
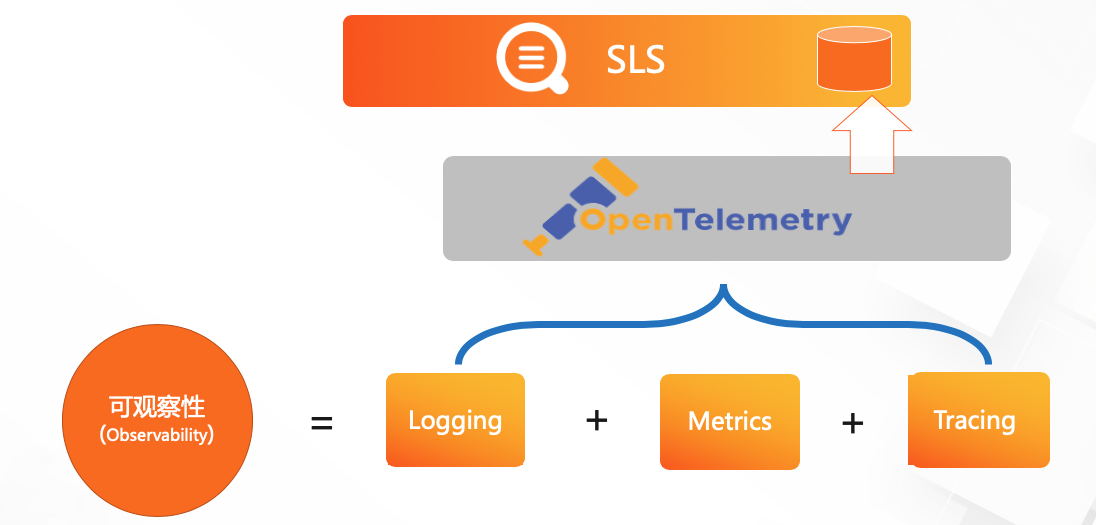
可观察性与Open Telemetry
在CNCF的landscape上,有专门的一个部分来展示Obserability and Analysis,什么是Observability(可观察性)? 我从OpenTelementry官网摘抄了这段描述:
可观察性包括Logging,Metrics,Tracing这三类紧密配合的数据源:metrics可以用来发现问题,利用相关的trace去找到异常节点,再看该异常节点的日志去定位根因。
很多人可能会觉得可观察性就是“旧瓶装新酒”,本质上没有任何的创新。从现实中(包括Landscape)不难理解这个说法,目前Logging,Metrics(Monitoring),Tracing都有各自的生态。实现上大家有各自的数据模型,模型中可能有也可能没有考虑和其他数据的联动,如果想要对数据做整合,就要各自做大量的适配工作。
为了解决这个问题,OpenTelementry诞生了。OpenTelementry从OpenTracing和OpenCensus合并而来,致力于可观察性的统一,他的重点在规范的制定,sdk的实现,采集系统的实现上,让大家都以一致的数据模型来产出数据.
对于数据如何存储如何使用,这个范畴太大,有非常多可能性,所以仍然需要上层产品去探索。
SLS 对Open Telemetry支撑
SLS在不断跟进OpenTelementry和可观察性的发展,最近(2020年4月)我们推出时序存储引擎,在之上支持了当今最流行的监控系统Prometheus协议
OpenTelementry统一了数据的模型和采集,SLS目前支撑了阿里集团内主要的logging,tracing场景,新推出的metrics存储可以用来支撑时序的模型,这样我们也就完全支持了OpenTelementry三种数据的存储,因此下一步需要考虑的重点就是数据使用与应用的统一。
使用数据可能有很多方面,比如查询,告警,可视化等等,其中查询是基础,所以我们先来看看几种数据类型的特性,他们在查询体验上是否有可能统一。
可观察性数据模型
针对历史上已经独立发展N多年的三种数据模型而言,提供一种统一分析语言是一件很有难度的事情,因为大家都已经习惯用不同的工具和系统来解决不同的问题。首先我们用一个图来分析下他们之间的关系:
图中表示从一种数据出发,可以转换成另一种数据:
- Log -> Metrics: Log通过过滤,聚合变成Metrics
- Metric -> Trace: 当Metrics提示异常时,根据metric本身或者它的tag信息去查找相关trace
- Trace -> Log: 通过Trace定位到异常应用的某个Service,然后查找该Service的日志
- Log -> Trace: Trace可以以log的形式表示,通过traceid去查找
- Trace -> Metrics:trace数据可以通过聚合,转换成Metric
- Metric->Log: 同trace,通过metric携带的信息去Search相关的日志
举个栗子
Log -> Metrics
假设我们现在有个应用叫buy,这个应用提供了一个RPC服务: buy.createOrder 于是我们要对其进行监控,我们可能需要他的qps,rt,成功率,处理完每个请求我们都打印这样的一行日志:
2020-06-07 19:39:54 service=createOrder,type=prodver,success=true,cost=35ms通过统计总行数我们得到了qps,统计success的行数/总行数我们得到了成功率,对cost求平均,我们得到了平均rt,这就是 Log->Metrics ,用SQL表达是:
SELECT count(*) as totalRequest,count_if(success='true') as successCount,avg(cost) as rt FROM log GROUP BY serviceTrace -> Log
随着业务变复杂,createOrder这个服务也调了很多其他应用的服务,链路变长了,很难确定是里面的哪个应用出了问题,于是我们引入了trace,上面的日志可能变成这样:2020-06-07 19:39:54 service=createOrder,type=prodver,success=true,cost=35ms,`traceId=0b5900e015915297642246871d5945`
当buy调用别人的服务时,会将traceId传递下去,所以整个流程中所有执行过的方法都会打印一行带相同traceid的日志,当发现异常时,我们就用traceid作为关键字去查询(Search)相关的所有日志,这下我们定位问题就要方便多了
Metrcs <-> Log <-> Trace
积累了一些排查问题的经验以后,我们发现常见的问题大致是可以归类的,所以我们把已知的问题都归类成错误码,也加入到日志中,同时因为我们处理ios和Android用户走的链路不同,因此我们加入了一个用户来源字段:2020-06-07 19:39:54 service=createOrder,type=prodver,success=true,cost=35ms,`traceId=0b5900e015915297642246871d5945errCode=BANK_PAY_ERROR,source=ios`
增加一个监控项,统计各种errCode出现的次数:
SELECT service,errCode,count(*) as count FROM log GROUP BY service,errCode这下出现异常时,我们还可以看到 BANK_PAY_ERROR 这个错误码比平常变多了,这个错误码意思是调用银行支付接口出错了,但下游依赖的错误会导致上游报错,我们暂时还不知道是下游的具体哪个环节出错了,这时候要先去看看trace,用traceId作为关键字去搜索,但是错误太多,单个的trace很难反应整体状况,这怎么办?我们先通过其他信息来缩小范围,比如再统计一下ios和Android来源的订单是否有区别:
SELECT service,errCode,source,count(*) as count FROM log GROUP BY service,errCode,source发现出错的订单全部是来自ios的!这时候我们再挑几个trace,看到都是pay这个应用的pay.callCCB接口出错,也就是调建行支付接口报错了,接着再通过traceId去查找(Search)异常日志,发现抛了NullPointerException,原来是有人改了代码,没有做好校验,抛空指针了,这下问题彻底排查清楚了。
这个例子并非虚构的,我们集团内大量的业务都是用类似的流程排查问题,在这个例子中我们可以看到,metrics,log,trace确实有着很强的关联关系,我们用了SQL和关键字查询配合来解决问题,实际上关键字查询语法是SQL的子集,只是因为他使用上更简单一些,所以现在是两者共存的,未来也有可能会统一。
单看这个例子,感觉不管是log还是trace还是metrics,用SQL查询应该都还是比较直观的?在现实世界中,log和trace都能比较好的用SQL查询,但metrics却常常不是。
Metrics数据特征
metrics产生的数据就是时序数据(TimeSeries),时序数据有着固定的schema:
| time | metric | tags | value1 | value2 |
|---|---|---|---|---|
| 2020-06-04 11:15:05 | service.latency | {"name":"servicea","ip":"1.1.1.1"} | 1234 |
其中像prometheus,opentsdb只有一个value,influxdb支持多个field value,本质上没有差别.
固定的schema使得他在存储上可以做更多优化,例如time和value可以采用XOR算法进行压缩,可以将同一个metric的数据连续存储提高读效率等等,这方面的资料很多,不赘述。时序数据量也很大,且写多读少,能用尽量低的成本来存储非常重要,也因此时序数据一般会独立于logging和tracing,使用特定的存储结构和压缩算法,这也是市面上会有这么多tsdb的原因。
部分时序数据库或监控服务,以及对应的查询语言
| tsdb or monitor service | 查询语言 |
|---|---|
| Opentsdb | json api |
| Influxdb | influxql |
| Promtheus | PromQL |
| Graphite | DSL |
| New Relic | NRQL |
我们可以看到,这些tsdb都用了自定义的DSL而没有用标准SQL,是为什么呢?
metrics常常有类型,如conter/guage/histogram/quantile等,针对不同的数据类型,需要使用不同的聚合方式,比如conter类型是不断累加的,使用的时候就常常要用rate去获取两个数据点的delta; 对于quantile数据需要对不同的bucket做聚合; 非常依赖对时间的处理,比如对5分钟的数据做聚合,查询最近N分钟的数据
一旦涉及到此类计算,SQL就有点力不从心了,比如以下这个巨复杂的SQL,映射成PromQL只是短短一行:
select id,
temp,
avg(temp) over (partition by group_nr order by time_read) as rolling_avg
from (
select id,
temp,
time_read,
interval_group,
id - row_number() over (partition by interval_group order by time_read) as group_nr
from (
select id,
time_read,
timestamp + 900 * (time_read / 900) as interval_group,
temp
from seriesname
) t1
) t2
order by time_read;PromQL:
avg_over_time(seriesname[15m])
PromQL确实简单很多,对比其他几种查询语言,他功能也最丰富(https://www.robustperception.io/translating-between-monitoring-languages),同时prometheus也是这里面最热门的开源项目,所以我们把它作为时序查询语言的标杆来做一些对比。
查询DSL,PromQL,SQL的能力如下所示:
标准SQL涵盖了搜索DSL的功能,和PromQL的部分功能有重叠,PromQL对时序数据的处理上则比标准SQL有些优势,但别忘了,SQL是可以拓展的,几乎任何支持SQL的查询引擎都支持UDF,通过拓展一些函数,我们完全可以实现promql的功能,只是表达上可能没法做到那么简洁。
还是上面的例子,我们尝试做一些简化: 实现一个exponential_moving_average 聚合函数:
CREATE OR REPLACE FUNCTION exponential_moving_average_sfunc
(state numeric, next_value numeric, alpha numeric)
RETURNS numeric LANGUAGE SQL AS
$$
SELECT
CASE
WHEN state IS NULL THEN next_value
ELSE alpha * next_value + (1-alpha) * state
END
$$;
CREATE AGGREGATE exponential_moving_average(numeric, numeric)
(sfunc = exponential_moving_average_sfunc, stype = numeric);这个函数是PostgreSQL的,在支持UDF的其他查询引擎中,可以替换成等价的实现
然后SQL就可以改写成这样:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM telegraph
WHERE measurement = 'seriesname' and time > now() - '1 hour';这样是不是就简单多了? 至少在某些场景下,SQL经过一定的优化还是有可能比较简单的来处理时序数据的。而且同时SQL也有其他的优势:
- SQL是有标准的,也是会的人最多的语言,意味着用户掌握的SQL技能可以重用,PromQL虽然并不算很复杂,但也是有学习上手的成本的
- SQL更灵活强大,比如PromQL只支持返回一个metric的值,或多个metric经过计算后的单个值,不支持同时查询多个metric,SQL可以做到
- SQL拥有更多的可拓展性,几乎任何支持SQL的大数据引擎,都会提供UDF的支持
融合: SLS统一查询引擎
既然对于metrics的数据用SQL还是用DSL我们有所纠结,那么我们何不同时支持他们? 经过调研,这也确实是可行的。SLS针对时序数据给出的方案是提供三种模式,整体上以SQL为主,辅助让SQL支持调用PromQL使简化的语法和强大的功能可以兼得;同时也支持直接调用PromQL,以支持开源生态,例如被grafana集成。
拓展后的SQL引擎如下图所示:
SLS 拓展SQL引擎完全覆盖了Search DSL,PromQL的所有能力,并且额外补充了时序分析函数,机器学习函数,安全分析函数等来支持AIOps场景,我们后续还将引入CMDB等meta数据,借助Presto强大的多数据源接入能力,各种数据之间可以join,从而完成更复杂的数据分析,比如根因定位。
纯PromQL查询
在实现metrics store的时候,我们就支持了prometheus remote write协议写入,也支持调用prometheus api用PromQL查询,这样也可以直接作为grafana的数据源以兼容开源生态
如果用户的数据是prometheus写入的,那这是最合适的
纯SQL查询
因为metrics store本身复用了sls的底层架构,因此他天生就是可以用SQL去查询的,比如上面长长的SQL就是用纯SQL查询的,纯SQL查询还需要做很多优化,才能比较轻松的处理时序数据,这需要长时间的投入,所以我们还有第三种方案:
SQL+PromQL混合查询
我们把PromQL封装成几个函数,并可以将其作为子查询,支持在外层嵌套完整的SQL,举个栗子:
纯PromQL查询:
SELECT promql_query('up') FROM metrics
SELECT promql_query_range('up', '1m') FROM metrics
执行返回固定的表结构,和prometheus的schema对应:
| time | metric | labels | value |
|---|---|---|---|
| 1590553376000 | up | {"label1": "value1","label2":"value2"} | 1.0 |
PromQL作为子查询:
SELECT sum(value) FROM (SELECT promql_query('up') FROM metrics)
PromQL作为子查询,复杂SQL:
select ts_predicate_arma(time, value, 5, 1, 1 , 1, 1, true) from ( SELECT (time/1000) as time, value from ( select promql_query_range('1 - avg(irate(node_cpu_seconds_total{instance=~".*",mode="idle"}[10m]))', '10m') as t from metrics ) order by time asc ) limit 10000
目前支持了PromQL中最常用的API: query(varchar),query_range(varchar,varchar?),labels(),label_values(varchar),series(varchar)
其中query_range不填第二个参数时也支持自动的step,规则同grafana
技术方案
三种实现
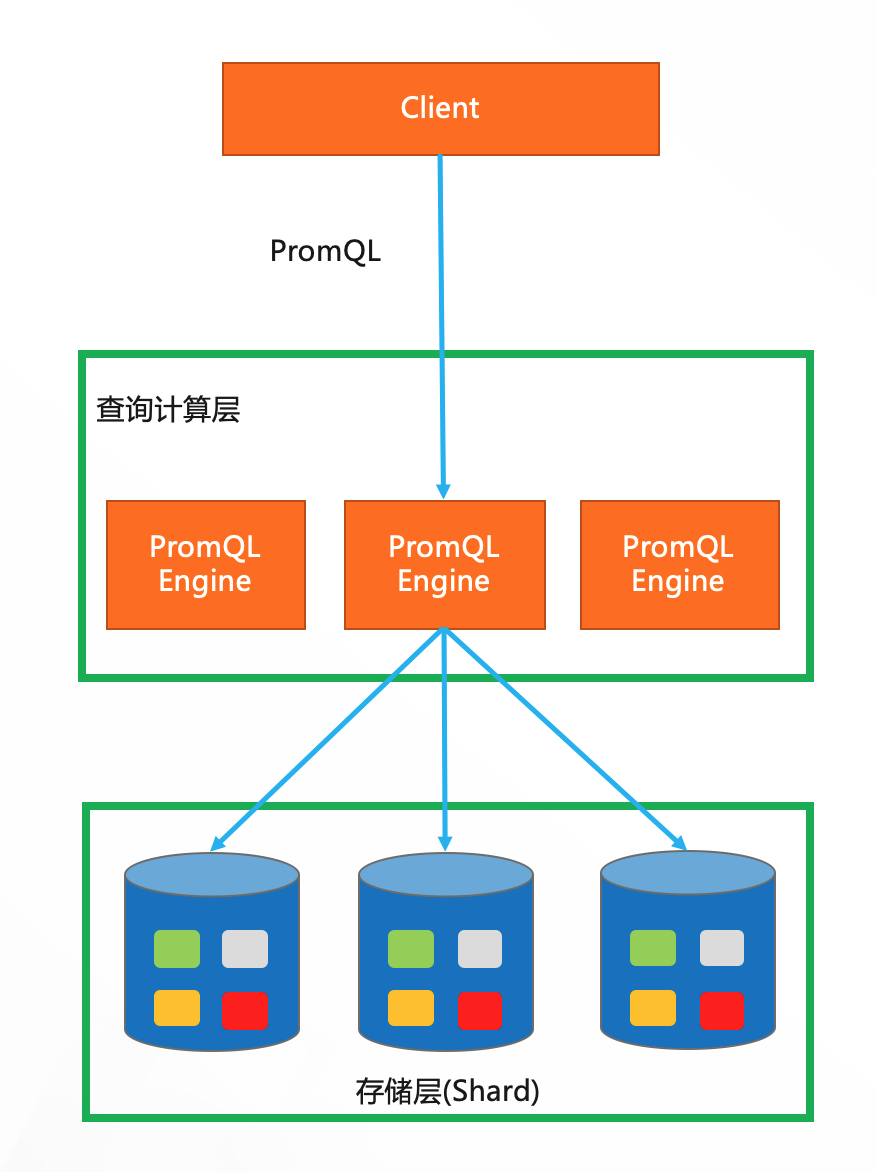
纯PromQL查询: 只是走PromQL Engine,实现了一定程度的下推,比如数据的过滤,但
对于聚合来说,仍然需要把数据全部汇总到PromQL Engine才行,和SQL Engine相比,他无法分布式执行,也因为少走了SQL Engine,没有了plan和任务分配等过程,减少了这部分开销,因此对于数据量较小查询频繁的场景延迟会更低,能支持的QPS更高
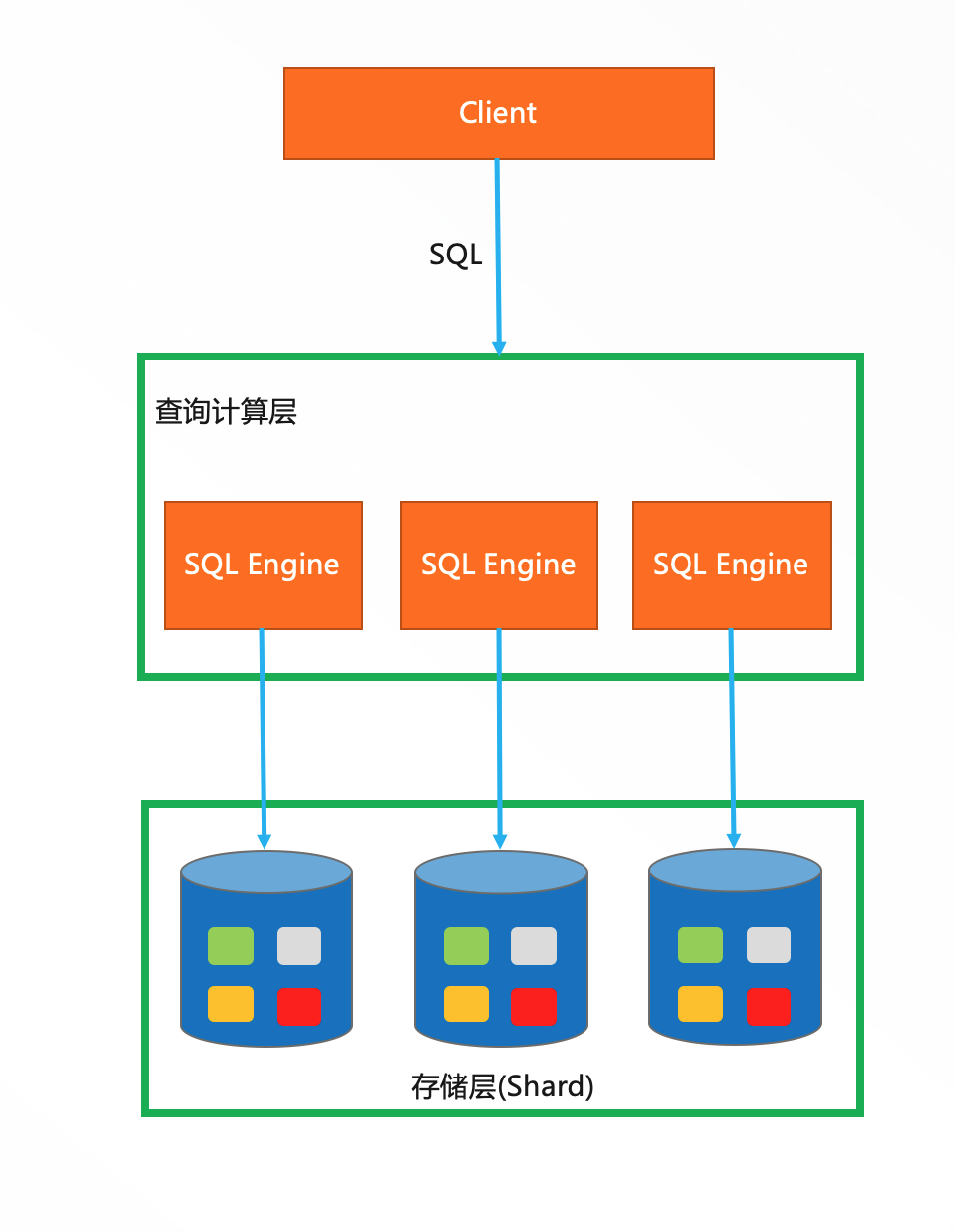
纯SQL查询: 走SQL Engine,会由查询层统一调度并分配到每个shard上去并行执行,可以通过扩充shard个数来加速查询,对于数据量非常大的场景有优势
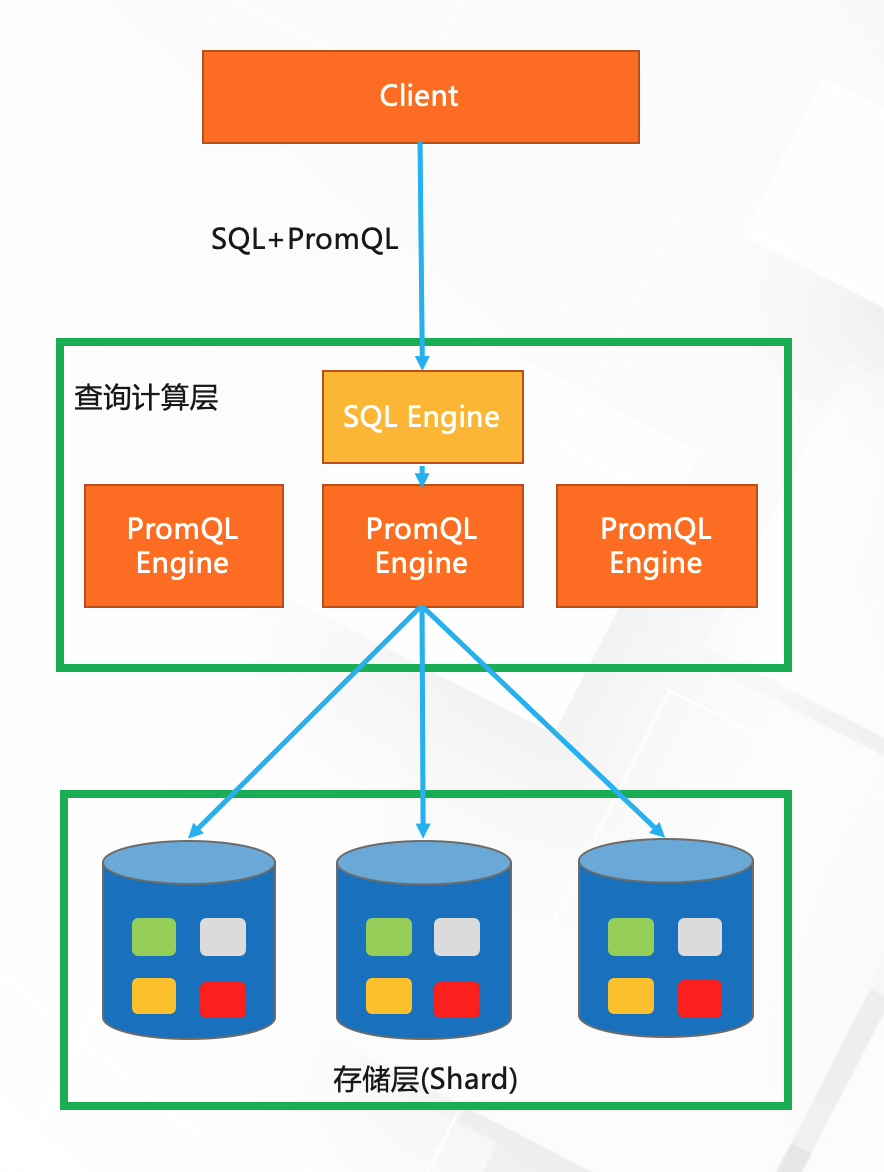
SQL+PromQL混合查询,这种情况就比较复杂,同时走了SQL Engine和PromQL Engine,
PromQL子查询部分会被PromQL Engine执行,执行的结果会汇总到SQL Engine执行,性能上对比两者没有优势,他的好处是相比1要更容易处理时序数据,想比2可以实现复杂功能,例如机器学习函数
在性能上后续也可以想办法让PromQL可以分布式执行,以弥补目前全量原始数据需要汇聚到单一PromQL Engine带来的单点瓶颈问题
三种方式各有优缺点,我们提供了最大的灵活性,前期根据不同用户的使用场景,可以提供不同的解决方案,后续再有选择的做对应的优化
踩的小坑
sls的查询引擎是基于presto修改而来,由于presto的核心功能之一就是支持多种数据源接入并做查询,因此接入一个Prometheus数据并不是特别困难,实现一个prometheus connector就好,但如果只实现一个connector,我们提供的SQL会是这样的:
SELECT * FROM metrics WHERE query='up' AND query_mode='range' AND step='1m'
这样可以很容易的把where条件下推给prometheus转换成对应的参数去执行
但也会带来几个问题:
- 当where条件不同时,返回的表结构不确定,比如查labels和query结果是不一样的,这会让人难以理解
- 用户无法预期我应该填写哪些条件,这里很难去做提示,只能写在文档中
所以我们决定把PromQL作为函数,这样更通俗易懂,但这样把参数下推到connector就变得困难了
为了解决这个问题,一开始想的解决方案是增加一个PlanOptimizer,去重写执行计划,但
因为语法本身和实际要表达的语义相差很大,所以presto生成的执行计划也就是基本全是错
的,那么就要很辛苦的去纠正执行计划树上的各个节点,勉强实现了一个版本,能够支持简单的查询,碰到复杂查询的时候就常常因为执行计划树没有进行正确的改写而导致无法执行
然后就转而去重写语句,presto同样抽象了这一层,叫StatementRewrite,通过他把函数写法改成where写法,这样presto自然能够生成正确的执行计划,后续就不需要在操心了,很容易就实现了兼容完整的SQL
总结
可观察性日益受重视,为了更好的服务各种可观察性场景,SLS通过支持多种查询方式整合不同的数据,试图在不同的使用场景下都让用户有最好的性能和最好的体验
目前只是初步的探索,在易用性和性能等方面我们还有很大的提升空间,此外在数据的可视化和场景化的分析上,包括根因定位,机器学习等方面我们还要继续做更多尝试,欢迎有兴趣的同学一起讨论~
参考文档
文中部分例子修改自: https://blog.timescale.com/blog/sql-vs-flux-influxdb-query-language-time-series-database-290977a01a8a/
https://zhuanlan.zhihu.com/p/74930691
https://www.cncf.io/blog/2019/05/21/a-brief-history-of-opentelemetry-so-far/
https://opentelemetry.io/
https://www.cncf.io/wp-content/uploads/2019/10/Cybernetics-of-Observability-and-Monitoring.pdf
https://www.robustperception.io/translating-between-monitoring-languages
