
最近有朋友问,客户在香港ECS上搭建的MySQl,大概有100GB以上的数据,能否通过MaxCompute做海量数据分析,我的回答是YES!
但客户担心香港与大陆之间数据连通性问题,我的回答依然是YES!
为了让更多个客户不再困扰,笔者做了一份教程,可以通过大数据开发套件中的经典网络进行同步数据,有图为证!
准备工作
1、注册并开通阿里云账号、Access id、Access Key;开通方法:https://help.aliyun.com/document_detail/47703.html?spm=5176.doc30266.6.544.NLgOin
2、购买并开通香港区域经典网络ECS;购买地址:https://ecs.console.aliyun.com/#/create/prepay/?data=eyJkYXRhIjp7InZtX3JlZ2lvbl9ubyI6ImNuLWhvbmdrb25nLWFtNC1jMDQifX0%3D
3、下载并搭建MySQL 5.7 ;下载地址:https://dev.mysql.com/downloads/windows/installer/5.7.html
4、购买并开通MaxCompute、大数据开发套件;开通方法:https://help.aliyun.com/document_detail/30263.html?spm=5176.doc30262.6.546.El4j9u
跨区域数据同步
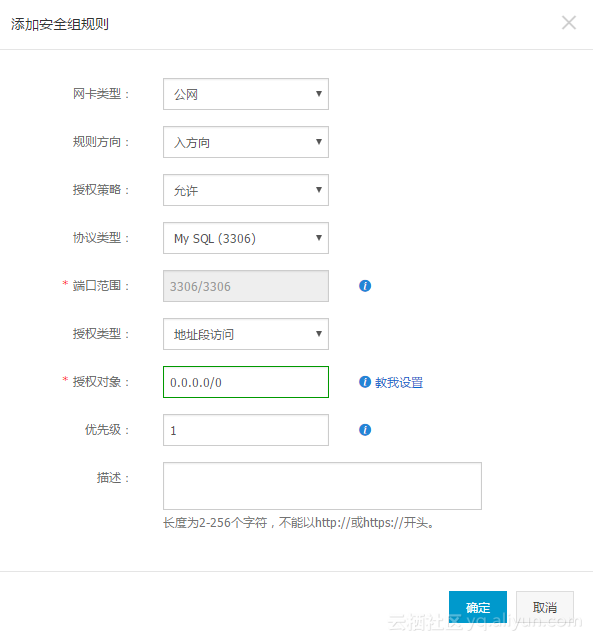
1、设置ECS安全组
进入ECS管控台->ECS管理,设置安全组,添加外网3306 IP访问权限;
2、添加数据源
通过控制台进入大数据开发套件;
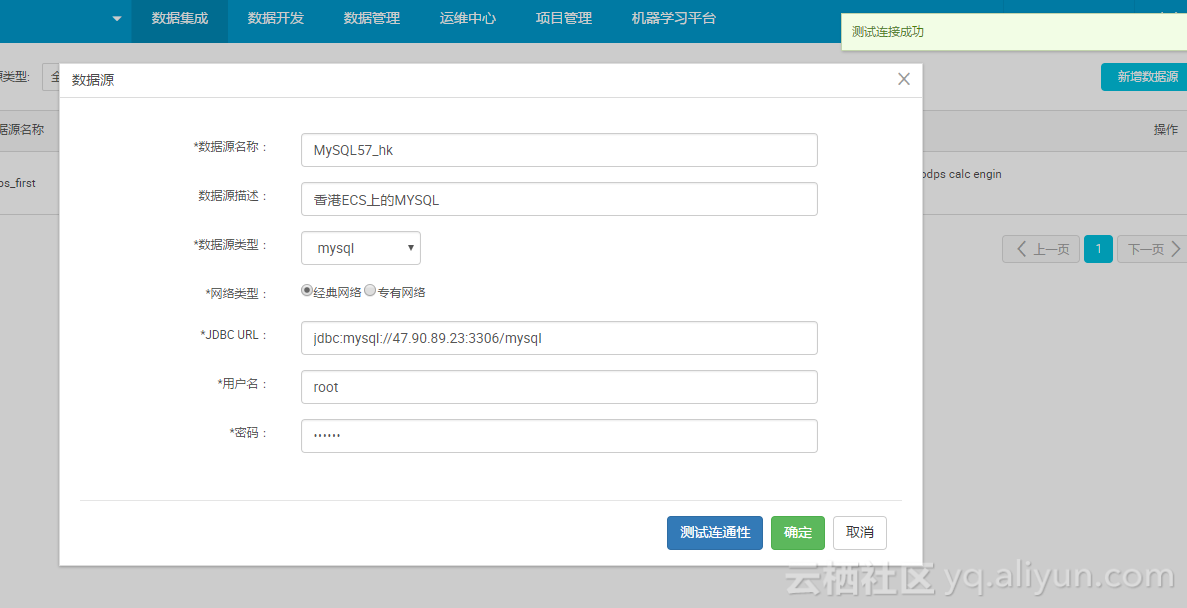
点击数据集成->左侧列表"数据源"页面->点击右上交“新增数据源”;
输入数据源MySQL57_hk,选择MySQL 经典网络,MySQL的JDBC地址、账号信息;
点击连通性验证网络;如果不通,请参照本文常见问题;
3、创建并设置同步任务
点击进入同步任务,选择需要导入的源表;
数据源MySQL57_hk,选择或通过搜索框查找"movie_info_mysql_hk",点击下一步;
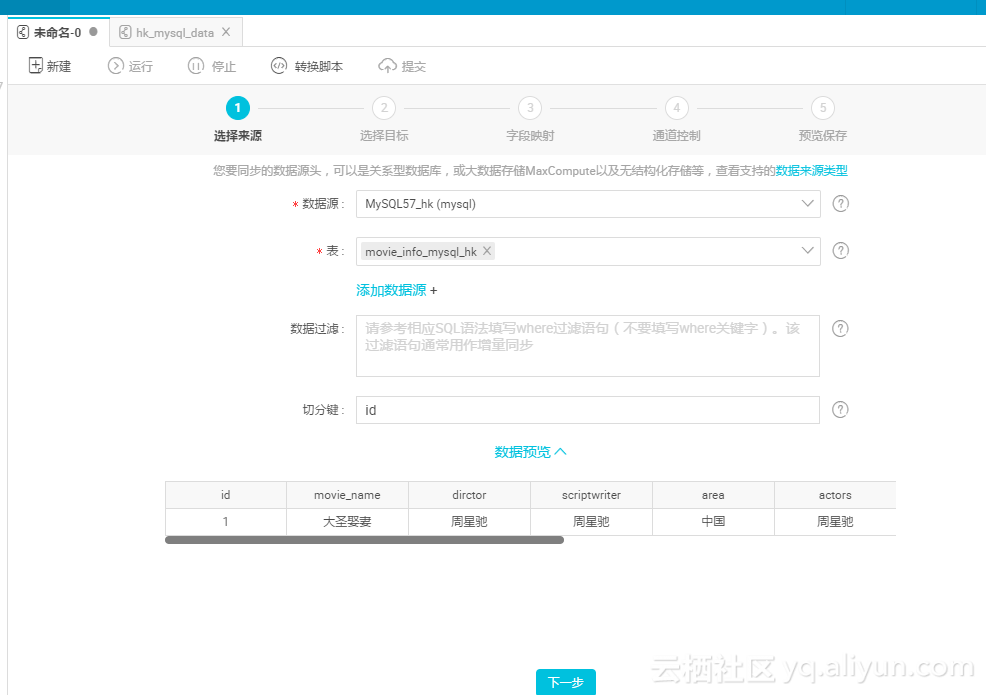
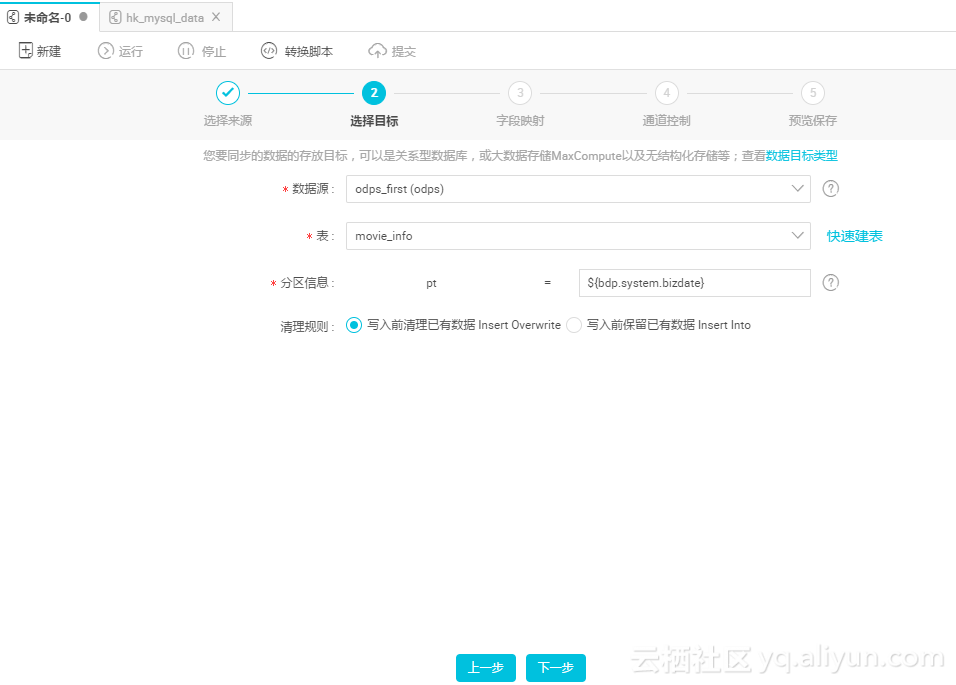
选择目标数据库opds_first,点击快速建表,同步表结构,修改脚本中的表名,改为movie_info,点击提交;
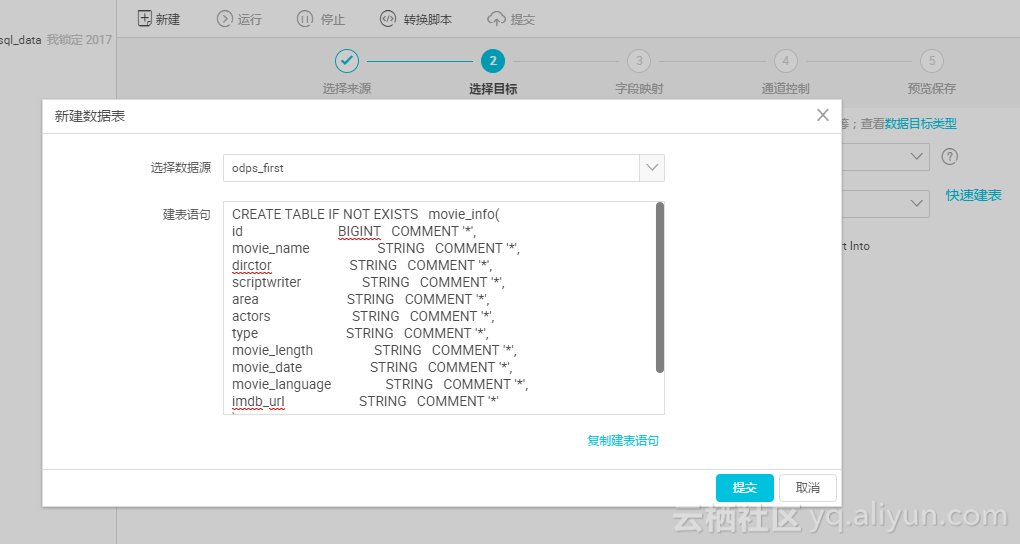
分区信息默认为时间变量,点下一步;
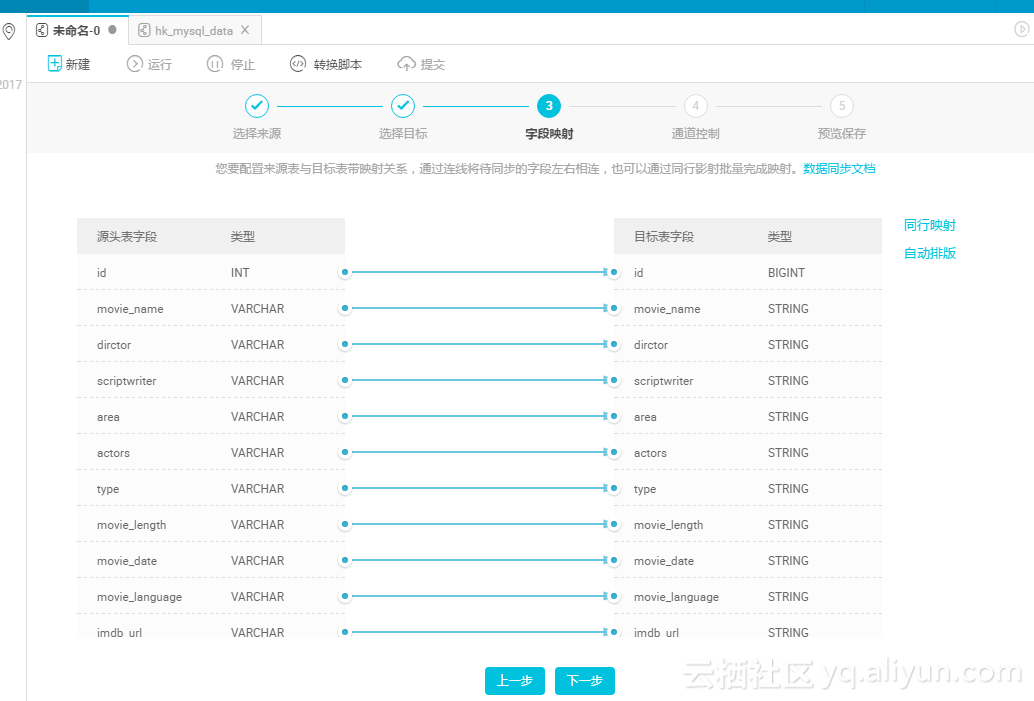
字段自动映射,跳过即可;
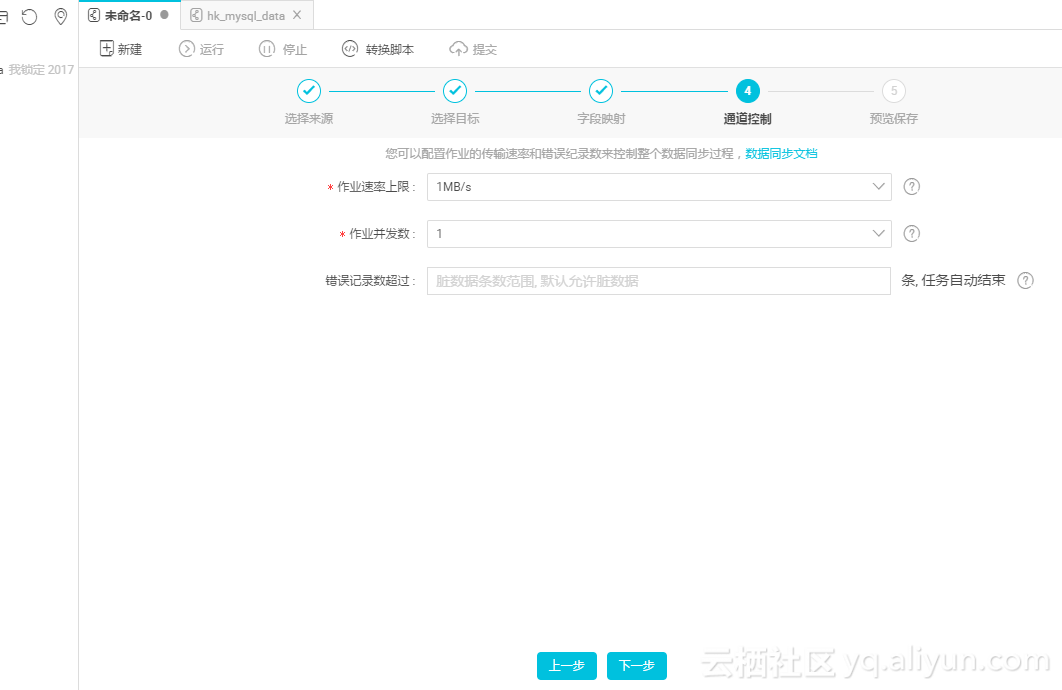
通道控制默认,点击下一步;
预览后,点击保存;
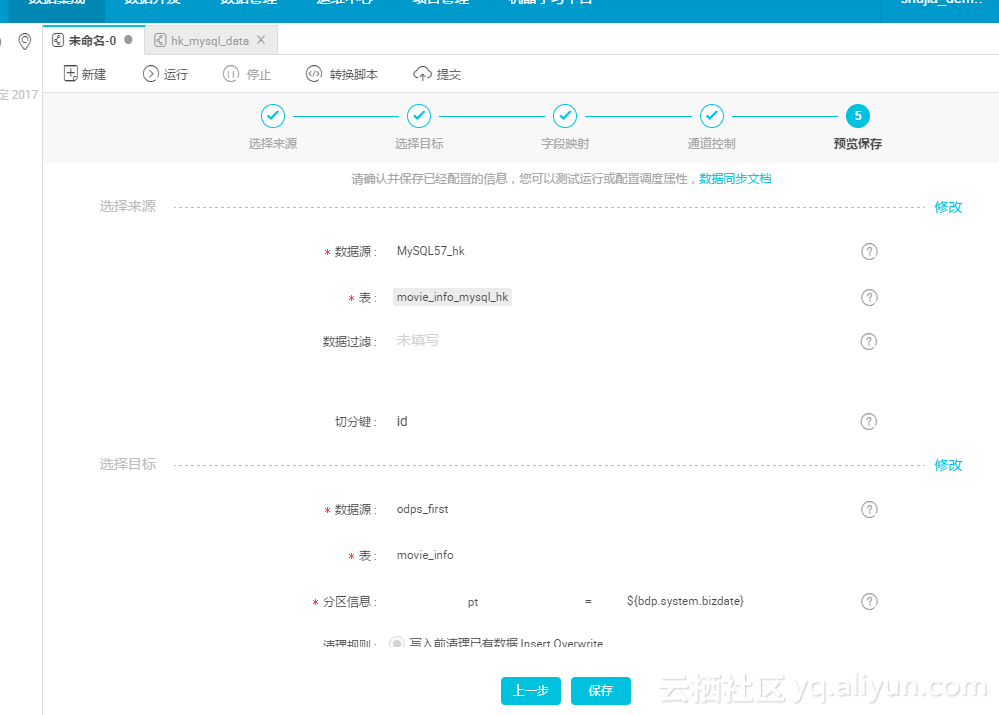
点击保存后,命名数据同步任务名称hk_mysql_data1;
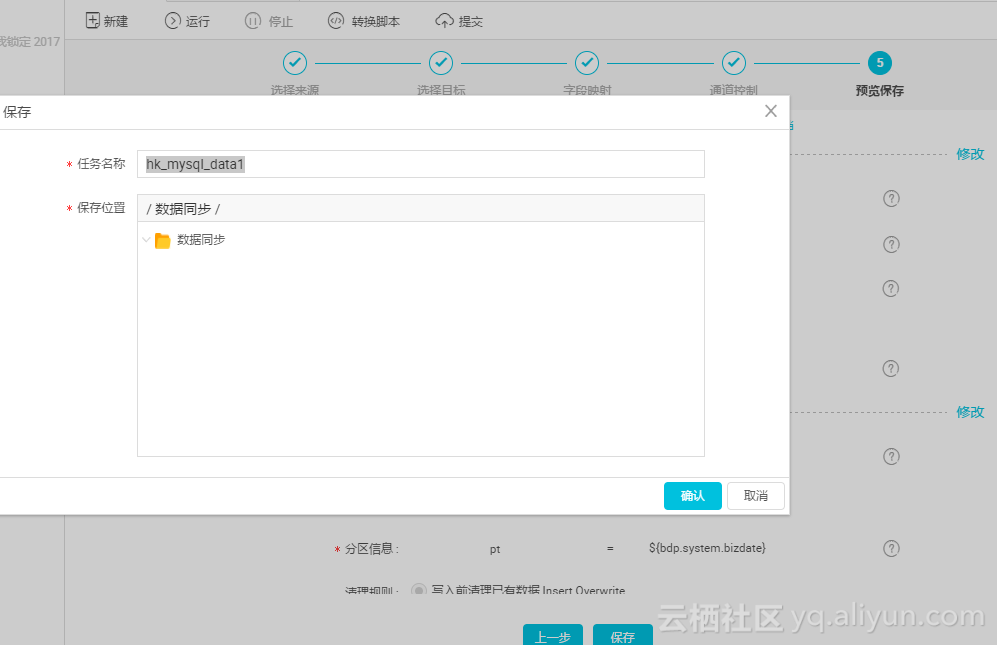
4、执行并验证数据
手动执行数据同步,点击运行,选择当天时间戳;
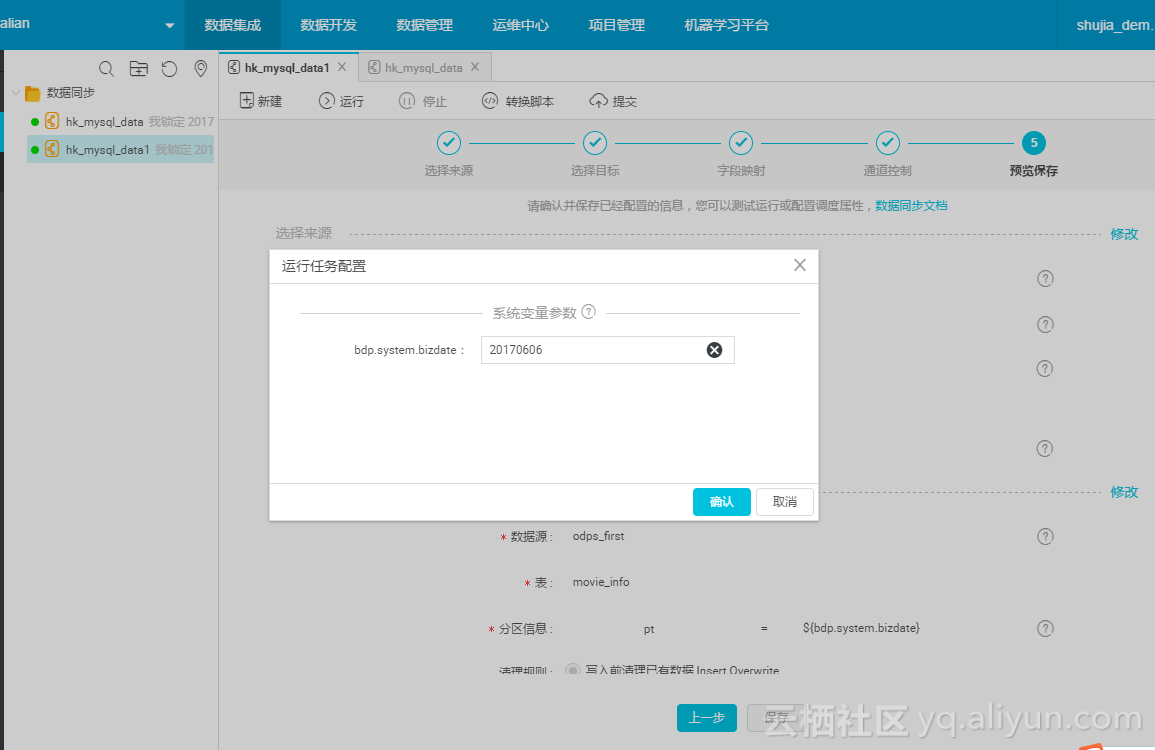
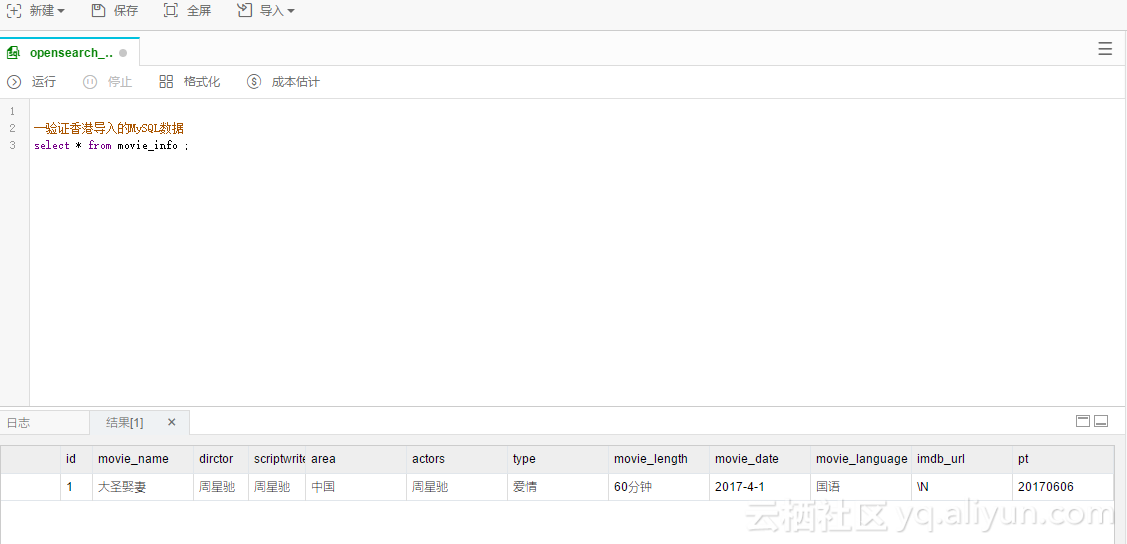
执行完成后,我们去验证一下数据;
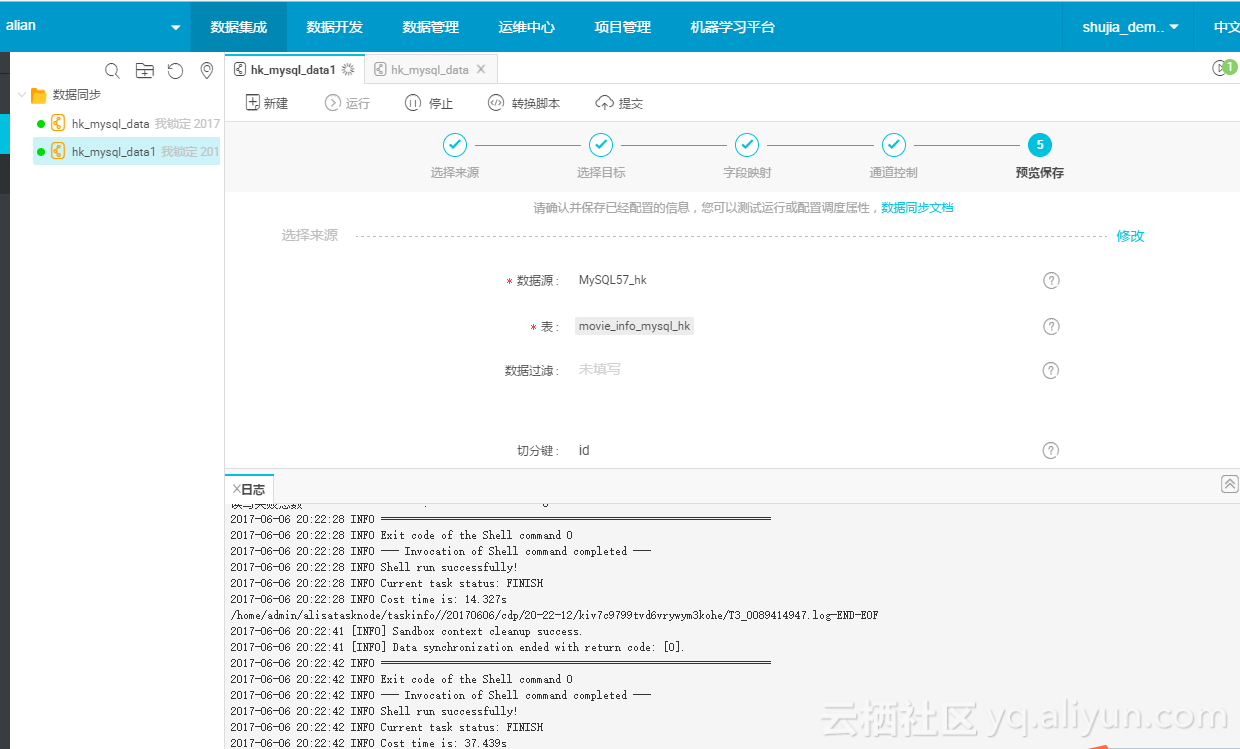
进入大数据开发套件->数据开发;

验证导入的数据;
实验遇到的问题
Q:大数据开发套件(数据集成)中连接不上ECS上的MySQL ,提示:测试连接失败,测试数据源连通性失败:连接数据库失败, 数据库连接串:jdbc:mysql://47.90.89.23:3306/MySQL57-hk, 用户名:root, 异常消息:Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
A:进入ECS安全组规则->设置网络入口访问权限,测试的话可以设置为0.0.0.0/0;
Q:大数据开发套件(数据集成)中连接不上ECS上的MySQL ,提示:测试连接失败,测试数据源连通性失败:连接数据库失败, 数据库连接串:jdbc:mysql://47.90.89.23:3306/mysql, 用户名:root, 异常消息:null, message from server: "Host '121.43.110.160' is not allowed to connect to this MySQL server"
A:MySQL设置远程访问权限,参照:http://kouss.com/aliyun-ecs-mysql-allow-navicat.html


