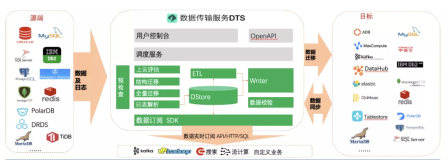
数据集成(Data Integration)是阿里集团对外提供的可跨异构数据存储系统的、可靠、安全、低成本、可弹性扩展的数据同步平台,为20+种数据源提供不同网络环境下的离线(全量/增量)数据进出通道,是阿里集团对外提供的稳定高效、弹性伸缩的数据同步平台。致力于提供复杂网络环境下、丰富的异构数据源之间数据高速稳定的数据移动及同步能力。
关于阿里云数据集成平台更多内容:阿里云数据集成平台使用教程
离线(批量)数据同步简介
离线(批量)的数据通道主要通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(称之为 Reader)、数据写入插件(称之为 Writer),并基于此框架设计一套简化版的中间数据传输格式,从而达到任意结构化、半结构化数据源之间数据传输的目的。
支持数据源类型
数据集成提供丰富的数据源支持,如下所示:
文本存储(FTP / SFTP / OSS / 多媒体文件等)。
数据库(RDS / DRDS / MySQL / PostgreSQL 等)。
NoSQL(Memcache / Redis / MongoDB / HBase 等)。
大数据(MaxCompute / AnalyticDB / HDFS 等)。
MPP 数据库(HybridDB for MySQL 等)。
更多详情请参见 支持数据源类型。
注意:
由于每个数据源的配置信息差距较大,需要根据使用情况详细查询参数配置信息。所以在数据源配置、作业配置页面提供了详细描述,请您根据自身情况进行查询使用。
同步开发说明
同步开发提供两种开发模式:向导模式和脚本模式。
1.向导模式:提供向导式的开发引导,通过可视化的填写和下一步的引导,帮助快速完成数据同步任务的配置工作。向导模式的学习成本低,但无法享受到一些高级功能。
2.脚本模式:您可以通过直接编写数据同步的 JSON 脚本来完成数据同步开发,适合高级用户,学习成本较高。脚本模式可以提供更丰富灵活的能力,做精细化的配置管理。
注意:
向导模式生成的代码可以转换为脚本模式,此转换为单向操作,转换完成后无法恢复到向导模式。因为脚本模式能力是向导模式的超集。
代码编写前需要完成数据源的配置和目标表的创建。
网络类型说明
网络类型分为:经典网络、专有网络(VPC)、本地 IDC 网络(规划中)。
1.经典网络:统一部署在阿里云的公共基础网络内,网络的规划和管理由阿里云负责,更适合对网络易用性要求比较高的客户。
2.专有网络:基于阿里云构建出一个隔离的网络环境。您可以完全掌控自己的虚拟网络,包括选择自有的 IP 地址范围,划分网段,以及配置路由表和网关。
3.本地 IDC 网络:您自身构建机房的网络环境,与阿里云网络是隔离不可用的。
4.经典网络和专有网络相关问题请参见 经典网络和VPC常见问题FAQ 。
补充说明:
1.网络连接可以支持公网连接,网络类型选择经典网络即可。需要注意公网带宽的速度和相关网络费用消耗。无特殊情况不建议使用。
2.规划中的网络连接,进行数据同步,可以使用本地新增运行资源 + 脚本模式的方案进行数据同步传输。或者使用 SHELL + DataX 方案,此方案请参见 使用shell执行datax任务。
3.专有网络 VPC 是构建一个隔离的网络环境,可以自定义 IP 地址范围、网段、网关等随着专有网络安全性提高,专有网络运用越来越广,所以数据集成提供了 RDS-MySQL、RDS-SQL Server、RDS-PostgreSQL,在专有网络下不需要购买一台跟 VPC 同网络的 ECS,系统通过反向代理会自动检测从而网络能够互通。对于阿里云其他的数据库 PPAS、OceanBase、Redis、MongoDB、Memcache、TableStore、HBase 等,后续也会提供支持。所以非 RDS 的数据源在专有网络下配置数据集成的同步任务需要购买同网络的 ECS,这样可以通过 ECS 连通网络。
约束与限制
1.支持且仅支持结构化(例如 RDS、DRDS 等)、半结构化、无结构化(OSS、TXT 等,要求具体同步数据必须抽象为结构化数据)的数据同步。换言之,Data Integration 支持传输能够抽象为逻辑二维表的数据同步,其他完全非结构化数据,例如 OSS 中存放的一段 MP3,Data Integration 暂未支持将其同步到 MaxCompute,这个功能会在后期实现。
2.支持单个和部分跨 region 地域内数据存储相互同步、交换的数据同步需求。
3.部分地域通过经典网络是可以传输的,不能保证。如果必须使用且测试经典网络不通,可以考虑使用公网方式连接。
4.仅完成数据同步(传输),本身不提供数据流的消费方式。