“工藤邦明先生似乎是个诚实可靠的人。和他结婚,你和美里获得幸福的几率应该比较高。请把我完全忘记,千万不要有罪恶感。因为如果你过得不幸福,我的行为将会完全成为徒劳。”——《嫌疑人X的献身》

看到这里别慌,笔者写这篇文章的目的不是为了想要跟你探讨关于这部电影里的那些哲学命题:
-
拟一个别人无法解答的问题和解开这个问题,何者更困难?
-
自己想出的答案和判断别人的答案,何者更容易?
只是作为一个DBA(逗B啊)随着对接项目的增多,难免会需要给相关的开发解答一些存在共性的数据库问题。所以在笔者的从职生涯里,关于故障处理有一些比较头大的场景:
-
一类是那种你需要参考古老的DSI(Oracle的技术内部文档但很早就停止更新了)去进行推演验证的,抑或使用场景极端,碰上了BUG。
-
还有一类问题就比较尴尬了,比如开发找到你“我也不知道怎么了,感觉环境有问题”。
朋友,你拟问题的时候是不是把我想像成了《嫌疑人X的献身》里的智商爆表的物理学家。生怕线索给多了,问题太简单就给解决了就没意思了,显得我不厉害?

用人话来比喻一下:一个病人得了肾结石,他到医院看病,医生问诊的时候他虽然不用明确的告诉医生他是由于肾结石导致的腰部钝痛,需要肌肉注射20mg黄体酮来扩张、松弛输尿管平滑肌……
他不用清楚这个病的病理,也不用去理解黄体酮的药理。他只需要跟医生描述病情的时候他能够分得清他钝痛的部位是腰,那里不是脑袋,也不是手,不是胳膊不是腿。医生只要再问问他是不是伴有恶心,呕吐的症状。到这线索就明朗了,医生再让他去拍个B超到这基本就能确诊了。当然自己的身体,我们看着他长大(这句话有点怪怪的),所以我们能够分得清胳膊脑袋腿,这些关于生理构造的基本认知能够很大程度的降低我们于医生沟通是有效信息传递的难度。
对于开发人员,但凡你需要将数据落地存储于一个永久介质以便你能复用这些数据,就永远要跟数据库打交道。因此,笔者亦希望通过这篇文章介绍一条SQL的操作执行在Oracle数据库的历程。能够让你能够分得清数据库的“脑袋”“胳膊”“腿”,让你在跟DBA打交道时少走些弯路。
我是谁,我在哪里,我要去哪。人生三大命题,与你的人生一样,一条SQL其实也需要搞懂这三大哲学命题。
先从连接串下手:它决定了你连接的是哪个数据库。不论是IDE工具亦或者是sqlplus直接连接数据库用户名密码之外连接串是必须填写的。
192.xx.xx.1:1521/xxxServ 完整的Oracle连接串就由这3部分组成:
-
目标机器IP地址 192.xx.xx.1
-
监听工作端口(默认是1521,只有少数的Oracle数据库环境会把监听配置在其他端口)
-
Oracle的服务名或(SIDname) xxxServ。当然大部分会通过配置tnsname来简化这个链接串的配置。
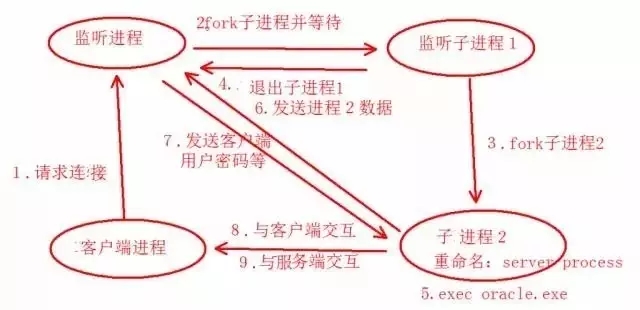
(1)客户端使用SQL Plus或ODBC请求连接,监听接受客户端的TCP连接,并获取客户端发过来的TNS数据包。
这一步容易出的问题有两类:
-
比如客户端的ODBC驱动太老,或者Oracle 的Client没有被正确安装;
-
在网络环境中默认的数据库端口的1521 tcp协议被限制。
常规处理:客户端测试,ODBC测试,Telnet网络端口协议测试。
(2)监听进程打开用于与子进程通信的管道,同时fork一个子进程,称为“监听子进程1”的子进程,然后监听进程一直等待,直到这个“监听子进程1”结束。
(3)监听子进程1 Fork出子进程2。
(4)完成上面一步,子进程1马上退出并结束子进程1。
(5)子进程2收集本进程所在的主机名丶IP地址及进程号等信息,并把子进程2重名成server process(这里我们也把server process叫前台进程或叫服务器进程),申请占用一小块PGA内存。
注:第二到第五步,Oracle已经把这块工作流封装的很好很快了,几乎不会出问题,但是到了第五步这里,可能会由于Oracle的运行参数process限制以及session限制导致亦或者是pga完全耗尽(单个session占的pga内存信息可以通过v$session,v$process_memory,v$process几个性能管理视图查询获取)。当然一般碰上这类问题,会有十分明显的报错,并且报错很直接。
(6)前台进程把主机名丶IP地址及进程号发送给监听进程。
(7)监听进程收到前台进程的信息,并返回客户端的信息(比如用户密码环境变量等)给前台进程。
(8)前台进程查询USER$丶PROFILE$等数据字典,校验用户名密码是否合法,如果用户密码错误就报错用户名密码无效,否则就与客户端进行交互。
(9)客户端收到前台进程的信息与之交互,整个连接创建完成。
以上过程,用理发这个活动来解释一下:

我(Client程序)需要到理发店(DB 数据库)找造型总监Tony老师(建立连接后指定给client的会话资源)理发(数据操作即事务之后以一条update为例),我要完成理发这件事,我需要找到这家理发店(连接串即地址)。
但是我不是这家店的员工(client非DBservevice的后台进程),我需要到门口找到业务员(server端的1521监听,负责监听远程连接client通过他完成与数据库建立连接)。
关于理发这件事我可能会碰上如下情况:
-
这件店地址不对(即连接串无效)
-
我自身不能进这家理发店(Client程序错误或者ODBC驱动太成就有问题)
-
门口接待的业务员没了(监听程序未启动,或DB处于维护状态DBA将监听关闭
-
份验证失效(会员卡密码忘了)
-
这家店太忙了,不论是tony老师还是peter老师都排满了(session或者process达到db的配置允许上限,PGA无法给client连接分配内存)
好了,客户端跟数据库的远程连接已经建立,你可以开始执行SQL了。
◆ ◆ ◆ ◆ ◆
上面我们讲到了用什么样的姿势更好地接入数据库,下面将介绍如何进行操作,上车!
连入数据库,大家一致认为,我跟你数据库交互,你让我数据落盘快,请求快就好了,找到数据落盘不是顺理成章吗?为什么要引入UNDO什么的这些乱起八糟的东西,明显会让响应变慢啊。
为什么一条简单的Update,到Oracle里需要经过下面那么多啰里啰嗦的操作流程,这其实已经是数据库设计人员在这么多年以来得到的一个时间和空间,性能和冗余的最佳“平衡点”。
其实,在计算机科学的1和0的世界里,体系架构无非这几件事:时间换空间,空间换时间,以及性能换冗余,冗余换性能。而这几个基本问题最终都会触及到现在的科学边界,无法逾越。一个特性的优点,背后一定会有其对应的代价付出。
以下文即将提及的UNDO为例,提供一致性读(Consistent Read),回滚事务(Rollback Transaction),实例恢复(Instance Recovery)这些特性因为其存在能够得到很好很高效的支持。
同样是Oracle数据库,如果用来跑一个耗时很长的统计报表,大概需要3个小时。在这个业务场景下你也许接受了时长好像并不是太大的问题,但跟人生很多事情一样,你等得起,不代表就一定会得到结果。UNDO机制的问题碰到了ORA-01555(快照过旧)引发了事务中断,UNDO的机制在这种应用场景下反倒成了累赘。
这里提一下满足三范式的设计,对OLTP事务类型业务能够提供很快的支持,但一些数据仓库以及数据集市的业务,为了获得性能反倒往往是需要反三范式的设计。一般Oracle(exedata等除外)的行数据存储的方式,当需要进行整列的Sum统计等操作时,相比列式存储能够得到的性能也是天差地别。
业务场景千变万化,所以我们就以最简单的一条update 来感受下数据到底在干嘛。
当连接会话完成建立之后,你将一条SQL提交给DB Sever 接下来会发生什么呢?他会来到Oracle的Librarychache:
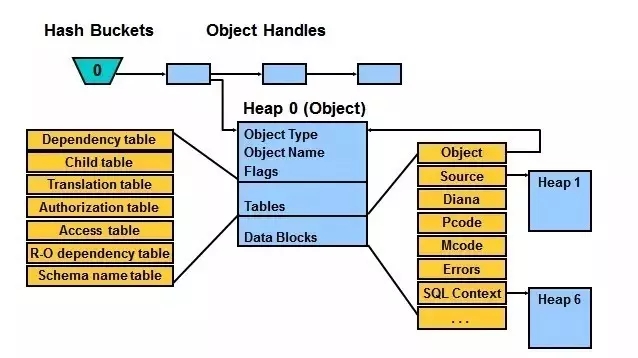
(来自DSI405的Library cache 示意图)
Oracle的内存体系结构最复杂的就是sharedpool,而shared pool中最复杂就是library cache,出于文章目的及篇幅所限,就不再继续做详细展开,简单讲讲sql在里面的运作流程。
第一会将SQL(update t_test set name='wahaha' where id=1)的每个字符当然包括空格转化成ASCII码后,再拿这一堆ASCII码通过HASH函数生成一个sql_hash值,Oracle拿着这个sql_hash值去描扫HASH Buckets(看上面的图,这个幅画的不太好,只画了0号的HASH BUCKETS),假如刚好sql_hash值=0,那么Oracle就延着0号HASH Buckets去搜索Object Handle链,在这个Object Handle上存有sql的文本,如果和我们的update t_test set
name='wahaha' where id=1一模一样对上,那就说明这条SQL已被缓存在共享池了,这个过程就是软解析,最后执行计划是被存放在heap 6中。
如果通过上面的方式在Object Handle链没搜索到这条SQL的文本,则说明SQL不在共享池中,这个时侯就要做硬解析(过程大要做语法,语义,权限,查询视图展开丶划分小的查询块丶SQL等价转换丶代价估算丶最后生成执行计划),这个代价会有点高,如果有大量的硬解析那会消耗CPU和占用共享池。
人话版本:我的数据库接收到你的一条SQL,每天执行的SQL那么多,我也没记住你是不是最近执行过了。我到SGA的library cache缓存里找找,看看还有没有你上一次的SQL信息。当然我们的library cache呢 使用的是lru(最近最少使用淘汰算法)。如果SQL是经常执行的,肯定能找到你的缓存的。
但是如果SQL执行的次数较少,那么很大概率在事务量繁忙的数据库。哪怕执行了没多久仍然有可能被 lru淘汰掉。所以如果SQL不在,就需要消耗一定的Cpu以及内存资源来完成SQL语句的解析才生成并存放SQL的执行计划。在SGA配置的较小但是有大量SQL解析的DB环境中,极有可能碰上library cache不足以及大量的硬解析并发导致CPU的使用率飙升的情况。
更极端一点的,在一个并发很大的Oracle线上生产系统,在业务繁忙的阶段进行权限的revoke操作,也会导致这个表的相关SQL会被 aged out,引发解析风暴。同样的,在你删除或变更一张核心表的索引的时候,虽然最主要的风险还是执行计划的变更导致SQL执行率下降进而导致CPU内存被占用。但是哪怕索引删除变更后SQL执行效率没有太大波动,但是shared_pool 中的与这个表相关的sql 都会被aged out,必须重新分析,这个带的风险在并发压力大的数据库系统中也要被考虑进去。
我们再往下看的话涉及到就是Oracle数据库是如何UNDO,和Redo在保障ACID的事务特性下,尽可能的把并发以及执行效率提升的原理(以UPDATE为例),涉及专有名词太多,笔者说人话也不好解释。 ╮(╯▽╰)╭
1、如果ID列上无索引
-
查询SEG$等数据字典,找到test表段头
-
从段头读出Extent Map,开始全扫描
-
找到第一个满足条件的行,进行修改
-
查找同一块中剩下的行,先构造一个CR块,在CR块中继续查找,如果又找到满足条件的行,在Xcur块中修改
2、如果ID列上有索引,且版本不是11GR1(10G丶11GR2),则不需要构造CR块
通过索引找到目标数据块。
3、ID列无论是否有索引,在11GR1下都需要构造CR块
4、如果NAME列上有索引,增加索引维护步骤:
-
先在原索引块中删除要修改的原值
-
再将新值插入
5、任何块的修改,都有以下步骤(非IMU)
-
在PGA中生成UNDO段头事务表的后映像(5.2)
-
在PGA中生成UNDO块的后映像(5.1)
-
在PGA中生成DataBlock块的后映像(11.9)
-
将前三个Redo矢量做为一条Redo Recorder写入Log buffer
-
修改UNDO段头的事务表,事务正式开始。
-
修改UNDO块,写入DataBlock的前映像。
-
修改DataBlock,将新值“wahaha”写入Buffer cache
6、任何块的修改,都有以下步骤(IMU)
-
在PGA中生成DataBlock块的后映像(11.9)
-
在PGA中生成UNDO段头事务表的后映像(5.2)
-
在PGA中生成UNDO块的后映像(5.1)
-
将前三个Redo矢量做为一条Redo Recorder写入Shared pool中的Private strand
-
将DataBlock中的前映像值,写入Shared pool中的Imu pool
-
修改UNDO段头的事务表
-
修改UNDO块,写入DataBlock的前映像
-
修改DataBlock,将新值“wahaha”写入Buffer cache
1、非IMU下(按最常见的快速提交):
-
在PGA中生成Commit的Redo 信息(编号5.4),另做为一条Redo recorder,写入Log buffer
-
修改事务表相应Slot,声明事务已提交
-
修改DataBlock,在ITL Slot中写入快速提交标志和SCN。每行上的行锁不清0
-
通知Lgwr,将Log buffer写入Redo file
-
收到Lgwr通知,写入完成
-
向用户发收提交完成信息
2、IMU下(按最常见的快速提交)
-
在PGA中生成Commit的Redo 信息(编号5.4),传入Shared pool中的Private strand,追加在事务之前的Redo recorder之后
-
修改事务表相应Slot,声明事务已提交
-
修改DataBlock,在ITL Slot中写入快速提交标志和SCN。每行上的行锁不清0
-
将Private Strand中的Redo数据写入Log buffer
-
通知Lgwr,将Log buffer写入Redo file
-
收到Lgwr通知,写入完成
-
向用户发收提交完成信息
断开连接,中止服务器进程,释放PGA。
补充一下,任何不结合业务场景,一味鼓吹XX技术是最好的技术的人,大部分情况下并不是因为他们是傻子,他们只是把你当傻子。而且洗脑的发生,有时候是静悄悄的。
至此你的一条UPDATE 完成了他与数据库交互的一生。
作者介绍 崔霄
-
目前就职于点融网infra团队,DBA一枚。喜欢徒步、开车。
-
原文发布时间为:2016-12-28
本文来自云栖社区合作伙伴DBAplus

