【构建个人专属AI助手】【AI生图】、【AI内容创作】、【打造多形态全天候

深度评测 | 仅用3分钟,百炼调用满血版 Deepseek-r1 API,百万Token免费用,简直不要太爽。
仅用3分钟,百炼调用满血版Deepseek-r1 API,享受百万免费Token。阿里云提供零门槛、快速部署的解决方案,支持云控制台和Cloud Shell两种方式,操作简便。Deepseek-r1满

开源PolarDB-X|follow节点的binlog日志没有自动清理
自建的polarx集中式配置文件里设置的binlog过期时间是一天只有leader库的binlog日志超过24小时会自动清理两个follow节点的binlog日志没有自动清理这个是为什么要怎么设置呢
2025阿里云PolarDB开发者大会
直播内容:PolarDB开发者大会主论坛 目标人群:开发者、CTO、技术总监、产品总监、架构师等 讲师/嘉宾简介 刘湘雯,阿里云智能集团市场营销总裁 李飞飞,阿里云智能集团副总裁,阿里云智能数据库产品

云运维工程师系列电子书:云容器 K8S 异常诊断
本书将从基础概念出发,逐步深入探讨 K8S 集群中常见的故障类型及其成因,并结合实际案例分析给出有效的排查方法和解决方案。通过学习本书,您不仅能够加深对 Kubernetes 工作原理的理解,还能掌握

快速使用 DeepSeek-R1 满血版
DeepSeek是一款基于Transformer架构的先进大语言模型,以其强大的自然语言处理能力和高效的推理速度著称。近年来,DeepSeek不断迭代,从DeepSeek-V2到参数达6710亿的De

用DeepSeek,就在阿里云!四种方式助您快速使用 DeepSeek-R1 满血版!更有内部实战指导!
DeepSeek自发布以来,凭借卓越的技术性能和开源策略迅速吸引了全球关注。DeepSeek-R1作为系列中的佼佼者,在多个基准测试中超越现有顶尖模型,展现了强大的推理能力。然而,由于其爆火及受到黑客
DeepSeek加持的通义灵码2.0 AI程序员实战案例:助力嵌入式开发中的算法生成革新
本文介绍了通义灵码2.0 AI程序员在嵌入式开发中的实战应用。通过安装VS Code插件并登录阿里云账号,用户可切换至DeepSeek V3模型,利用其强大的代码生成能力。实战案例中,AI程序员根据自

快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
👉「免费满血DeepSeek实战-联网搜索×Prompt秘籍|暨6平台横评」
满血 DeepSeek 免费用!支持联网搜索!创作声明:真人攥写-非AI生成,Written-By-Human-Not-By-AI

通义万相2.1视频/图像模型新升级!可在阿里云百炼直接体验
通义万相2.1模型推出新特征,包括复杂人物运动的稳定展现、现实物理规律的逼真还原及中英文视频特效的绚丽呈现。通过自研的高效VAE和DiT架构,增强时空上下文建模能力,支持无限长1080P视频的高效编解
deepseek部署的详细步骤和方法,基于Ollama获取顶级推理能力!
DeepSeek基于Ollama部署教程,助你免费获取顶级推理能力。首先访问ollama.com下载并安装适用于macOS、Linux或Windows的Ollama版本。运行Ollama后,在官网搜索
通义万相Wan2.1视频模型开源!视频生成模型新标杆,支持中文字效+高质量视频生成
2025年1月,阿里通义万相Wan2.1模型登顶Vbench榜首第一,超越Sora、HunyuanVideo、Minimax、Luma、Gen3、Pika等国内外视频生成模型。而在今天,万相Wan2.
基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
【最佳实践系列】零基础上手百炼语音AI模型
阿里云百炼语音AI服务提供了丰富的功能,包括语音识别、语音合成、实时翻译等。通过`alibabacloud-bailian-speech-demo`项目,可以一键调用这些服务,体验语音及大模型的魅力,
DeepSeek-R1满血版上线阿里云,新用户专享100万token额度,5分钟快速部署!
DeepSeek是当前AI领域的热门话题,尤其其大模型备受关注。由于网页版访问时常超时,推荐使用阿里云百炼的API调用方式快速体验。此方法仅需五分钟,提供100万免费Token,有效期至2025年7月

【保姆级教程]】5分钟用阿里云百炼满血版DeepSeek, 手把手做一个智能体
阿里云推出手把手学AI直播活动,带你体验DeepSeek玩法。通过阿里云百炼控制台,用户可免费开通满血版R1模型,享受100w token免费额度。活动还包括实验步骤、应用开发教程及作业打卡赢好礼环节
一文详解DeepSeek和Qwen2.5-Max混合专家模型(MoE)
自20世纪中叶以来,人工智能(AI)和机器学习(ML)经历了从基于逻辑推理的专家系统到深度学习的深刻转变。早期研究集中在规则系统,依赖明确编码的知识库和逻辑推理。随着计算能力提升和大数据时代的到来,机
Qwen2.5-Max:阿里通义千问超大规模 MoE 模型,使用超过20万亿tokens的预训练数据
Qwen2.5-Max是阿里云推出的超大规模MoE模型,具备强大的语言处理能力、编程辅助和多模态处理功能,支持29种以上语言和高达128K的上下文长度。

Spring 集成 DeepSeek 的 3大方法(史上最全)
DeepSeek 的 API 接口和 OpenAI 是兼容的。我们可以自定义 http client,按照 OpenAI 的rest 接口格式,去访问 DeepSeek。自定义 Client 集成

KTransformers:告别天价显卡!国产框架让单卡24G显存跑DeepSeek-R1 671B大模型:推理速度飙升28倍
KTransformers 是由清华大学和趋境科技联合推出的开源项目,能够优化大语言模型的推理性能,降低硬件门槛。支持在仅24GB显存的单张显卡上运行671B参数的满血版大模型。
如何调用 DeepSeek-R1 API ?图文教程
首先登录 DeepSeek 开放平台,创建并保存 API Key。接着,在 Apifox 中设置环境变量,导入 DeepSeek 提供的 cURL 并配置 Authorization 为 `Beare
Step-Video-T2V:碾压Sora?国产开源巨兽Step-Video-T2V杀到:300亿参数一键生成204帧视频
Step-Video-T2V 是阶跃星辰团队推出的开源文本到视频模型,拥有 300 亿参数,能生成长达 204 帧的高质量视频。它支持中英文提示输入,并通过深度压缩的变分自编码器和扩散 Transfo
新用户100万token免费额度!阿里云上线DeepSeek-R1满血版
阿里云推出DeepSeek-R1满血版,新用户可享100万免费Token额度。平台支持多种模型,包括671B参数的DeepSeek-R1和通义千问。结合开源工具Chatbox,用户能轻松对接API,体
阿里云PAI部署DeepSeek及调用
本文介绍如何在阿里云PAI EAS上部署DeepSeek模型,涵盖7B模型的部署、SDK和API调用。7B模型只需一张A10显卡,部署时间约10分钟。文章详细展示了模型信息查看、在线调试及通过Open
3月5日(周三),Data+AI Workshop(深圳站)邀您参加!
本期沙龙将深度解析阿里云自研数据库PolarDB与AI的融合,涵盖应用场景、核心技术及实践案例,助力企业快速拥抱AI,实现业务落地和价值创造。立即免费报名参加,前50位参会者还可获精美伴手礼!
基于LLM打造沉浸式3D世界
阿里云数据可视化产品DataV团队一直在三维交互领域进行前沿探索,为了解决LLMs与3D结合的问题,近期在虚幻引擎内结合通义千问大模型家族打造了一套基于LLM的实时可交互3D世界方案,通过自然语言来与
DeepSeek-V3 高效训练关键技术分析
本文从模型架构、并行策略、通信优化和显存优化四个方面展开,深入分析了DeepSeek-V3高效训练的关键技术,探讨其如何以仅5%的算力实现对标GPT-4o的性能。
手把手教你使用 Ollama 和 LobeChat 快速本地部署 DeepSeek R1 模型,创建个性化 AI 助手
DeepSeek R1 + LobeChat + Ollama:快速本地部署模型,创建个性化 AI 助手

企业如何搭建技术支持体系?盘点三个需重点关注的方面
随着企业业务规模扩大,售后技术支持压力上升,构建高效专业的远程技术支持体系至关重要。向日葵技术支持方案从三个方面助力企业:1. 远控工具高效安全,提升客户体验;2. 自动化工单平台,优化需求流转;3.
Windows 11 绕过 TPM 方法总结,通用免 TPM 镜像下载 (2025 年 2 月更新)
Windows 11 绕过 TPM 方法总结,通用免 TPM 镜像下载 (2025 年 2 月更新)


Splunk Enterprise 9.4.1 (macOS, Linux, Windows) 发布 - 机器数据管理和分析
Splunk Enterprise 9.4.1 (macOS, Linux, Windows) 发布 - 机器数据管理和分析

Sophos Firewall (SFOS) v21 MR1 发布 - 下一代防火墙
Sophos Firewall v21 MR1 是一款下一代防火墙,提供自动响应威胁、强大防护性能和随时随地办公的安全保障。新版本增强了 SSL VPN、IPsec VPN、NAT64、DHCP 和蜂
NetScaler Console 14.1 Build 43.50 (ESXi, Hyper-V, KVM, Xen) - 集中管理 NetScaler
NetScaler Console 14.1 Build 43.50(原 NetScaler ADM)是基于 Web 的集中管理解决方案,支持本地和云端的 NetScaler 部署,包括 MPX、VP
NetScaler 14.1 Build 43.50 (nCore, VPX, SDX, CPX, BLX) - 混合多云应用交付控制器
NetScaler 14.1 Build 43.50 是一款混合多云应用交付控制器,支持 nCore、VPX、SDX、CPX 和 BLX 平台。它提供高性能、全面安全和深度可观察性,适用于本地、云端及


1.3K star!VisActor团队开源神器,3秒生成商业级图表,程序员直呼真香!
VChart是由VisActor团队推出的高性能可视化解决方案,GitHub上已获2.3k+星标。它支持Web、小程序和Node.js多端适配,具备百万级数据流畅渲染、20+图表类型深度定制等优势。核
深入探索嵌入式开发中的 FreeRTOS:从入门到精通
大家好,我是V哥。本文将带你从入门到深入掌握FreeRTOS,一款开源、轻量级的实时操作系统。FreeRTOS为嵌入式开发提供了高效的任务管理、资源调度等功能,极大提升了开发效率和系统可靠性。我们将探
React Native 核心技术知识点快速入门
大家好,我是 V 哥。React Native 是 Facebook 开发的开源框架,使用 JavaScript 和 React 构建跨平台移动应用。本文将介绍其核心技术,帮助初学者快速入门。内容涵盖
电梯安全事故频发,如何加强电梯安全管理?
电梯安全问题备受关注。2月18日,云南昆明一小区电梯冲顶坠落事故引发公众对物业电梯管理的质疑。维保记录漏洞、设备老化及不良乘梯行为是常见事故原因。为加强安全管理,需建立完善的巡检、维保和应急救援制度,
【📕分布式锁通关指南 05】通过redisson实现分布式锁
本文介绍了如何使用Redisson框架在SpringBoot中实现分布式锁,简化了之前通过Redis手动实现分布式锁的复杂性和不完美之处。Redisson作为Redis的高性能客户端,封装了多种锁的实
从“被动响应”到“主动决策” | 智能小Q如何助力快消品行业供应链数智化升级
编者按:在大模型技术重构数据智能分析应用的背景下,Quick BI 推出的问数助手——智能小Q 凭借其革新功能体验,自面世以来持续获得市场青睐。历经一年多的商业化验证,已成熟融入金融、零售、高端制造、

使用 PAI-DSW x Free Prompt Editing图像编辑算法,开发个人AIGC绘图小助理
使用 PAI-DSW x Free Prompt Editing图像编辑算法,开发个人AIGC绘图小助理
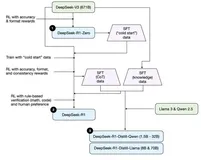
使用A10单卡24G复现DeepSeek R1强化学习过程
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。
大模型推理主战场:什么才是通信协议标配?
DeepSeek加速了模型平权,大模型推理需求激增,性能提升主战场从训练转向推理。SSE(Server-Sent Events)和WebSocket成为大模型应用的标配网络通信协议。SSE适合服务器单

如何将DVD转ISO文件?完整指南与最佳工具推荐
如何将DVD转为ISO文件?完整指南与最佳工具推荐 ISO文件是光盘的1:1数字副本,包含所有数据。将DVD转为ISO便于备份、存储和高质量播放。使用DVDFab、MakeMKV等工具,简单几步即可
钉钉H5微应用调用支付宝支付,业务需要有自己的App上架吗?
企业内部网页应用H5微应用调用支付宝支付 目前实现方式 网页内JS调用dd jsapi, 调用支付宝支付 根据钉钉文档https://open.dingtalk.com/document/isva






活动日历
