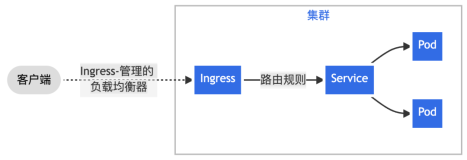
您可以让 Kong 代理的 API 使用 ring-balancer , 通过添加包含一个或多个目标实体的upstream 实体来配置,每个目标指向不同的IP地址(或主机名)和端口。ring-balancer 将在不同的target之间平衡负载,并基于 uptream 配置对目标执行健康检查,使它们成为健康或不健康的,无论它们是否响应,ring-balancer 将只把流量路由到健康的target。
Kong 支持两种健康检查方式,可以单独使用,也可以组合使用。
- active checks:其中定期请求目标中的特定 HTTP 或 HTTPS 端点,并根据其响应确定目标的健康状态;
- passive checks: Kong 分析正在代理的通信,并根据目标的行为响应请求来确定目标的健康状况。
健康和不健康的 target
健康检查功能的目标是为给定的 Kong 节点动态地将 target 标记为健康或不健康。没有集群范围内的健康信息同步,每个 Kong 节点分别确定其 target 的健康状况。这是可以取到的,因为在给定的点上,一个 Kong 节点可能能够成功地连接到一个目标,而另一个节点则无法到达。这样第一个节点将认为它是健康的,而第二个则会将其标记为不健康,并开始将流量路由到upstream 的其他 target。
无论是主动探测(针对主动健康检查)还是代理请求(针对被动健康检查),都会生成用于确定目标是否健康的数据。请求可能会产生TCP错误、超时或HTTP状态代码。基于此信息,健康检查器更新了一系列内部计数器:
- 如果返回的状态码配置为 “healthy”,则将增加目标的 “Successes” 计数器,并清除其所有其他计数器;
- 如果连接失败,将增加目标的 “TCP failure”计数器,并清除 “Successes” 计数器;
- 如果超时,将增加目标的 “timeouts” 计数器并清除 “Successes” 计数器;
- 如果返回的状态代码配置为 “unhealthy”,它将增加目标的 “HTTP failures” 计数器,并清除 “Successes” 计数器。
如果任何 “TCP failure”、“HTTP failure” 或 “timeout” 计数器达到其配置的阈值,则target 将被标记为不健康。
如果 “success” 计数器达到其配置的阈值,则 target 将被标记为健康。
如果一个 upstream 的所有 target 都是不健康,Kong 会将 upstream 的请求返回 503 Service Unavailable 。
- 健康检查只对状态是 active 的 target 执行,不修改 Kong 数据库中目标的活动状态。
- 不健康的 target 不会从 loadbalancer 中删除,因此在使用哈希算法时不会对balancer 布局产生任何影响(只会跳过它们)。
- DNS警告和 Balancer 警告也适用于健康检查。如果对 target 使用主机名,需要确保DNS服务器始终为完整的 IP地址和名称,并且不限制响应。如果不这样做,可能会导致没有执行健康检查。
健康检查的类型
健康检查有两种类型,分别是 Active health checks 和 Passive health checks
Active health checks
Active health checks 就是主动探测他们的健康状态。当 upstream 实体启用活动健康检查时,Kong 将定期向 upstream 的每个 target 的配置路径发出 HTTP 或 HTTPS 请求。这允许 Kong 根据探测结果自动启用和禁用 balancer 中的 target 。
Active health checks 的周期性是可以被配置的,当 target 是健康还是不健康。如果其中一个的interval值设置为零,则在相应的场景中禁用检查。如果两者都为零,则完全禁用活动健康检查。
Passive health checks
Passive health checks 是否基于由 Kong 代理的请求(HTTP/HTTPS/TCP)执行检查,而不生成额外的流量。当 target 变得无响应时,被动健康检查器将检测到这一点,并将目标标记为不健康。Ring-balancer 将开始跳过这个 target ,因此不会有更多的流量被路由到它。
当目标的问题解决,并准备再次接收流量时,Kong管理员可以手动通知health checker目标应该再次启用,通过一个Admin API端点:
$ curl -i -X POST http://localhost:8001/upstreams/my_upstream/targets/10.1.2.3:1234/healthy
HTTP/1.1 204 No Content这个命令将广播一个集群范围的消息,以便将 “health” 状态传播到整个 Kong 集群。这将导致 Kong 节点重置在 Kong 节点的所有 worker 中运行的健康检查器的健康计数器,从而允许环平衡器再次将流量路由到目标。
被动健康检查的优点是不会产生额外的流量,但它们不能自动将 target 重新标记为健康状态:“circuit is broken”,需要由系统管理员重新启用目标。
Kong 的监控
Kong 支持使用 Prometheus 进行监控数据采集,并且官方提供了采集方式和 Grafana 的Dashboard 模板
官方的 Kong Plugin Prometheus 会定期更新,看上去比较活跃。
除了官网以外,有网友也提供了一个监控模板,不过最后一次更新时间是2018 年 5 月 17 日,之后就没有更新了,大家也可以参考。kong-prometheus-plugin
小结
Kong 的健康检查主要介绍了健康检查的类型,这两类的健康检查是可以打开和关闭的,打开和关闭的具体方法请参考官网文档。