本节书摘来自异步社区《统计会犯错——如何避免数据分析中的统计陷阱》一书中的第2章,第2.1节,作者【美】Alex Reinhart(亚历克斯·莱因哈特),更多章节内容可以访问云栖社区“异步社区”公众号查看
第2章 统计功效与低功效统计
统计会犯错——如何避免数据分析中的统计陷阱

在第1章中,你已经注意到由于没有收集足够的数据,可能会忽略那些真实的效应。例如,你拒绝了具有疗效的新药,或者忽视了重要的副作用。因此,应该收集多少数据才比较合适呢?
统计功效可以回答以上问题。一项研究的功效指的是,它能将某种强度的效应从纯粹的运气因素里区分并识别出来的概率。如果一种药物治疗作用特别明显,那么它的识别就比较容易,而如果疗效轻微,其识别往往比较困难。
功效曲线
设想我的对手有一枚不均匀的硬币。掷出这枚硬币,正面向上或反面向上的概率并不是1/2,相反,其中有一面向上的概率为60%。我和我的对手用这枚硬币赌博,他宣称这枚硬币是公平的,但是我对此强烈怀疑,我应该用什么方法来证明他在欺骗我呢?
我不能简单地连续投掷这枚硬币100次,然后以正面向上次数是否为50次来判断硬币是不是均匀的。事实上,即使是一枚均匀的硬币,也不可能恰恰是50次正面向上。正面向上次数的概率分布如图2-1所示。
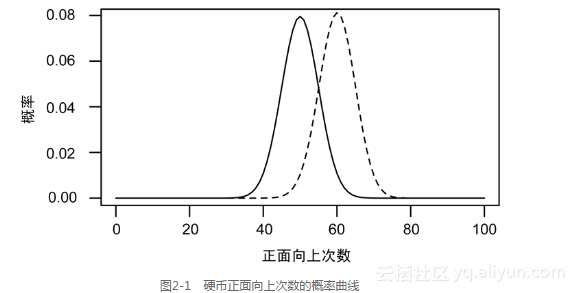
(掷一枚均匀硬币(实线)或者不均匀硬币(虚线)100次,正面向上次数的概率曲线,其中不均匀硬币正面向上概率为60%。)
对于一枚均匀硬币,正面向上50次是最可能的结果,但其发生的概率也小于10%,另外有略小的概率得到51次或52次正面向上的结果。事实上,当连续掷一枚硬币100次,正面向上次数落在[40,60]区间内的概率为95%。换句话说,在这个区间之外的可能性较低:只有1%的概率得到正面向上多于63次或少于37次的结果。正面向上90次或100次几乎是不可能的。
一枚不均匀的硬币,其正面向上的概率为60%。连续掷这枚硬币100次,所得正面向上次数的概率分布如图2-1中的虚线所示。均匀硬币的概率分布曲线和不均匀硬币的概率分布的曲线有重合的部分,但是不均匀硬币与均匀硬币相比,更有可能得到正面向上70次的结果。
我们做一点数学计算。连续投掷一枚硬币100次,然后数出正面向上的次数。如果这个次数不是50次,那么在这枚硬币是均匀硬币的假设下,计算产生该结果或者更为极端结果的概率,这个概率就是p值。如果这个p值等于或小于0.05,我们就在统计上显著地认为这枚硬币是不均匀的。
利用p值的方法,我们有多大的可能性发现一枚硬币是不均匀的?图2-2所示的功效曲线回答了这个问题。在图2-2中,横轴表示硬币正面向上的概率,表示硬币不均匀的程度,而纵轴是利用计算p值的方法,得到这枚硬币不均匀结论的概率。
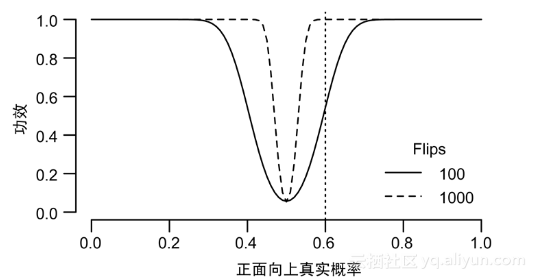
(连续投掷硬币100次或1000次两种情况下,假设检验的功效。垂直的线表示一枚正面向上真实概率为60%的非均匀硬币在这两种情形下的检验功效。)
假设检验的功效是指产生统计显著性结果(p <0.05)的概率。对于一枚均匀的硬币,40~60次正面向上的概率为95%,因此对一枚不均匀的硬币而言,检验功效就是指这枚硬币正面向上的次数落在区间(40,60)以外的概率。有3种因素可以影响检验的功效。
- 偏差大小。一枚硬币越不均匀,越容易被检测出来。
- 样本容量。如果收集足够多的样本,那么即使是细微的偏差也可以检测出来。
- 测量误差。在上面的例子中,你能非常容易地数出正面向上的次数,但有一些试验的指标测量非常困难,如医学研究中的疲劳感和沮丧感。
我们首先讨论偏差大小对检验功效的影响。如图2-2所示,如果一枚硬币轻微有偏,其正面向上的概率不是1/2而是60%,那么在连续投掷100次后,通过假设检验的方法得到这枚硬币是非均匀硬币结论的概率为50%,也即是说,检验功效为50%。我们有一半的机会,得到正面向上次数少于60次的结果,从而不能判断这枚硬币是非均匀硬币。这表明,仅仅依靠100次投掷数据,并不能把硬币的轻微偏倚与随机误差分割开来。只有当这枚硬币严重有偏,比如正面向上的概率为80%时,我们才能得到其为非均匀硬币的结论,此时检验功效为100%。
这里就有一个问题,即使一枚硬币是均匀的,我们仍有5%的概率得到该枚硬币不均匀的结论。我们的检验把p <0.05作为硬币不均匀的证据,但一枚均匀的硬币也可能得到p <0.05的结果。
幸运的是,增加样本容量可以提高检验功效。图2-2中的虚线说明,如果连续投掷硬币1000次,那么利用假设检验方法很容易识别出硬币是否均匀,此时检验功效明显高于投掷硬币100次时的情形。这是因为,如果连续投掷一枚均匀硬币1000次,正面向上次数位于(469,531)区间内的概率为95%,而正面向上超过600次可能性很低,一旦出现该结果就认为这枚硬币是非均匀的,一枚正面向上概率为60%的非均匀硬币却很可能得到超过600次的结果,所以也就比较容易检测出来。但不幸的是,我们没有时间连续投掷一枚硬币1000次。因此,出于实际考虑,单纯靠增加样本容量来提高检验功效是不现实的。
数出正面向上或者反面向上的次数比较容易,但对其他指标测量就没那么简单了,比如智商。由于问题不同或被测人的心情波动,每次测试的分数会发生变化,从而为智商测量添加了随机噪声因素,使测试分数不能真实反映真正的智商。如果你比较两组受试人员的智商分数,你会发现不仅不同受试者的分数具有正态变异,即使对同一名测试者,测试分数也会随机波动。如果一个测试带有较大的误差,那么统计检验的功效也会降低。
数据越多,我们越容易从噪声中区分出信号。但说起来容易做起来难,科学家没有足够的资源开展具有高功效的科学研究,来检测他们要找的信号,因此在开展研究之前他们就注定会失败。
低功效困境
考虑下面一个试验:在相同条件下,比较Fixitol和Solvix这两种不同的药物,以确定哪种药物更加安全。由于药物的副作用比较罕见,所以即使分别在100名患者身上测试这两种药物,在每一群体里,也只要在少数患者身上产生严重的副作用。正如同我们难以区分两枚正面向上概率分别为 50%和 51%的硬币,如果两种药物的副作用发生率分别为 3%和 4%,那么也难以把它们区别开来。如果有 4 名服用Fixitol的患者产生了严重的副作用,而只有 3 名服用Solvix的患者产生了副作用,此时你并不能得到Fixitol更有可能产生副作用的结论,这是因为此时检验的功效较低。
如果一个试验不能有效地识别出某种效应,那么我们就说这个试验低功效。
你也许认为,对于医学试验而言,计算功效是必需的一个步骤;新药开发人员为了检验一种药物的效果,应确定召集多少名患者来参与这个试验,而通过计算一下功效就可以得到答案。令科学家感到满意的试验的功效是80%或者比这更高,这也就意味着能够有80%或更高的概率检测到一种特定大小的真实效应。
然而,鲜有科学家计算统计功效,也很少有期刊论文提及统计功效。在最权威的期刊《科学》和《自然》上,在开展研究之前计算统计功效的文章少于3%1。实际上,许多试验的结论是:“虽然两组效果具有大的差异,但是在统计上并没有显著性”。这些试验丝毫不提及,可能是因为没有收集到足够的数据,所以它们的功效较低,发现差异却没能得到显著性的结论2。如果有些试验是在比较两种药物的副作用,那么以上错误结论就意味着,两种药物都是同样安全的,而事实上,其中某种药物可能比另一种更加危险。
你也许认为上述问题只在副作用发生概率很低或者副作用影响不大时才会产生。事实上绝非如此。我们收集了1975~1990年在权威医学期刊上发表的一些试验,发现在那些报告没有显著性差异的试验中,约有4/5的试验没有收集足够的数据,来检测治疗组与对照组之间25%的效果差异。也就是说,即使一种药物比另一种药物能将病状降低25%,却由于没有足够的数据,仍然不能作出上述结论。另外,约有2/3的试验的功效较低, 未能检测出50%的效果差异3。
在最近关于癌症试验的一项研究中,有类似的结论:在那些得到阴性结论的研究中,仅有一半有足够的功效能识别出主要结果的差异,其他研究均因功效过低没有得到有用发现4。在这些低功效的研究中,只有不到10%解释了为什么选取的样本容量如此之少。类似的低功效问题在医药研究的其他领域也时常发生5,6。
以上问题在神经科学的研究中尤为突出。每项神经科学研究收集了过少的数据,以至于平均每项研究只有20%的功效。为了弥补低功效的不足,你可以将研究同一效应的所有论文数据整理在一起进行分析。既然神经科学研究都以动物作为研究对象,因此就产生了伦理问题。如果一项研究功效较低,那么只有完成更多的研究,使用更多的动物作为研究对象,才能发现真正的效应7。伦理道德委员会不应支持开展那些功效较低、不能发现目标效应的研究。
低功效的原因
奇怪的是,低功效问题由来已久,但现在仍然非常普遍。1960年,Jacob Cohen分析了发表在《Journal of Abnormal and Social Psychology》8上试验的功效,他发现平均而言,这些试验能够检测出中等效应的功效只有48%[1]。Jacob Cohen的研究被引用上百次,而且类似的评论也接踵而至,一致要求进行试验时需计算功效并扩大样本容量。1989年,一篇评论指出,在Cohen得到以上分析结论后的10年里,平均的研究功效实际上又下降了9!这是因为,研究人员开始意识到多重假设检验问题,而在解决多重假设检验问题的过程中,研究的功效进一步降低了(我们将在第4章讨论多重假设检验问题,那时你将会看到我们必须在研究功效和多重假设检验修正之间做出取舍)。
为什么我们经常忽视功效计算?原因之一是样本大小和功效结果给我们的直观感受不一样。即使在功效极低的情况下,我们经常认为试验对象已经足够多了。举个例子,假如你在测试一项新的心脏病治疗方案,希望将死亡风险从20%降低至10%。你可能会这样想:如果对50名患者采用这项新的方案,没有发现明显差别,那么新治疗方案就没带来多少好处。但是为了使功效达到80%,你实际上需要多达400名患者,每个治疗组里有200名患者而不是50名患者10。临床医生往往未意识到他们的样本容量太小。
在数学上准确计算功效难度较大,甚至有时无法计算,这是忽视功效计算的另外一个原因。在统计课堂上,一般不会讲授计算功效的方法,并且一些商用软件中也没有计算功效的函数。当然,你也可以不用数学而是利用随机模拟的方法计算功效。首先模拟具有你所期待效应的成千上万个数据集,然后在每一个数据集上进行统计检验,得到显著性检验结果的比例就是功效。但是这种方法需要编程经验,而且模拟现实数据也充满技巧。
尽管计算困难,但你可能认为科学家应该注意到了功效问题并试图进行改进:连续5次或6次试验都显示不显著的结果,科学家就应怀疑在某些地方出了问题。然而,一般的研究并不只做单个假设检验而是很多、很有可能得到显著性的结果 11。只要该显著性的结果非常有趣,就可以看成是论文的亮点,这名科学家此时早已忘记研究功效较低的问题。
低功效并非意味着,当科学家们声称两组之间没有显著性差异时,他们在说谎。但是如果认为这些结果表明确实不存在差异,那这就是误导了。差异甚至一个非常重要的差异可能是存在的,只是由于研究的规模太小没能发现这种差异。下面,我们考虑生活中的一个例子。
遇红灯时错误转弯
20世纪70年代,美国许多地方开始允许司机遇到红灯时右转。而在很多年以前,城市道路规划人员认为,允许红灯右转会带来安全隐患,引起更多的交通事故和行人死亡。但是1973年的石油危机促使交通管理部门考虑实施这项政策,因为这样就能减少等待红灯时的汽油浪费。最终,国会要求各州实施该政策,并把它作为一项能源节约措施,就像建筑物隔热有效采光措施一样。
一些研究考察了该政策带来的安全影响。其中,弗吉尼亚公路与运输局的咨询部门对比了政策变化前后,州内 20 个交叉路口的交通事故发生情况。他们发现,在允许红灯右转之前,这些交叉路口发生了 308 次事故,而在允许红灯右转之后,相同时间内发生了 337 次事故。他们的报告指出,虽然事故发生率增加了,但这种差异在统计上是不显著的。在看到这份报告后,公路与运输局的官员写道:“我们可以相信,红灯右转政策并未给汽车驾驶员或行人带来显著的危险隐患”12。显然,官员们把统计上的不显著直接当作现实中的不显著。
后续研究有类似的发现:相撞事故次数略有增加,但并没有足够的数据表明这种增加是显著的。正如一份报告所指出的:没有理由怀疑在实施“红灯右转”后,行人被撞事件的次数增加了。
显然,以上研究均是低功效的。但是越来越多的州和城市开始允许红灯右转,在整个美国这种做法也变得非常普遍。没有人尝试将各项研究的数据整理在一起,形成一个更有用的数据集。与此同时,越来越多的行人被撞伤,越来越多的汽车被撞毁。没有人收集足够的数据来说明这种情况,直至若干年后,一些研究才发现,由于右转,汽车撞毁频率比以前提高 20%,行人被撞的频率比以前高 60%,几乎是骑自行车的人被撞频率的 2倍13,14,[2]。
然而,交通安全部门并没有吸取教训。例如, 2002 年的一项研究考察铺砌的路牙对乡村公路交通事故发生率的影响。不出意外,路牙降低了事故风险,但没有足够的数据说明这种下降在统计上是显著的,因此研究人员的结论是,铺砌路牙子的花费是不值得的。他们混淆了不显著的差异和完全没有差异,尽管数据已经表明铺砌的路牙可以改善交通安全12。一个更好的分析的结论似乎应该是这样的,铺砌路牙的好处在统计上是“不显著”的,但是数据表明铺砌路牙确实带来了巨大好处。这就是置信区间的分析方法。
置信区间的优势
与考虑试验结果的显著性相比,置信区间是一种更合理的结论表述,它可以给出效应的大小。即使置信区间包含0,它的宽度也会告诉你很多信息:一个狭窄的包含 0 的置信区间表明效应可能比较小,而一个较宽的包含 0 的置信区间则表明测量值并不十分精确,因而不足以作出结论。
对于那些与0没有显著差异的测量,物理学家常常使用置信区间给出它们的界值。例如,在搜索基础粒子时,“该信号在统计上是不显著的”这种说法没有意义。相反,对于粒子撞击时的速率,物理学家一般利用置信区间赋给它们一个上界,然后将这个结果与预测粒子行为的已有理论进行比较(促进未来的试验人员建造更大的试验设备来发现它)。
利用置信区间来解释结果为试验设计提供了一种新思路。不再关注显著性假设检验的功效,转而问这样的问题:“我应该搜集多少数据来度量理想精度的效应?”尽管高功效的试验可以产生显著性的结果,但如果其置信区间很宽的话,结论同样难以解释。
每次试验的数据会不一样,所以每次试验得到的置信区间大小也会发生变化。以前是选择一个样本大小以达到某种程度的功效水平,现在我们选择一个样本容量大小,只要使得到的置信区间的宽度小于目标宽度的概率达到99% 即可(这个数字被称为其并没有固定的标准,或者是95%)16。
在常见的假设检验里,已经发展出很多依赖于置信度的样本量选择方法;不过这仍然是一个新的领域,统计学家还没有研究透彻17(这些方法的名字是样本估计的精度,英文缩写为AIPE)。统计功效比置信度使用更多,在各领域里统计学家还没有采用置信度。尽管如此,这些方法非常有用。统计显著性经常是拐杖,名字虽然中听,但并不能像一个好的置信区间那样提供多少有用的信息。
膨胀的真理
假设相对于安慰剂,Fixitol能将症状减少20%。但你的试验样本可能太小,没有足够的统计功效可靠地检测到这种差异。我们知道,小试验常常产生更具有变异性的结果;你很可能恰恰找到10个幸运的患者,他们的感冒时间都较短,但找到10000个感冒时间都较短的患者的可能性基本上为0。
设想不停地重复以上试验。有时你的患者并不是那样幸运,因此你没有注意到你的药物具有明显的改善作用;有时你的患者恰好具有代表性,他们的症状减少了20%,但你没有足够的数据证明这种减少在统计上是显著的,因此你将其忽略;还有一些时候,你的患者非常幸运,他们的症状减少远超过20%,这时你停下试验说:“看,它是有效的!”你把所有的结果画在了图2-3中,显示了试验结果产生的概率。
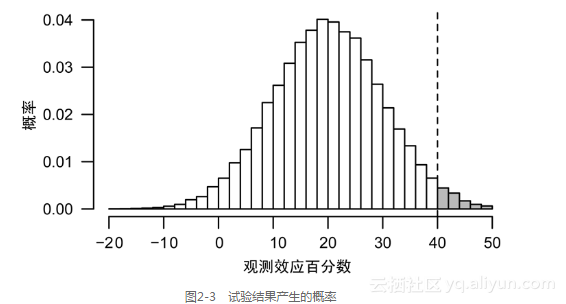
(如果你重复进行试验,你将会看到试验结果的一个分布。垂直虚线是在统计上具有显著性的效应值。真正的效应值是20%,但你可以发现观测效应值分布在-10%~50%这样一个较宽区间里。只有少数幸运的试验结果是显著的,但是它们都夸大了效应的大小。)
你得到了正确的结论,即Fixitol是有效的。但因为试验是低功效的,所以你夸大了效果的大小。
以上现象被称为真理膨胀,或者M型错误、赢者灾难。这种现象经常发生,尤其在那些进行类似试验争相发表最激动人心结果的领域经常见到,例如药理学试验、流行病学研究、基因关联研究、心理学研究等。在那些引用最多的医学文献里以上现象也比较常见18,19。在快速发展的领域,比如基因研究,早期论文的结果常常比较极端,这是因为期刊很愿意发表这样新的、令人振奋的结果。相比较而言,后续研究的结果就不那么夸张了20。
就连《自然》和《科学》这样的顶级期刊,也喜欢发表具有开创性理论成果的研究论文。这些开创性成果一般意味着大的效应,往往是在鲜有人研究的、比较新奇的领域里产生的。这是慢性真理膨胀与顶级期刊的完美组合。已有证据表明,期刊影响因子和其发表的“激进”研究具有相关性。那些结论不怎么令人振奋的研究更接近于真理,但是大多数的期刊编辑却对其不感兴趣21,22。
当一项研究声称在小样本下,发现了一个大效应时,你的第一反应不应是:哇哦,他们发现了这么有趣的现象!而应是:他们的研究可能是低功效的23!来看一个例子。从2005年起,Satoshi Kanazawa发表了一系列关于性别比例的论文,最后一篇论文的题目是“漂亮父母会生更多的女儿”。他出版了一本书专门对此进行讨论,书中涉及其他一些他发现的“政治上不正确的真相”。这些研究在当时非常流行,尤其是因为Satoshi Kanazawa所得到的惊人结论:最漂亮父母生女儿的概率是52%,最不漂亮的父母生女儿的概率是44%。
对生物统计学家而言,一个微弱的效应——如一个或两个百分点,具有重要的含义。Trivers–Willard假设认为:如果父母有某些特点,更容易生出女孩,那么他们就会有更多的女孩,反之亦然。如果你认为漂亮的父母更容易生出女孩的话,那么平均而言,这些漂亮父母就会拥有更多的女儿。
但是Kanazawa得到的结论比较特殊,后来他也承认在分析中有些错误。基于他所收集的数据,修正之后的回归分析表明,漂亮父母拥有女儿的概率确实比平均水平高4.7%,但这只是一个点估计,这个差距的置信区间是(−3.9%, 13.3%),0在这个区间内部23。这说明,虽然Kanazawa采用了3000对父母的数据,但结果在统计上仍然是不显著的。
需要大量的数据才能可靠地识别出微小的差异。例如一个0.3%的差异,即使有3000对父母的数据,也不能将0.3%的观测差异与随机误差区分开来。在3000的样本容量下,只有5%的可能性得到在统计上显著的结果,而且这些显著性的结果已经将效应值(0.3%)夸大了至少20倍,并且约有40%的可能得到的显著性结论恰恰相反,即认为漂亮父母更有可能生男孩23。
因此,虽然Kanazawa进行了完美的统计分析,但他仍然高估了真实的效应。按照他的做法,他甚至还可以发表这样的论文:工程师会有更多的男孩,护士会有更多的女孩[3]。他的研究无法识别预想大小的效应。如果他在研究之前进行一个功效分析的话,可能就不会犯这种错误了。
微小的极端
因为小规模、低功效研究的结果变异性很大,所以产生了真理膨胀的问题。有时你非常幸运,得到一个在统计上显著却夸大其辞的估计结果。除了显著性检验分析,在其他分析中,较大的变异性也会带来麻烦。来看一个例子。假如你负责公立学校的改革,作为最优教学方法研究的一部分,你想分析学校规模大小对学生标准化测验分数的影响。小学校是否比大学校更好呢?应该建立为数众多的小学校还是建立若干所大学校?
为了回答以上问题,你整理了表现良好的学校的一个列表。普通学校平均有1000名学生,你发现最好的10所学校学生的数目均少于1000。这似乎意味着,小学校做的最好,原因可能是因为学生少,老师可以深入了解每个学生并有针对性地帮助他们。
然后你又看了一下表现最差的学校,这些学校都是一些拥有成千上万学生、超负荷工作老师的大学校,与你的预想恰恰相反,这些最差的学校也是一些小学校。
为什么?现在,看一下测试分数与学校规模的散点图,如图2-4所示。小学校学生少,所以他们的测试得分有很大的变异性。学生越少,就越难估计出一个学校的真实平均水平,甚至少数几个异常的分数就会使一个学校的平均水平发生大的偏差。当学校的规模变大时,测试分数的波动变小,平均分数有上升趋势24。
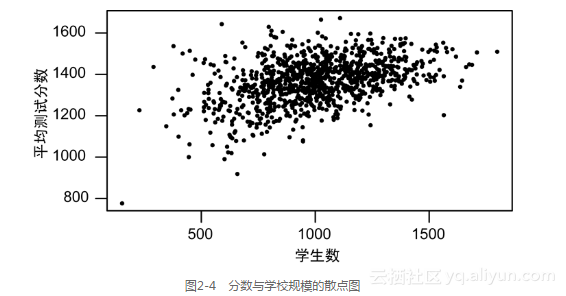
(学生越多的学校,测试分数的波动程度就越小。这些数据是基于宾州公立学校的真实观测数据模拟得到的。)
来看另外一个例子:在美国,肾癌发生率最低的县往往位于中西部、南部和西部的农村地区。为什么这样?也许是因为农民干农活锻炼了身体,或者是因为他们一直呼吸免受污染的空气,还可能是因为他们生活压力很小。
但是,我们发现那些具有极高肾癌发生率的县也往往位于中西部、南部和西部的农村地区。
为什么这样?这是因为,农村地区的县人口特别少。如果一个县有10个居民,而其中有一位患有肾癌,那么该县的肾癌发生率就是最高的。由于人口特别少,这些县的肾癌发生率具有很大的波动性,其置信区间往往也会很宽25。
应对以上问题的常用方法是压缩估计。对于那些人口很少的县,你可以将他们的癌症发生率与全国水平做一个加权平均,从而使得过高或过低的癌症发生率向全国平均水平收缩。如果一个县的居民特别少,那么在加权平均时应该为全国水平赋一个较大的权重,而如果一个县的居民较多,那就为该县的癌症发生率设定较大的权重。在癌症发生率地图的绘制以及其他一些应用中,压缩估计是一种普遍的做法[4]。不过,压缩估计会不加选择地改变结果:如果一个县的人口较少,但是其癌症发生率确实很高,压缩估计往往会使得最后的估计结果接近全国水平,完全掩盖了这个县的真实情况。
处理以上问题并没有万全之策。最好的做法就是完全回避它:不按照县的划分来估计发生率,而是按照国会选区进行计算,这是因为在美国每个国会选区的人口都大致相当,而且远远多于一个普通县域的人口。不过,国会选区在地图上的形状往往奇形怪状,不如县域那么规则,所以基于国会选区得到的癌症发生率地图,虽然估计比较准确,但却难以解释。
而且,让各个单元都有相同样本大小的做法并不总是奏效。例如,在线购物网站在对商品进行排序时,其依据是顾客的评分,但此时并不能保证参与各种商品评分的顾客数目都是一样的。又如,在像reddit这样的论坛网站上,一般会按照网友的评价对帖子进行排序,但是有的帖子有很多人评价,而有的帖子评论人寥寥可数,这与帖子发布的时间、地点和楼主有很大的关系。压缩估计就可以应对以上情况。购物网站可以将每个产品的评分与总体水平进行加权平均。这样,鲜有人评分的产品默认是平均水平,而有大量顾客评分的产品可以按照它们各自的平均评分进行 排序。
另外,reddit网站上的帖子并没有评分机制,跟帖的人只能表示赞成或反对。为了对帖子进行排序,一般会求得这个帖子支持率的置信区间。当帖子的跟帖很少时,置信区间会很宽,随着跟帖的人越来越多,置信区间就会越来越窄,最后集中到一个确定的值(例如,70%的跟帖喜欢这个帖子)。新帖子的排名往往垫底,但随着跟帖人越来越多,其中质量较高的帖子置信区间变得越来越窄,不久就会上升到前面。并且,由于帖子是依据支持率而不是跟帖数目进行排序的,所以新帖子也完全可以和具有大量跟帖的帖子竞争26,27。
注意事项
- 在设计试验时,先计算统计功效,以此来决定所需样本的大小。不要跳过这一步。如果你对统计功效不甚了解,可以阅读Cohen’s的经典教材《行为科学的统计功效分析》或者向统计专家进行咨询。如果试验样本大小不切实际,最后结论的可靠性就会大打折扣。
- 如果你想精确地度量某种效应,请不要单纯地进行显著性检验,更好的做法是设计满足置信度的试验,这样就能以理想的精度度量某种效应。
- 请铭记“统计上不显著”并非意味着“0”。即使你的结果是不显著的,该结果也代表基于你所收集的数据所得到的估计。“不显著”与“不存在”并不等价。
- 持质疑态度看待那些低功效研究的结论,这些结论可能夸大真实情况。
- 请使用置信区间作为最后的答案,不要过分关注统计上的显著性。
- 当比较规模不同的组时,请计算置信区间。置信区间可以反映估计的精确程度:规模较大的组置信区间较窄,估计更精确。
[1] 如果两个试验组之间具有0.5个标准差大小的差异,Cohen就把这种差异称为中等大小的效应。
[2] 需要注意的是,由于红灯右转带来的交通事故所造成的人员伤亡总数是很少的。红灯右转带来了更多的交通事故,但是从整个美国来看,增加的伤亡人数不超过100人15。尽管如此,因为统计上的错误,红灯右转这项政策每年仍会使数十人丧生。
[3] Kanazawa在2005年的《Journal of Theoretical Biology》上确实发表了这篇文章。
[4] 当然,“压缩估计”不等于简单地加权平均,在统计分析中,有更为复杂的压缩估计方法。