冯媛:
-
IBM资深软件工程师
-
2005年至今一直从事DB2相关工具开发,包括IBM Data Studio Admin Console, InfoSphere Optim Performance Manager,Data Studio等
-
专注于数据管理,监控和性能优化。目前带领团队开发Data Server Manager 管理和配置部件,曾在北京交通大学,深圳大学,哈尔滨大学等多所高校及各种高校老师的培训课程中介绍DB2知识
-
参与《DB2性能管理与实战》写作并在developerWorks发表多篇文章
演讲实录
IBM在DB2 10.5版本中推出了BLU Accelerator,IBM对于列存储的支持晚于TeraData,Sybase等数据库厂商。BLU Acceleration作为IBM全球数百位顶尖研究人员智慧结晶,BLU具有内存列式动态处理、可操作的压缩数据、并行向量处理、以及数据忽略等行业独有的特性。今天我这里和大家一起分享一下DB2做的这些优化。
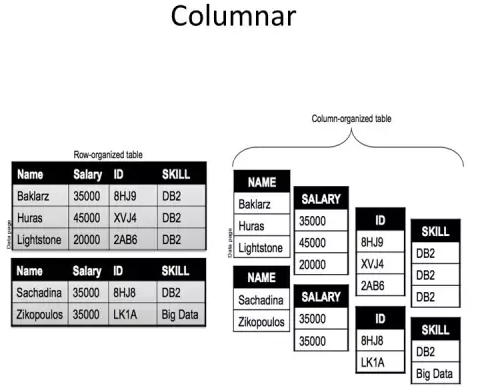
列存储最大的特点是数据是按列存储的,比较适合OLAP应用中获取一部分列的场景。 在行存储的时候,数据页里存有整行的数据,当我们需要查询局部列的时候,必然的我们会把对应的行所在的页都加载进来,想象一下数据库在读的时候我们都知道bufferpool会顺序预取后面的几页,对于一个有很多行的表,取局部列数据的时候实际上会带来非常多的额外IO开销。举个比较极端的场景100列的表中取1列的情况,如果没有索引在这一列上,IO中只有1%的数据才是我们需要的。
那么既然BLU的数据都是以单列存储的,又怎么能保证对于数据多列的读取的呢。 DB2将一组列组成的单元给了一个唯一的序列号叫TSN, 由TSNList组成了一个逻辑的行。每个页有一个TSN map。所以行表里的RID()这些方法在列表里是不支持的。对于取局部列数据的应用,比如之前100列中读取1列,这里只要把列所在的数据页加载过来就行,不需要加在其他无关列的数据。
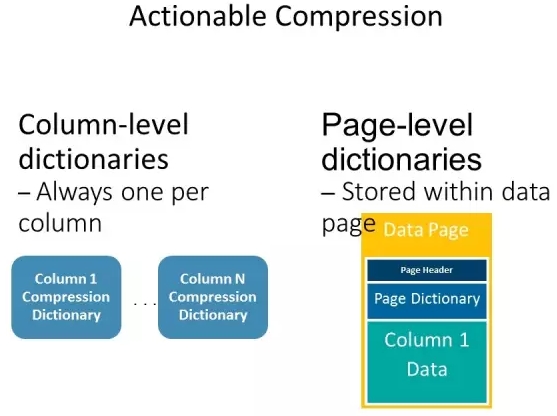
DB2在BLU的压缩中不仅有列级别的压缩,而且在页级别的字典会再进一步压缩。
当数据被Load的时候,当你使用LOAD REPLACE, LOAD REPLACE RESETDICTIONARY, LOAD REPLACE RESETDICTIONARYONLY或者LOAD INSERT的时候,列级别的压缩字典就会被创建。当新的数据被加入的时候,数据会用表级别的压缩字典进行压缩。BLU还会用页级别的压缩字典来压缩新的时候。这种两层的数据压缩字典,提高了数据的压缩效率。页级别的压缩字典就存在于每个数据页中。每个数据页包含了该页的起始TSN以及总共有多少个TSN。

BLU采用了压缩包括了近似的霍夫曼编码、前缀编码和差值压缩。对于出现频率高的值压缩后会用比较少的bit来表示,而且在一个区块内是保序的。结合页级别的压缩,有可能根据列级别的压缩成为3 bits的,在当前页里面出现频率比较高有可能就会压缩成2 bits. 这种压缩算法大大提高了压缩效率,减少了存储和I/O开销。数据页里保存了当前页的压缩字典。
在进行查询的时候,查询条件的值也是通过压缩算法后在每个单元中比较的,而不是把数据解压后进行比较,只有满足条件的值才会被过滤出来,在中间运算过程中尽可能的用压缩值。
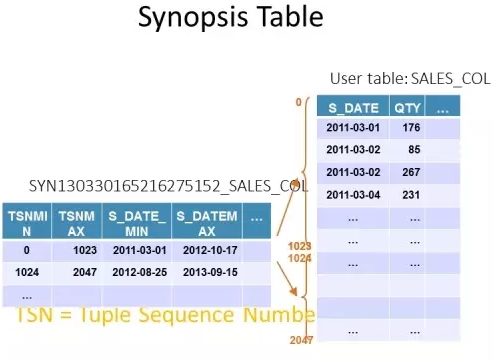
DB2自动维护了一个page map index和一个Synopsis表,page map index存放了列组合的起始TSN以及对应的页地址。Synopsis表含的是每个非字母列的最大,最小值组合。
在数据Load和insert的时候,DB2会自动在Synopsis表中生成记录,Synopsis表里包含了MinTSN、MaxTSN以及列的最大和最小值。
Synopsis表能帮助在查询的时候根据查询条件跳过一些TSN。在Load的时候每1024TSN就会插入一条记录在概要表里,每一次插入事务也会单独生成一条记录。DB2 BLU比较适合大批量的数据插入,比如Load、ingest等,不适合单个insert操作,性能相对会慢一些。

我们在刚才看概要表的时候,已经讲到概要表里的最大,最小值能帮助在查询的时候跳过不需要的数据。
比如列之间的谓词条件的查询:
x1 > x2 ==> maxx1 > minx2
x1 >= x2 ==> maxx1 >= minx2
再比如单列IN
col IN (val1, val2, ...) ==> (mincol <= val1 AND maxcol >= val1)
OR (mincol <= val2 AND maxcol >= val2) OR ...
DB2 BLU 会自动动态更新数据页里面的值范围,这样在查询的时候不满足条件的值会自动被忽略。
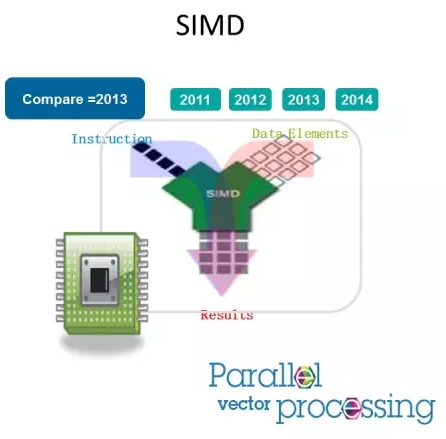
BLU使用了单指令多数据流(SIMD)技术
单指令多数据流(SIMD)是指能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。
这里的例子,我们做一个= 运算,可以同时把4个值同时给CPU去处理,这对于谓词处理,Join, group以及数学运算等都能大大提高效率
DB2能把128 bits 给SIMD,因为数据的高度压缩,并且是频率越高压缩率越高,这样能大大提高CPU的运算效率。
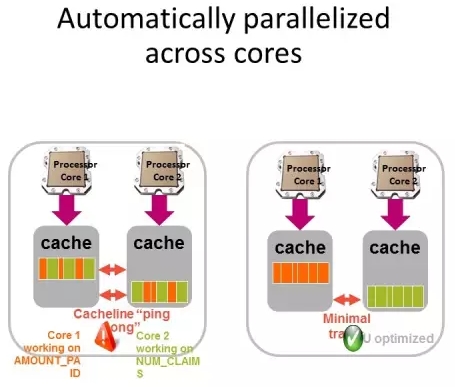
自动分布到多个CPU core
BLU默认要打开INTRA_PARALLEL, BLU结合workload manager,尽可能得使用CPU的core,我们都知道L1的cache效率是最高的。
在左图中,没有用BLU技术的时候,AMOUNT_PAID里的数据一部分在core1,一部分在core2中,所以core1在处理的时候还要从core2中获取数据。core2工作在NUM_CLAIMS列上,但是它也要从core1上获取数据。 所以就存在core之间争取数据的“乒乓”操作。
在采用BLU以后,列存储以后,AMOUNT_PAID的处理都在core1上,NUM_CLAIMS列的处理都在core2上,所以两个核之间不用交换数据。而且能更好的保证core里面的cache被更好的利用。
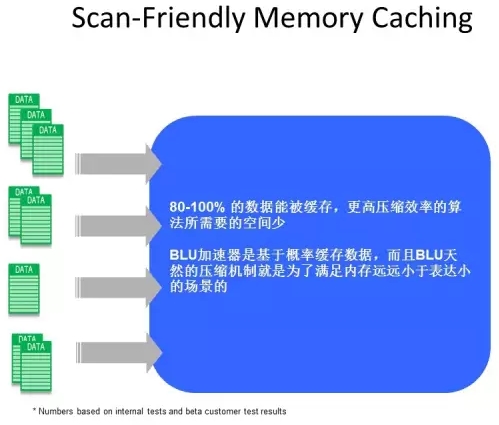
概率缓存取代传统LRU
如何有效地缓存数据一直是一个非常困难的问题,因为数据远远大于缓存的大小。采用什么样的算法是很关键的问题,传统的采用保留最近使用(MRU),换出最久未使用数据(LRU)并不适合分析性数据。 大部分的分析数据,有一部分数据会比其他部分的数据热,用传统的行存储的方式,一是由于需要的对于所需要数据的内存,二是当内存不够时,数据库cleaner采用LRU释放出内存的数据很可能是下一个scan的时候要用的数据,会大大增加IO的开销。
DB2 BLU一方面由于采用列存储和在运算过程中保存压缩,大量减少了所需要的内存,所以实际70,80%所需要的数据可以被内存容纳着,另一方面BLU本身的数据就是基于使用频率压缩的,所以DB2会尽可能把使用概率高的数据缓存在内存中,尽可能的提高缓存的使用效率。
对于OLTP系统,DB2对于行存储继续使用LRU,对于列存储,DB2会自动切换的概率缓存。对于用户来说这些都是透明的,不需要去管理。

使用BLU以后,因为使用列存储,所以用户不需要再建Indexes,也不需要MDC。
此外很多操作DB2默认都会做,所以不需要用户手动去Run REORG,RUNSTATS,不需要统计信息表,也不需要optimizer hints。大大简化了数据库管理工作,用户只需要把数据用Load倒入到BLU DB中,用db2set DB2_WORKLOAD=ANALYTICS , 就会打开很多自动处理,比如自动的WLM,自动的space回收,自动的数据页分析,内存优化等等。
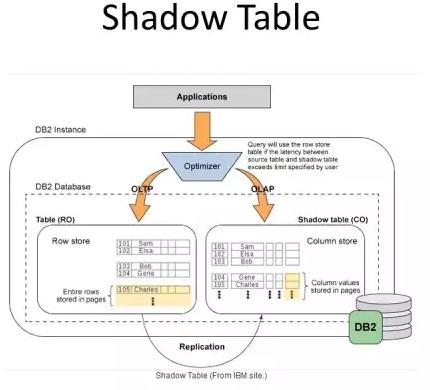
此外DB2还提供了Shadow Table,使用CDC工具,把OLTP中的一个行表定期复制到一个对应的分析用的列表中。
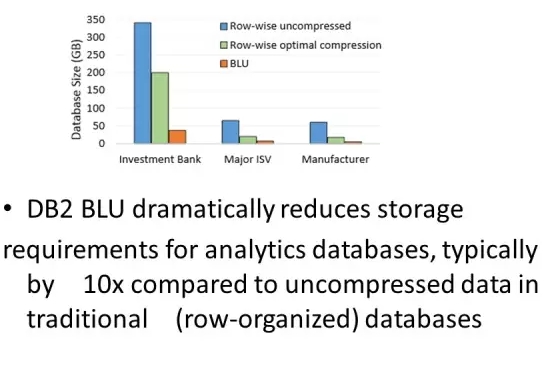
最后,虽然DB2在列存储上起步比较晚,但是它采取的一些方法都是比较先进的方式,BLU适用大部分OLAP应用,根据统计大部分情况下,DB2 BLU能提高10倍作哟的存储使用效率相对于没有压缩的行表来说。对于一些workload能提高6-124倍的效率。
Q & A
Q1:db2 dpf BLU 什么时候GA?
A1:很快了,在BLU mix上已经支持MPP了,可以去适用一下bluemix上的dashdb。
Q2:Blu CPU Core 技术有硬件要求吗?
A2:现在power和x86(Intel AMD)都没问题。
Q3:BLU对sort group by 这里的聚集计算,性能怎么样?
A3:BLU在对query支持的时候,都先分解为单表的谓词条件,单表都是压缩处理的。压缩不但是按频率编码,而且编码是排序的。BLU确实是会尽可能的使用内存,压缩的时候采用频率,区块内保序的方式。所以很多无效的数据会被忽略,也大大提高了排序和比较运算的开销。
Q4:BLU在目前行业领域应用怎么样?用过太耗内存资源,而且是单机,并发并不是很理想。
A4:要看和谁比,比Oracle12c的in memory option要好多了。
Q5:是不是对于“男女”这种字段列压缩会很好,要是像UUID这种字段压缩效果怎么样?
A5:BLU适合OLAP应用,也适用OLTAP。用shadow table 同时保有行表和列表,随机数肯定没有出现频率高的压缩效率高。
Q6:BLU列式存储的表,可以和传统行式存储的表,在数据库内共存吗?
A6:可以。
Q7:字符集是不是只能utf8的才可以用BLU?
A7:BLU目前只支持UTF-8,collate为16-bit identity的database。
Q8:现在离线计算大家都在做,老师们你们认为BLU目前最大的优势是什么,对于hadoop、greenplum、TD,而言将来的DPF BLU最大的亮点是什么?
A8:又快又省空间。BLU在整个运算过程中尽可能得不解压运算,比很多数据库的实现省内存和提高了运算效率,谓词也是同样压缩算法直接和压缩后的值计算,尽量在单表条件过滤后,以最少结果集多表间join,但在join的时候会出现需要解压运算,也会有溢出写磁盘的情况。一般压缩这个事情是你压缩了,你回头还得解压,用时间换空间。所以一般是小了,但是会慢。但是BLU的处理不是解压column,而是去压缩谓词之后你需要比较的值,只需要比压缩之后的结果就行了。还有一点..就是BLU的压缩不但能按频率,还能压缩之后保持顺序,所以对于>,<,Between..and..这样的谓词也能做,在join不得不解压的一些场景中,DB2尽量单表中保持压缩的情况下运算完成后,将满足条件的最小集合做表间join,这样还是比很多数据库的实现节省了解压带来的损耗。马远提到的压缩保序在谓词运算中在保持数据压缩情况时运算很关键。
Q9:BLU推荐的配置是什么?
A9:BLU推荐的核数和内存: 16 Cores for every 3TB Raw (uncompressed) Data, 16 GB of Main Memory per Core。
Q10:版本优化器做了加强了吗?针对于BLU设计了特殊的成本计算规则吧?
A10:会单独走CTQ的执行计划。
Q11:那执行器有更改吗?
A11:data skipping是执行器做的,在比较的时候根据是否落到某些区域,直接跳过一些数据区块,还有db2记录了概要表,概要表也会记录一些列的最大,最小值,db2基本上在你插入数据的时候就时时更新统计了。
Q12:db2 BLU 概要表与db2概要表是不同概念吗?
A12:不一样,db2 BLU 概要表是指synopsis table。




