数据集成产品介绍
数据集成(Data Integration)
数据集成是阿里集团对外提供的稳定高效、弹性伸缩的数据集成平台,为阿里云大数据计算引擎(包括MaxCompute、AnalyticDB、OSS)提供离线(批量)数据进出通道。有别于传统的客户端点对点同步运行工具,数据集成本身以公有云服务为基本设计目标,集群化、服务化、多租户、水平扩张等功能都是其基本实现要求。
通过DataWorks应用数据集成的入口
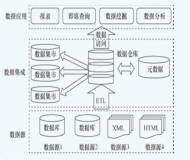
离线(批量)的数据通道主要通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(称之为Reader),数据写入插件(称之为Writer),并基于此框架设计一套简化版的中间数据传输格式,从而达到任意结构化、半结构化数据源之间数据传输的目的。
逻辑结构如下:
来源数据源->Reader数据抽取插件->Channel传输通道->Writer数据写入插件->目标数据源
数据集成支持的数据源
数据同步
数据同步广义是指为保持两端数据一致性而进行的数据传输过程。一般来说,数据集成的数据同步是为保证源宿两端数据逻辑的一致性,将数据源端移动到数据目的端,并伴随一定的数据转换或者清洗的过程。在数据集成的功能边界中,数据同步定义为云上各种存储产品之间进行的数据转移过程。
数据同步类型:离线数据同步和流式数据同步
同步三要素:数据源、数据转换过程(optional)、数据目的端
数据同步作业
作业(JOB)是数据集成进行数据批量同步的基本业务单元,数据集成的Job面向表级别数据同步。描述了一个数据同步作业完成一次数据同步任务所需要的信息,包括E(Extract)、T(Transform)、L(Load)等用户描述信息,也包括作业的运行信息。
作业模型:数据集成本身不保存作业信息;用户提交每一次作业都生成一个job对象,并为其分配唯一的Job ID;多次提交生成多个Job ID,运行一次即是一个独立的Job。
调度模型:作业速率信息,实际速率受网络环境、数据库配置等影响;单并发同步作业,作业并发数*单并发的传输速率=作业传输总速率。
约束限制:目前需要提前在目的端数据源进行建表操作;按照原宿两端Column的映射情况进行传输,而非Column名称或者类型进行;同步过程存在字段类型饮式转换规则,常见如整型、浮点型转为字符串类型。
数据同步的权限与安全:
用户角色
系统隔离
数据源鉴权
DataX
DataX是一个异构数据源离线同步工具,用于实现包括关系型数据库(MySQL、oracle等)、HDFS、Hive、ODPS、Hbase、FTP等各种异构数据源之间稳定高效的数据同步功能,其设计理念为将复杂的网络的异构数据源同步链路变成星型数据链路,DataX作为中间传输载体负责连接各种数据源。
同步任务配置流程
利用数据集成同步数据
配置数据源
配置数据源步骤:
1、选择新增数据源类型;
2、配置数据源相关属性:如数据源名称、连接信息、登录名以及密码(不同的数据源配置的属性信息不同);
3、测试连通性,目的是验证输入的数据源是否正确;
4、确定,完成配置
创建同步任务
步骤:
1、新建同步任务(节点)
2、选择来源
3、选择目标
4、字段映射
5、通道控制
6、预览保存
运行同步任务
直接运行:指运行在默认的资源组上,而且可以在当前窗口下方直接看到运行日志(日志不保存,消失后不可见)
调度运行:配置调度任务一般在第二天生产实例节点到设置调度时间就会开始运行任务
补数据运行:一般是运行失败同步任务,补数据重新运行昨天的同步任务数据
测试节点运行:测试节点选择当天以前的实例节点运行,同步任务立刻运行并查看日志
同步中的脏数据和容错
数据同步通常会对接源端和目标端的数据存储,需要根据来源和目标两端数据源的具体信息适配和转换相应的数据内容。在传输过程中,可能存在由于两端元数据不匹配或者本身的业务数据传输失败的情况,数据集成自动识别脏数据并提供容错机制。
脏数据可能产生的原因:
数据类型转换出错,如String[""]不能转为long;
数据超出定义范围(Out of range value),如源端设置的是smallint(5),目标端是int(11) unsigned,因为smallint(5)范围有负数,unsigned不允许有负数,所以产生脏数据。
存储表情符emoj,数据表配置成了可以存储的emoj的,同步时报脏数据。
空字段引起脏数据
数据同步过程中的常见配置
配置白名单
为保证数据库的安全稳定,在开始使用某些数据库实例前,需要将访问数据库的IP地址或者IP段加到目标实例的白名单或安全组中,否则无权限访问数据。
说明:常见的数据源如RDS、Mongodb、Redis等,需要在其控制台对目标数据的IP进行开放。一般添加白名单有以下两种情况:
同步任务运行在自定义资源组上,要给自定义资源组机器授权,将自定义机器内/外网IP添加数据源的白名单列表。
同步任务运行默认资源组上,要给默认的机器授权,一般根据dataworks的region来选定对应的白名单地址。
数据集成连接RDS同步数据需要使数据库标准协议连接数据库。RDS默认允许所有IP连接,但如果在RDS指定来IP白名单,则需要添加数据集成执行节点IP白名单。
配置安全组:
通道控制参数DMU配置
通道控制参数并发配置
并发:可视为数据同步任务内,从源并行读取或并行写入数据存储端的最大线程数;向导模式通过界面化配置并发数,指定任务所使用的并行度;脚本模式通过代码设置。并发配置的越大,则所需要的系统资源(DMU)越多,在网络状况和读写端数据源能力满足的情况下,同步速度可以呈线性增长。
DMU和并发有联动关系:当DMU配置为10时,最高并发数不可超过10;
配置高并发,需要考虑读写端数据源的能力,并发过高可能会对源端数据库造成性能影响;
脚本模式中,并发值虽然可以设置较高,但单任务所分配数据移动单元DMU会有控制。
数据集成同步任务默认不限速,任务将在所配置的并发数、DMU数的限制上以最高能达到的速度进行同步。
另一方面,由于速度过高可能对数据库造成过大的压力从而影响生产,如设置限速,建议最高速度上限不应超过30MB/s。
通道控制错误记录数配置
数据源切分键配置
数据字段映射配置