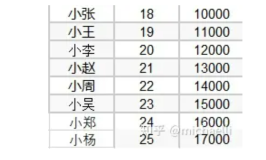
大数据之什么是Hash表,Hash,一般翻译做“散列”,也有直接音译为“哈希”的,它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法。顾名思义,该数据结构可以理解为一个线性表,但是其中的元素不是紧密排列的,而是可能存在空隙。
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。比如我们存储70个元素,但我们可能为这70个元素申请了100个元素的空间。70/100=0.7,这个数字称为负载(加载)因子。我们之所以这样做,也 是为了“快速存取”的目的。我们基于一种结果尽可能随机平均分布的固定函数H为每个元素安排存储位置,以达到快速存取。但是由于此随机性,也必然导致一个问题就是冲突。所谓冲突,即两个元素通过散列函数H得到的地址相同,那么这两个元素称为“同义词”。这类似于70个人去一个有100个椅子的饭店吃饭。散列函数的计算结果是一个存储单位地址,每个存储单位称为“桶”。设一个散列表有m个桶,则散列函数的值域应为[0,m-1]。
这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置
2.hash表扩容的理解
可是当哈希表接近装满时,因为数组的扩容问题,性能较低(转移到更大的哈希表中).
Java默认的散列单元大小全部都是2的幂,初始值为16(2的4次幂)。假如16条链表中的75%链接有数据的时候,则认为加载因子达到默认的0.75。HahSet开始重新散列,也就是将原来的散列结构全部抛弃,重新开辟一个散列单元大小为32(2的5次幂)的散列结果,并重新计算各个数据的存储位置。以此类推下去.....
负载(加载)因子:0.75.-->hash表提供的空间是16 也就是说当到达12的时候就扩容
3.排重机制的实现
假如我们有一个数据(散列码76268),而此时的HashSet有128个散列单元,那么这个数据将有可能插入到数组的第108个链表中(76268%128=108)。但这只是有可能,如果在第108号链表中发现有一个老数据与新数据equals()=true的话,这个新数据将被视为已经加入,而不再重复丢入链表。
4.优点
哈希表的插入和查找是很优秀的.
对于查找:直接根据数据的散列码和散列表的数组大小计算除余后,就得到了所在数组的位置,然后再查找链表中是否有这个数据即可。因为数组本身查找速度快,所以查找的效率高低体现在链表中,但是真实情况下在一条链表中的数据又很少,有的甚至没有,所以几乎没有什么迭代的代价。所以散列表的查找效率建立在散列单元所指向的链表中数据的多少上.
对于插入:数组的插入速度慢,而链表的插入速度快.当我们使用哈希表时,不需要更改数组的结构,只需要在找到对应的数组下标后,进入对应的链表,操作链表即可.所以hash表的整体插入速度也很快.
5.模拟实现代码
Node类
public class Node {
// key、value模拟键值对的数据
public Integer key;
public String value;
// 下一节点的引用
public Node next;
public Node() {
}
public Node(int key, String value) {
this.key = key;
this.value = value;
}
}MyLinkedList类
public class MyLinkedList {
// 根节点
private Node root;
public MyLinkedList() {
root = new Node();
}
/**
* 添加数据,key值必须唯一,如果重复值将被覆盖
* @param key
*/
public void add(int key, String value) {
Node newNode = new Node(key, value);
Node current = root;
while (current.next != null) {
if(current.next.key == key) {
current.next.value = value;
return;
}
current = current.next;
}
current.next = newNode;
}
/**
* 删除数据
* @param key
* @return
*/
public boolean delete(int key) {
Node current = root;
while (current.next != null) {
if(current.next.key == key) {
current.next = current.next.next;
return true;
}
current = current.next;
}
return false;
}
/**
* 根据key获取value
* @param key
* @return
*/
public String get(int key) {
Node current = root;
while (current.next != null) {
if(current.next.key == key) {
return current.next.value;
}
current = current.next;
}
return null;
}
/**
* 遍历链表,列出所有数据
* @return
*/
public String list() {
String str = "";
Node current = root.next;
while (current != null) {
str += "(" + current.key + "," + current.value + "),";
current = current.next;
}
return str;
}
@Override
public String toString() {
return list();
}
}MyHashMap类
// 哈希表
public class MyHashMap {
// 链表数组,数组的每一项都是一个链表
private MyLinkedList[] arr;
// 数组的大小
private int maxSize;
/**
* 空参构造,默认数组大小为10
*/
public MyHashMap() {
maxSize = 10;
arr = new MyLinkedList[maxSize];
}
/**
* 带参构造,数组大小自定义
* @param maxSize
*/
public MyHashMap(int maxSize) {
this.maxSize = maxSize;
arr = new MyLinkedList[maxSize];
}
/**
* 添加数据,key值必须唯一
* @param key
* @param value
*/
public void put(int key, String value) {
int index = getHashIndex(key);
if(arr[index] == null) {
arr[index] = new MyLinkedList();
}
arr[index].add(key, value);
}
/**
* 删除数据
* @param key
* @return
*/
public boolean delete(int key) {
int index = getHashIndex(key);
if(arr[index] != null) {
return arr[index].delete(key);
}
return false;
}
/**
* 根据key获取value
* @param key
* @return
*/
public String get(int key) {
int index = getHashIndex(key);
if(arr[index] != null) {
return arr[index].get(key);
}
return null;
}
/**
* 获取数组下标
* @param key
* @return
*/
private int getHashIndex(Integer key) {
return key.hashCode() % maxSize;
}
/**
* 遍历数组中所有链表的数据
* @return
*/
public String list() {
String str = "[ ";
for (int i = 0; i < maxSize; i++) {
if(arr[i] != null) {
str += arr[i].toString();
}
}
str = str.substring(0, str.length()-1);
str += " ]";
return str;
}
@Override
public String toString() {
return list();
}
}测试类
public class Test {
public static void main(String[] args) {
MyHashMap map = new MyHashMap(20);
map.put(5, "aaa");
map.put(8, "bbb");
map.put(3, "ccc");
map.put(8, "bbb");
map.put(2, "ddd");
map.put(9, "eee");
System.out.println(map);
System.out.println(map.get(3));
System.out.println(map.delete(2));
System.out.println(map);
}
}