1. 表同步阶段处理流程概述
订阅端执行CREATE SUBSCRIPTION后,在后台进行表数据同步。
每个表的数据同步状态记录在pg_subscription_rel.srsubstate中,一共有4种状态码。
- 'i':初始化
- 'd':正在copy数据
- 's':已同步
- 'r':准备好 (普通复制)
从执行CREATE SUBSCRIPTION开始订阅端的相关处理流程概述如下:
- 设置每个表的为srsubstate中'i'(
SUBREL_STATE_INIT) - logical replication launcher启动一个logial replication apply worker进程
- logial replication apply worker进程连接到订阅端开始接受订阅消息,此时表尚未完成初始同步(状态为i或d),跳过所有insert,update和delete消息的处理。
- logial replication apply worker进程为每个未同步的表启动logial replication sync worker进程(每个订阅最多同时启动
max_sync_workers_per_subscription个sync worker) -
logial replication sync worker进程连接到订阅端并同步初始数据
- 5.1 创建临时复制槽,并记录快照位置。
- 5.2 设置表同步状态为'd'(
SUBREL_STATE_DATASYNC) - 5.3 copy表数据
- 5.4 设置表同步状态为
SUBREL_STATE_SYNCWAIT(内部状态),并等待apply worker更新状态为SUBREL_STATE_CATCHUP(内部状态)
- logial replication apply worker进程更新表同步状态为
SUBREL_STATE_CATCHUP(内部状态),记录最新lsn,并等待sync worker更新状态为SUBREL_STATE_SYNCDONE -
logial replication sync worker进程完成初始数据同步
- 7.1 检查apply worker当前处理的订阅消息位置是否已经走到了快照位置前面,如果是从订阅端接受消息并处理直到追上apply worker。
- 7.2 设置表同步状态为's'(
SUBREL_STATE_SYNCDONE) - 7.3 进程退出
-
logial replication apply worker进程继续接受订阅消息并处理
- 8.1 接受到insert,update和delete消息,如果是同步点(进入's'或'r'状态时的lsn位置)之后的消息进行应用。
-
8.2 接受到commit消息
- 8.2.1 更新复制源状态,确保apply worker crash时可以找到正确的开始位置
- 8.2.2 提交事务
- 8.2.3 更新统计信息
- 8.2.4 将所有处于's'(
SUBREL_STATE_SYNCDONE)同步状态的表更新为'r'(SUBREL_STATE_READY)
-
8.3 暂时没有新的消息处理
- 8.3.1 向发布端发送订阅位置反馈
- 8.3.2 如果不在事务块里,同步表状态。将所有处于's'(
SUBREL_STATE_SYNCDONE)同步状态的表更新为'r'(SUBREL_STATE_READY)
2. 表同步后的持续逻辑复制
订阅表进入同步状态(状态码是‘s’或'r')后,发布端的变更都会通过消息通知订阅端;
订阅端apply worker按照订阅消息的接受顺序(即发布端事务提交顺序)对每个表apply变更,并反馈apply位置,用于监视复制延迟。
通过调试,确认发布端发生更新时,发送给订阅端的数据包。
2.1 插入订阅表
insert into tbx3 values(100);
发布端修改订阅表时,在事务提交时,发布端依次发送下面的消息到订阅端
- B(BEGIN)
- R(RELATION)
- I(INSERT)
- C(COMMIT)
更新复制源pg_replication_origin_status中的remote_lsn和local_lsn,该位点对应于每个订阅表最后一次事务提交的位置。 - k(KEEPALIVE)
-
k(KEEPALIVE)
2个keepalive消息,会更新统计表中的位置- 发布端
pg_stat_replication:write_lsn,flush_lsn,replay_lsn - 发布端
pg_get_replication_slots():confirmed_flush_lsn - 订阅端更新
pg_stat_subscription:latest_end_lsn
- 发布端
2.2 插入非订阅表
insert into tbx10 values(100);
发布端产生了和订阅表无关修改,在事务提交时,发布端依次发送下面的消息到订阅端
- B(BEGIN)
- C(COMMIT)
未产生实际事务,也不更新pg_replication_origin_status - k(KEEPALIVE)
- k(KEEPALIVE)
2个'k' keepalive消息,会更新统计表中的位置
3. 异常处理
3.1 sync worker
- SQL错误(如主键冲突):worker进程异常退出,之后apply worker创建一个新的sync worker重试。错误解除前每5秒重试一次。
- 表被锁:等待
- 更新或删除的记录不存在:正常执行,检测不到错误,也么没有日志输出(输出一条DEBUG1级别的日志)。
3.2 apply worker
- SQL错误(如主键冲突):worker进程异常退出,之后logical replication launcher创建一个新的apply worker重试。错误解除前每5秒重试一次。
- 表被锁:等待
- 更新或删除的记录不存在:正常执行,检测不到错误,也么没有日志输出(输出一条DEBUG1级别的日志)。
错误日志示例:
2018-07-28 20:11:56.018 UTC [470] ERROR: duplicate key value violates unique constraint "tbx3_pkey"
2018-07-28 20:11:56.018 UTC [470] DETAIL: Key (id)=(2) already exists.
2018-07-28 20:11:56.022 UTC [47] LOG: worker process: logical replication worker for subscription 74283 (PID 470) exited with exit code 1
2018-07-28 20:12:01.029 UTC [471] LOG: logical replication apply worker for subscription "sub_shard" has started
2018-07-28 20:12:01.049 UTC [471] ERROR: duplicate key value violates unique constraint "tbx3_pkey"
2018-07-28 20:12:01.049 UTC [471] DETAIL: Key (id)=(2) already exists.
2018-07-28 20:12:01.058 UTC [47] LOG: worker process: logical replication worker for subscription 74283 (PID 471) exited with exit code 1
2018-07-28 20:12:06.070 UTC [472] LOG: logical replication apply worker for subscription "sub_shard" has started
2018-07-28 20:12:06.089 UTC [472] ERROR: duplicate key value violates unique constraint "tbx3_pkey"
2018-07-28 20:12:06.089 UTC [472] DETAIL: Key (id)=(2) already exists.
4. 限制
- 不复制数据库模式和DDL命令。
- 不复制序列数据。序列字段(serial / GENERATED ... AS IDENTITY)的值会被复制,但序列的值不会更新
- 不复制TRUNCATE命令。
- 不复制大对象
- 复制只能从基表到基表。也就是说,发布和订阅端的表必须是普通表,而不是视图, 物化视图,分区根表或外部表。订阅继承表的父表,只会复制父表的变更。
- 只支持触发器的一部分功能
- 不支持双向复制,会导致WAL循环。
- 不支持在同一个实例上的两个数据库上创建订阅
- 不支持在备机上创建订阅
- 订阅表上没有合适的REPLICA IDENTITY时,发布端执行UPDATE/DELETE会报错
注意事项
- CREATE SUBSCRIPTION命令执行时,要等待发布端正在执行的事务结束。
- sync worker初始同步数据时,开启了"REPEATABLE READ"事务,期间产生的垃圾不能被回收。
- 订阅生效期间,发布端所有事务产生的WAL必须在该事务结束时才能被回收。
- 订阅端UPDATE/DELETE找不到数据时,没有任何错误输出。
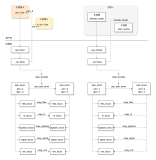
5. 表同步阶段相关代码解析
发布端Backend进程
CREATE PUBLICATION
CreatePublication()
CatalogTupleInsert(rel, tup); // 在pg_publication系统表中插入此发布信息
PublicationAddTables(puboid, rels, true, NULL);//
publication_add_relation()
check_publication_add_relation();// 检查表类型,不支持的表报错。只支持普通表('r'),且不是unloged和临时表
CatalogTupleInsert(rel, tup); // 在pg_publication_rel系统表中插入订阅和表的映射
订阅端Backend进程
CREATE SUBSCRIPTION
CreateSubscription()
CatalogTupleInsert(rel, tup); //在pg_subscription系统表中插入此订阅信息
replorigin_create(originname); //在pg_replication_origin系统表中插入此订阅对应的复制源
foreach(lc, tables) // 设置每个表的pg_subscription_rel.srsubstate
table_state = copy_data ? SUBREL_STATE_INIT : SUBREL_STATE_READY; // ★★★1 如果拷贝数据,设置每个表的pg_subscription_rel.srsubstate='i'
SetSubscriptionRelState(subid, relid, table_state,InvalidXLogRecPtr, false);
walrcv_create_slot(wrconn, slotname, false,CRS_NOEXPORT_SNAPSHOT, &lsn);
ApplyLauncherWakeupAtCommit(); //唤醒logical replication launcher进程
订阅端logical replication launcher进程
ApplyLauncherMain()
sublist = get_subscription_list(); //从pg_subscription获取订阅列表
foreach(lc, sublist)
logicalrep_worker_launch(..., InvalidOid); // 对enabled且没有创建worker的订阅创建apply worker。apply worker如果已超过max_logical_replication_workers(默认4)报错
RegisterDynamicBackgroundWorker(&bgw, &bgw_handle);// 注册后台工作进程,入口函数为"ApplyWorkerMain"
订阅端 logical apply worker进程
ApplyWorkerMain
replorigin_session_setup(originid); // 从共享内存中查找并设置复制源,如果不存在使用新的,复制源名称为pg_${订阅OID}。
origin_startpos = replorigin_session_get_progress(false);// 获取复制源的remote_lsn
walrcv_connect(MySubscription->conninfo, true, MySubscription->name,&err); // 连接到订阅端
walrcv_startstreaming(wrconn, &options); // 开始流复制
LogicalRepApplyLoop(origin_startpos); // Apply进程主循环
for(;;)
len = walrcv_receive(wrconn, &buf, &fd);
if (c == 'w') // 'w'消息的处理
UpdateWorkerStats(last_received, send_time, false);更新worker统计信息(last_lsn,last_send_time,last_recv_time)
apply_dispatch(&s); // 分发逻辑复制命令
switch (action)
case 'B': /* BEGIN */
apply_handle_begin(s);
case 'C': /* COMMIT */
apply_handle_commit(s);
if (IsTransactionState() && !am_tablesync_worker()) // 当发布端的事务更新不涉及订阅表时,仍会发送B和C消息,此时不在事务中,跳过下面操作
replorigin_session_origin_lsn = commit_data.end_lsn; // 更新复制源状态,确保apply worker crash时可以找到正确的开始位置
replorigin_session_origin_timestamp = commit_data.committime;
CommitTransactionCommand(); // 提交事务
pgstat_report_stat(false); // 更新统计信息
process_syncing_tables(commit_data.end_lsn); // 对处于同步中的表,协调sync worker和apply worker进程同步状态
process_syncing_tables_for_apply(current_lsn);
GetSubscriptionNotReadyRelations(MySubscription->oid); // 从pg_subscription_rel中获取订阅中所有非ready状态的表。
foreach(lc, table_states) // 处理每个非ready状态的表
if (rstate->state == SUBREL_STATE_SYNCDONE)
{
if (current_lsn >= rstate->lsn)
{
rstate->state = SUBREL_STATE_READY; //处理第一个事务后,从syncdone->ready状态,但这个事务不需要和这个表相关。
rstate->lsn = current_lsn;
SetSubscriptionRelState(MyLogicalRepWorker->subid, // 更新pg_subscription_rel
rstate->relid, rstate->state,
rstate->lsn, true);
}
}
else
{
syncworker = logicalrep_worker_find(MyLogicalRepWorker->subid,
rstate->relid, false);
if (syncworker)
{
/* Found one, update our copy of its state */
rstate->state = syncworker->relstate;
rstate->lsn = syncworker->relstate_lsn;
if (rstate->state == SUBREL_STATE_SYNCWAIT)
{
/*
* Sync worker is waiting for apply. Tell sync worker it
* can catchup now.
*/
syncworker->relstate = SUBREL_STATE_CATCHUP; // ★★★3 SUBREL_STATE_SYNCWAIT -> SUBREL_STATE_CATCHUP
syncworker->relstate_lsn =
Max(syncworker->relstate_lsn, current_lsn);
}
/* If we told worker to catch up, wait for it. */
if (rstate->state == SUBREL_STATE_SYNCWAIT)
{
/* Signal the sync worker, as it may be waiting for us. */
if (syncworker->proc)
logicalrep_worker_wakeup_ptr(syncworker);
wait_for_relation_state_change(rstate->relid,
SUBREL_STATE_SYNCDONE); // 等待sync worker将表的同步状态设置为SUBREL_STATE_SYNCDONE
}
}
else
{
/*
* If there is no sync worker for this table yet, count
* running sync workers for this subscription, while we have
* the lock.
*/
logicalrep_worker_launch(MyLogicalRepWorker->dbid, // 如果这个表没有对应的sync worker,且sync worker数未超过max_sync_workers_per_subscription,启动一个。
MySubscription->oid,
MySubscription->name,
MyLogicalRepWorker->userid,
rstate->relid);
}
else if (c == 'k') // 'k'消息的处理
send_feedback(last_received, reply_requested, false); // 向订阅端发生反馈
UpdateWorkerStats(last_received, timestamp, true); // 更新worker统计信息(last_lsn,last_send_time,last_recv_time,reply_lsn,send_time)
case I': /* INSERT */
apply_handle_insert(s);
relid = logicalrep_read_insert(s, &newtup);
if (!should_apply_changes_for_rel(rel))return;
if (am_tablesync_worker())
return MyLogicalRepWorker->relid == rel->localreloid; // 对sync worker,只apply其负责同步的表
else
return (rel->state == SUBREL_STATE_READY || // 对apply worker, 同步状态为SUBREL_STATE_SYNCDONE时,只同步syncdone位置之后的wal
(rel->state == SUBREL_STATE_SYNCDONE &&
rel->statelsn <= remote_final_lsn));
ExecSimpleRelationInsert(estate, remoteslot); // 插入记录
ExecBRInsertTriggers(estate, resultRelInfo, slot); // 处理BEFORE ROW INSERT Triggers
simple_heap_insert(rel, tuple);
ExecARInsertTriggers(estate, resultRelInfo, tuple,recheckIndexes, NULL); // 处理AFTER ROW INSERT Triggers
AfterTriggerEndQuery(estate); // 处理 queued AFTER triggers
...
send_feedback(last_received, false, false);//没有新的消息要处理,向发布端发送位置反馈
process_syncing_tables(last_received);//如果不在事务块里,同步表状态
订阅端 logical sync worker进程
ApplyWorkerMain() //apply worker和sync worker使用相同的入口函数
LogicalRepSyncTableStart(&origin_startpos);
GetSubscriptionRelState()(MyLogicalRepWorker->subid,MyLogicalRepWorker->relid,&relstate_lsn, true);// 从pg_subscription_rel中获取订阅的复制lsn
walrcv_connect(MySubscription->conninfo, true, slotname, &err);
switch (MyLogicalRepWorker->relstate)
{
case SUBREL_STATE_INIT:
case SUBREL_STATE_DATASYNC:
{
MyLogicalRepWorker->relstate = SUBREL_STATE_DATASYNC;
MyLogicalRepWorker->relstate_lsn = InvalidXLogRecPtr;
SetSubscriptionRelState(MyLogicalRepWorker->subid,
MyLogicalRepWorker->relid,
MyLogicalRepWorker->relstate,
MyLogicalRepWorker->relstate_lsn,
true);
res = walrcv_exec(wrconn, // 开始事务
"BEGIN READ ONLY ISOLATION LEVEL "
"REPEATABLE READ", 0, NULL);
walrcv_create_slot(wrconn, slotname, true, // 使用快照创建临时复制槽,并记录快照位置。
CRS_USE_SNAPSHOT, origin_startpos);
copy_table(rel); // copy表数据
walrcv_exec(wrconn, "COMMIT", 0, NULL);
MyLogicalRepWorker->relstate = SUBREL_STATE_SYNCWAIT; // ★★★2 更新表同步状态为SUBREL_STATE_SYNCWAIT
MyLogicalRepWorker->relstate_lsn = *origin_startpos;
wait_for_worker_state_change(SUBREL_STATE_CATCHUP); // 等待apply worker将状态变更为SUBREL_STATE_CATCHUP
if (*origin_startpos >= MyLogicalRepWorker->relstate_lsn) // 如果sync worker落后于apply worker,sync worker跳过此步继续apply WAL;
{
/*
* Update the new state in catalog. No need to bother
* with the shmem state as we are exiting for good.
*/
SetSubscriptionRelState(MyLogicalRepWorker->subid, // ★★★4 把同步状态从SUBREL_STATE_CATCHUP更新到SUBREL_STATE_SYNCDONE并退出
MyLogicalRepWorker->relid,
SUBREL_STATE_SYNCDONE,
*origin_startpos,
true);
finish_sync_worker();
}
break;
}
case SUBREL_STATE_SYNCDONE:
case SUBREL_STATE_READY:
case SUBREL_STATE_UNKNOWN:
finish_sync_worker();
break;
}
options.startpoint = origin_startpos;
walrcv_startstreaming(wrconn, &options);// 开始流复制,以同步快照位置作为流的开始位置
LogicalRepApplyLoop(origin_startpos); // Apply进程主循环
for(;;)
len = walrcv_receive(wrconn, &buf, &fd);
UpdateWorkerStats(last_received, send_time, false); 更新worker统计信息(last_lsn,last_send_time,last_recv_time)
apply_dispatch(&s); // 分发逻辑复制命令
switch (action)
case 'B': /* BEGIN */
apply_handle_begin(s);
case 'C': /* COMMIT */
apply_handle_commit(s);
process_syncing_tables(commit_data.end_lsn); // 对处于同步中的表,协调sync worker和apply worker进程同步状态
process_syncing_tables_for_sync(current_lsn);
if (MyLogicalRepWorker->relstate == SUBREL_STATE_CATCHUP &&
current_lsn >= MyLogicalRepWorker->relstate_lsn)
{
TimeLineID tli;
MyLogicalRepWorker->relstate = SUBREL_STATE_SYNCDONE; // ★★★4 把同步状态从SUBREL_STATE_CATCHUP更新到SUBREL_STATE_SYNCDONE
MyLogicalRepWorker->relstate_lsn = current_lsn;
SpinLockRelease(&MyLogicalRepWorker->relmutex);
SetSubscriptionRelState(MyLogicalRepWorker->subid,
MyLogicalRepWorker->relid,
MyLogicalRepWorker->relstate,
MyLogicalRepWorker->relstate_lsn,
true);
walrcv_endstreaming(wrconn, &tli);
finish_sync_worker();
}
case I': /* INSERT */
apply_handle_insert(s);