Amazon Aurora: Design Considerations for HighThroughput Cloud-Native Relational Databases,来自Sigmod 2017,可以在Werner Vogels Blog上下载到 (SIGMOD 官网还没更新)。
读下来感受:
- Aurora 是一个OLTP数据库,最大存储为64TB/SSD,不是为OLAP设计
- 通过将计算逻辑下推到Storage Node(非传统意义上存储节点),从而解决了写与修改过程中一份数据被放大的问题
- 本身不解决分库分表等机制,既数仓与需要过PB级数据场景并不适合Aruora
- Aurora 巧妙的地方在于,他使用了MySQL计算引擎,100%兼容了MySQL以及PG两种数据库100%语法,因此应用迁移成本为0,按照存储节点适配的思路,任何开源的数据库理论上都较快适配上来,但对于块存储等设备对于所有数据库适配性而言稍差
- 在解决放大问题后,可以达到很高的写IOPS,并且随着SSD或其他硬件性能提升,呈线性结构
- 一份数据默认会存3个AZ,每个AZ中存储2份,通过局部与全局Failover概率的权衡,达到尽可能少事物提交延迟与失败概率
- Aurora完全构建在EC2(Local Storage)、LBS、VPC、S3(备份)等这些产品基础上,并没有单独从物理机上研发,也印证了AWS云产品有两类:基础性云产品、以及应用层云产品的构建思路。好处是可以将规模、多租户隔离等问题屏蔽掉,专心研发最重要的Storage Node即可
数据库上分布式方案
AWS传统RDS设计
下图是AWS RDS方案,数据库的计算和事务使用EC2,存储则在分布式系统中: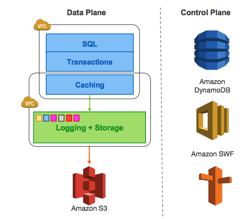
在云计算场景下,一般使用块存储来Host数据库服务器,既数据库的读写会在多个存储节点上进行强一致性的同步处理,带来的好处是存储持久性(Durbility)高。并且分布式存储本身可以无限扩张,因此数据量不是大的问题。除此之外,一些新存储技术的诞生,例如NVMe SSD单机提供较高IOPS设备使得分布式存储也能在较高读写情况下有很强Throughput。
AURORA中存储设计
多副本读与写
分布式存储并不是万能的,面临的最大挑战则是Transaction 等 2 Phase Commit(2PC)协议对于可靠性以及延时的TradeOff。
磁盘、网络、机柜、机房等都有一定的ATF(年故障率),并且日常维护重启、升级等操作会增加这类临时不可用时间。一般采用多副本选举来解决该问题:例如3个副本的情况下,写必须要有2个以上(Majority)副本写成功才可以,在读的情况下也必须保证有2个:V-Read + V-Write> V-Copy
Aruora设计中使用了3 AZ,每个AZ 下2 Copy的设置,共计6个副本。AWS 传统的服务,例如S3、Kinesis等都是3副本设计。这样的设置主要从实际观察情况出发:
- 在同一个AZ下下硬盘、节点损坏、维修等是常态。在同一个AZ下设置2 Copy可以尽可能减少这类操作对用可用性影响
- 机房级AZ问题不常发生,例如水灾、火灾以及天花板损坏等故障(roof failure?)
在写入场景下6 Copy需要保证4个副本完成,在读场景下只要7-4=3 个副本一致就可以了
存储块与日常运维
- Aurora下存储最小单位叫Segment,每个Segment大小为10GB
- Protection Group(PG)是一个逻辑单位,代表的是6个Segment
- Segment是维护与调度的最小单元,一个Segment故障时,同AZ的万兆网络可以在10秒内就行修复
存储节点Segement这种设计对于日常运维比较重要,例如在热点问题上(Heat Management),两个实例都非常大需要进行调度,或存储节点OS需要Patch,存储节点的代码需要更新,这种类似Ping-Pang升级的方式可以使得AZ级存储节点能够灵活配置。
存储节点设计核心思想(只处理LOG,部分计算下推)
AWS传统RDS问题在于对于写放大,用如下这张图就能发现,在一个Master-Slave(主从热备)RDS场景下,主节点和存储层的交互会被放大多次:
- Replication Log
- Redo Log (临时存储最后N个)
- Data(最新数据库结构数据,内存中定时Dump)
- FRM Files(这个数据量一般比较小)
假设EBS有2-Copy,则一份数据写入/更改被放大了222 = 6 倍,如果EBS为3-Copy,这个数据约为12倍。如果有备节点也算上的话,这个数字既为24倍。直接使用分布式存储放大非常严重。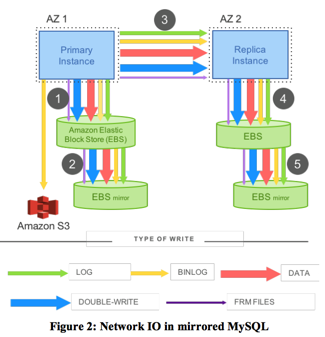
搞过Hbase人应该知道,对于LSM这样的场景,一般10MB/S原始数据写入,后台网络流量会达到80-100MB/S,原因也是类似,一份数据写入后放大如下3-Redo + 3 Mem File + 3 Times Merge = 9 Origin Input
但这种模式也带来来了好处,就是CPU会浪费得比较少,因为3-Copy只占据IO和网络,CPU本质上只有一份。
Aurora提出的思路是,计算节点直接将RedoLog下推到存储节点,每个存储节点根据RedoLog 来构成本地(Local Segment)存储状态,多个存储可靠性通过副本数来保障。每个存储节点也可以将Segment 定时同步到S3上增加可靠性。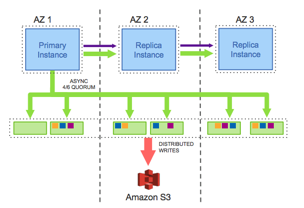
每个存储节点在处理时,在处理请求,写入本地RedoLog后既返回,以保证低延时: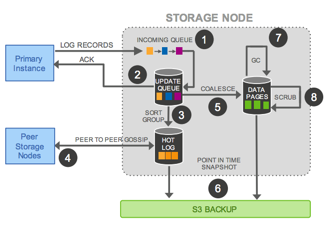
存储节点共有5个数据链路上的步骤:
- 接收到请求,加入内存中的队列(主要是为了做batch commit)
- 将批量Redolog存储到本地磁盘
- 内存中对于批量redolog进行整理,确定还有哪些没有catchup
- 与其他副本存储节点进行gossip,进行对齐
- (可选)将本地redolog和 snapshot data dump到S3进行备份
后台工作(2个):
- 根据redo log进行gc,删除无用的data 和 redo log
- 本地盘做CRC进行数据检查,以及恢复
PAPER其他部分
明白了主要差别后,其他的读、写、事物提交等也没有什么新的东西。性能测试等可以参见Paper。
最后来一张基于ELB、EC2、VPC等部署大图: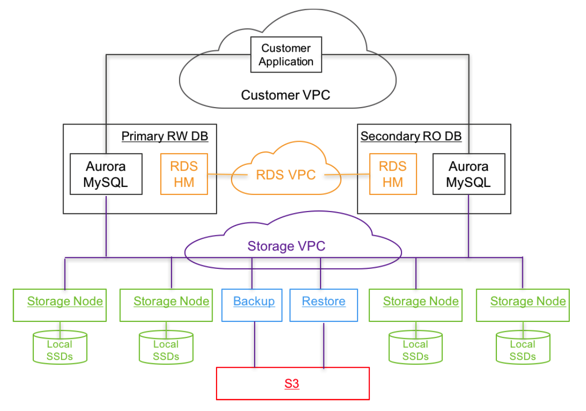
LESSION LEARNED
- 多租户下的数据库诉求:大部分AWS用户都基于AWS开发SaaS化的软件给用户提供服务,在Aroura上市后发现大部分用户对多租户下的诉求是希望能够提供弹性扩展的数据库(数据库Schema一般会不变),而不是像之前认为的,在datamodel这个层面来进行多用户层的统一(例如salesforce)。非常多的用户在一个小的数据库层李拥有十几万的表(看起来SQL这种编程模式已经根深蒂固),他们的诉求主要在于:
- 数据库能够提供足够多的并发
- 数据库的模型能够保留一致,但对于数据库的请求和访问能够按量进行付费(原因是上线前并不能预估具体容量,这点也是例如弹性扩展dynamoDB在AWS如此受到欢迎的原因)
- 能够在一个数据库下,不因为某些表的访问脉冲,引起其他表
- 对于高并发提供弹性的扩容能力:这个搞互联网的都应该知道
- Schema转换能力,因业务需求经常需要做数据表DDL变更
-
高可用性,以及升级能力:6 副本,单AZ内数据节点轮转升级,这点毫不费力
产品与售卖形态分析
最后我们来看看Aurora定价形态:
数据库的计算实例
和AWS RDS的方式类似,本质上是直接购买EC2的节点。在创建计算实例节点后,可以将资源扩展到 32 vCPU 和 244 GiB 内存更大的实例。也可以选择按量付费模式。
存储进行计费
最低存储为 10GB(一个最小Segment),最大为64TB(应该是处于SSD最大本地盘的考虑)。因为存储层是以Segment进行管理的,所以可以弹性地从 10GB 自动增长到 64 TB,而不会影响数据库的性能。
每GB存储为0.1$ /Month,这对于单SSD存储而言是一个比较Fair价格,如果是默认6-Copy,则乘以6。
根据IO进行计费
价格为 $0.200 每 100 万个请求,这个费用属于毛利率比较高的。
IO 是由 Aurora 数据库引擎依靠基于 SSD 的虚拟化存储层执行的输入/输出操作。每一个数据库页面读取操作为一个 IO。Aurora 数据库引擎依靠存储层发出读取,以获取不在缓冲缓存中的数据库页面。每个数据库页面为 16KB。
Aurora 目的是消除不必要的 IO 操作,以降低成本,并确保资源可服务于读/写流量。只有将事务日志记录推送到存储层,完成耐久型写入时,才消耗写入 IO。写入 IO 以 4KB 单位计算。例如,1024 字节的事务日志记录计为一个 IO 操作。然而,当事务日志小于 4KB 时,同时写入操作可通过 Aurora 数据库引擎批量进行,以便优化 I/O 消耗。