本文介绍如何在E-MapReduce中通过Tablestore Spark Streaming Source将TableStore中的数据实时导入到Delta Lake中。
背景介绍
近些年来HTAP(Hybrid transaction/analytical processing)的热度越来越高,通过将存储和计算组合起来,既能支持传统的海量结构化数据分析,又能支持快速的事务更新写入,是设计数据密集型系统的一个成熟的架构。
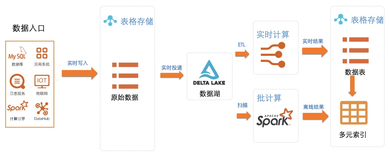
表格存储(Tablestore)是阿里云自研的 NoSQL 多模型数据库,提供海量结构化数据存储以及快速的查询和分析服务(PB 级存储、千万 TPS 以及毫秒级延迟),借助于表格存储的底层引擎,能够很好的完成OLTP场景下的需求。Delta Lake类似于支持Delta的Data Lake(数据湖),使用列存来存base数据,行的格式存储新增delta数据,进而做到支持数据操作的ACID和CRUD,完全兼容Spark的大数据生态,通过结合Delta Lake和Spark生态,能够很好的完成OLAP场景下的需求。下图展示的是Tablestore和Delta Lake结合的HATP场景的一个简要的逻辑结构图,有关结构化大数据分析平台设计的更多细节和干货,可以参阅文章 结构化大数据分析平台设计。
准备工作
- 登录阿里云E-MapReduce控制台
- 创建Hadoop集群(若已创建,请跳过)
- 确保将Tablestore实例部署在E-MapReduce集群相同的VPC环境下
步骤一 创建Tablestore源表
详细开通步骤请参考官方文档,本文demo中所创建出来的表名为Source,表的Schema如下图所示,该表有PKString和PkInt两个主键,类型分别为String和Interger。
为表Source建立一个增量通道,如下图所示,通道列表里面会显示该通道的名字、ID以及类型。
技术注解:
通道服务(Tunnel Service)是基于Tablestore数据接口之上的全增量一体化服务,包含三种通道类型:
- 全量:对数据表中历史存量数据消费处理
- 增量:对数据表中新增数据消费处理
- 全量加增量:先对数据表总历史存量数据消费,之后对新增数据消费
通道服务的详细介绍可查询Tablestore官网文档。
步骤二 获取相关jar包并上传到hadoop集群
- 获取环境依赖的JAR包。
| Jar包 | 获取方法 | |
|---|---|---|
| emr-tablestore-X.X.X.jar X.X.X: Since 1.9.0+ |
Maven 库中下载:https://mvnrepository.com/artifact/com.aliyun.emr/emr-tablestore | |
| tablestore-X.X.X-jar-with-dependencies.jar | 下载 EMR SDK 相关的Tablestore依赖包。https://repo1.maven.org/maven2/com/aliyun/openservices/tablestore/5.3.0/tablestore-5.3.0-jar-with-dependencies.jar | |
- 在集群管理页面,单击已创建的Hadoop集群的集群ID ,进入集群与服务管理页面。
- 在左侧导航树中选择主机列表,然后在右侧查看Hadoop集群中emr-header-1主机的IP信息。
- 在SSH客户端中新建一个命令窗口,登录Hadoop集群的emr-header-1主机。
- 上传所有JAR包到emr-header-1节点的某个目录下。
步骤三 运行Spark Streaming作业
- 以一个基于emr demo修改的代码为样例,编译生成JAR包,JAR包需要上传到Hadoop集群的emr-header-1主机中(参见步骤二),完整的代码由于改动较大,不在本文中一一说明,后续会合到emr demo官方项目中。
- 该样例以Tablestore表作为数据源,通过结合Tablestore CDC技术,Tablestore Streaming Source和Delta Sink,演示的是TableStore到Delta Lake的一个完整链路。
- 按以下命令,启动spark streaming作业,开启一个实时同步Tablestore Source表中数据到Delta Lake Table的监听程序。
spark-submit --class com.aliyun.emr.example.spark.sql.streaming.DeltaTableStoreCDC --jars emr-tablestore-X.X.X-SNAPSHOT.jar,tablestore-X.X.X-jar-with-dependencies.jar examples-X.X.X-shaded.jar <instance> <tableName> <tunnelId> <accessKeyId> <accessKeySecret> <endPoint> <maxOffsetsPerChannel>各个参数说明如下:
| 参数 | 参数说明 |
|---|---|
| com.aliyun.emr.example.spark.sql.streaming.DeltaTableStoreCDC | 所要运行的主程序类 |
| emr-tablestore-X.X.X-SNAPSHOT.jar | 包含Tablestore source的jar包 |
| tablestore-X.X.X-jar-with-dependencies.jar | EMR SDK 相关的Tablestore依赖包 |
| examples-X.X.X-shaded.jar | 基于EMR demo修改的包(包含主程序类) |
| instance | Tablestore实例名 |
| tableName | Tablestore表名 |
| tunnelId | Tablestore表的通道Id |
| accessKeyId | Tablestore的accessKeyId |
| accessKeySecret | Tablestore的秘钥 |
| endPoint | Tablestore实例的endPoint |
| maxOffsetsPerChannel | Tablestore通道 Channel在每个Spark Batch周期内同步的最大数据条数,默认10000。 |
| catalog | 同步的列名,详见Catalog字段说明 |
步骤四 数据CRUD示例
- 首先在TableStore里插入两行,本次示例中,我们建了8列的同步列,包括两个主键(PkString, PkInt)和六个属性列(col1, col2, col3, timestamp, col5和col6)。由于表格存储是Free-Schema的结构,我们可以任意的插入属性列,TableStore的Spark Source会自动的做属性列的筛选。如下面两张图所示,在插入两行数据后,Delta Table中同步也可以马上读取到两行,且数据一致。


- 接着,在Tablestore中进行一些更新行和插入行的操作,如下面的两个图所示,等待一小段micro-batch的数据同步后,表格存储中的数据同步变化能够即时的更新到Delta Table中。


- 将Tablestore中的数据全部清空,如下面两图所示,Delta Table也同步的变成了空。


- 在集群上,Delta Table默认存放在HDFS中,如下图所示,_delta_log目录中存放的json文件是Transaction log,parquet格式的文件是底层的数据文件。

写在最后
本文介绍了如何在E-MapReduce中通过Tablestore Spark Streaming Source将TableStore中的数据实时导入到Delta Lake中,如果对基于Tablestore的大数据存储分析感兴趣的朋友可以加入我们的技术交流群(钉钉:23307953 或者11789671),来与我们一起探讨。