一.Alluxio概述
Alluxio(前身Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。
Alluxio项目源自加州大学伯克利分校AMPLab,作为伯克利数据分析堆栈(BDAS)的数据访问层。Alluxio是增长最快的开源项目之一,吸引了来自300多家机构的1000多名贡献者,包括阿里巴巴,Alluxio,百度,CMU,谷歌,IBM,英特尔,NJU,红帽,腾讯,加州大学伯克利分校,以及雅虎。
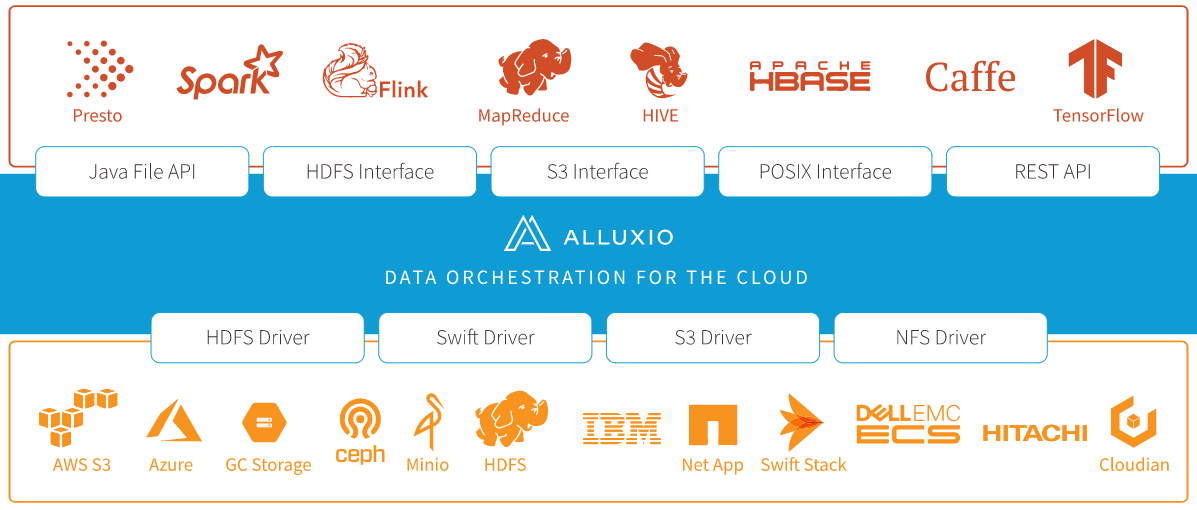
二.Alluxio架构
Alluxio是大数据和机器学习生态系统中的新数据访问层。Alluxio作为据访问层处于持久存储层(如Amazon S3,Microsoft Azure Object Store,Apache HDFS或OpenStack Swift)和计算框架层(如Apache Spark,Presto或Hadoop MapReduce)之间。
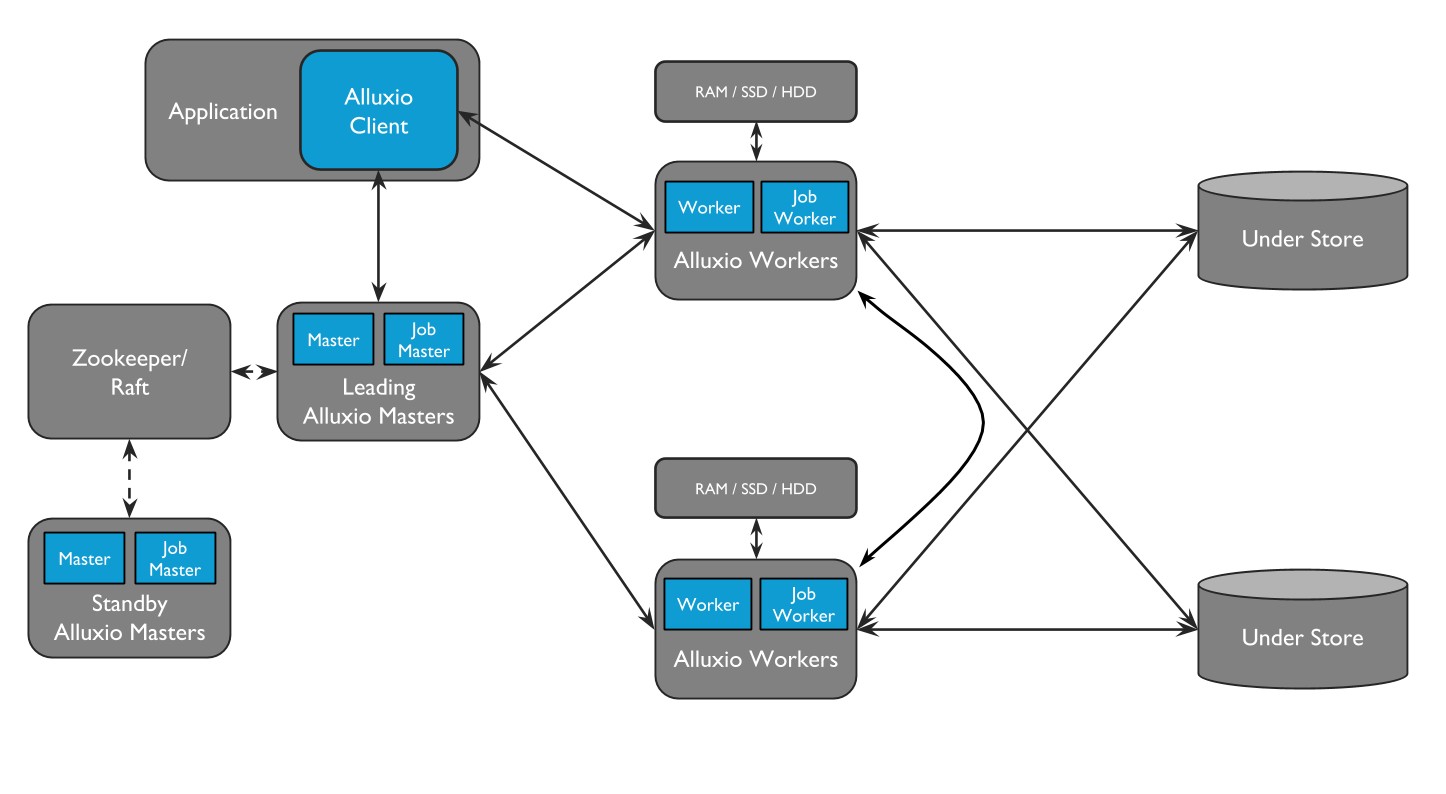
Alluxio主要包括3个角色:masters, workers, 和clients。典型的集群是由主备masters,主备job master,workers和job workers组成。
Job Masters和Job Workers可以作为单独的功能,即Job Service。Job Service是一个轻量级的任务调度框架,负责为Job Worker分配各种不同类型的操作。
- 将UFS的数据加载到Alluxio
- 数据保留到UFS
- 复制Alluxio中的文件
- UFS/Alluxio之间移动或复制数据
Ⅰ).Masters
Alluxio包括2类主进程:
- Master: 为元数据的变更(用户请求和日志文件系统)提供服务
- Job Master: 做为轻便的调度器,对执行在Job Master上的文件操作提供调度
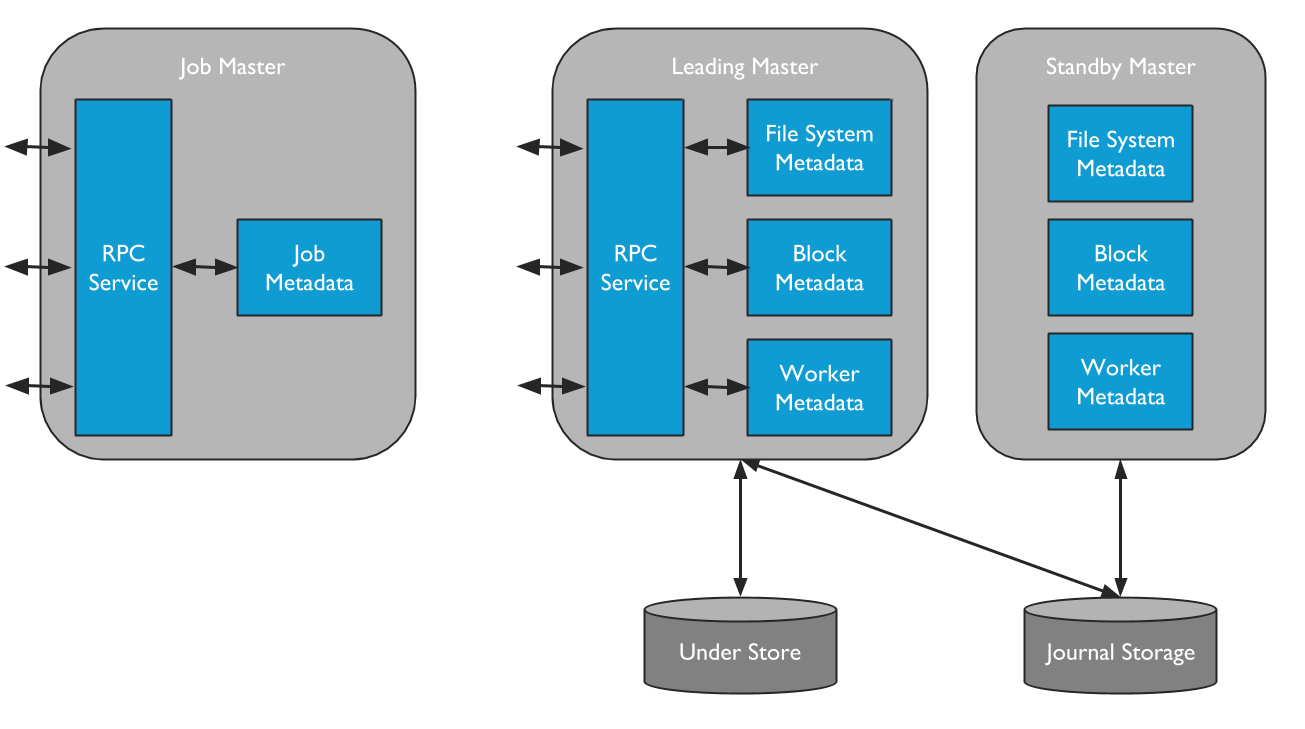
HA集群角色
a).Leading Master
Alluxio集群只能由一个Leading Master进程,Leading Master负责管理系统的全局元数据。包括file system metadata、block metadata 和 worker capacity metadata,Alluxio客户端通过与Leading Master交互来读取或修改元数据。所有的Workers定时向Leading Master发送心跳信息,Leading Master会记录所有的文件操作到日志中
b).Standby Master
Standby Master在运行在与Leading Master不同的服务器上,以便在HA模式下运行Alluxio时提供容错功能。Standby Master会及时同步读取Leading Master的日志。
c).Secondary Master
Alluxio不是HA模式时,可以在Leading Master服务器上启动Secondary Master来编写journals检查点。当Leading Master无法工作时,提供快速服务恢复;但Secondary Master永远不能能做为Standby Master。
d).Job Master
Job Master是一个独立的进程,负责在Alluxio中异步处理一些更重量级的文件系统的操作。
Ⅱ).Workers
Workers负责管理分配给Alluxio用户可配置的本地资源(例如内存,SSD,HDD)。Job Workers做为Alluxio文件系统的客户端,负责执行Job Master给他的任务,将数据存储为block同时响应Client的读写请求;实际的file和block的映射关系保存在Master中。
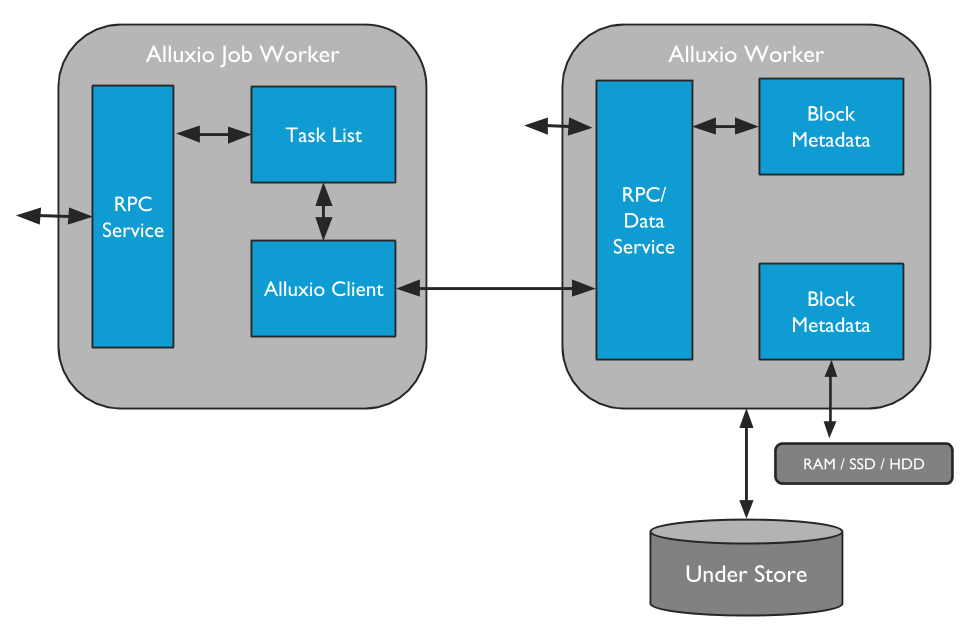
Ⅲ).Client
Alluxio client为用户提供了与Alluxio servers交互的网关。Client先向Leading Master请求元数据信息,再向workers发送读写请求。
三.Alluxio特点
Ⅰ).内存I/O速度
Alluxio可用作分布式共享缓存服务,因此与Alluxio通信的计算应用程序可以透明地缓存经常访问的数据,尤其是来自远程位置的数据,以提供内存中的I/O吞吐量。
Ⅱ).采用简化的云和对象存储
云和对象存储系统使用与传统文件系统相比具有性能影响的不同语义。
Ⅲ).简化数据管理
Alluxio提供对多个数据源的单点访问。除了连接不同类型的数据源之外,Alluxio还使用户能够同时连接到同一存储系统的不同版本,例如多个版本的HDFS,而无需复杂的系统配置和管理。
Ⅳ).简单的应用程序部署
Alluxio管理应用程序与文件或对象存储之间的通信,将数据访问请求从应用程序转换为底层存储接口。Alluxio兼容Hadoop,Spark和MapReduce程序,可以无需修改任何代码在Alluxio之上运行。
三.安装部署
Ⅰ).下载
Ⅱ).安装部署
解压
tar -zxvf alluxio-2.0.0-bin.tar.gz配置
## 复制配置文件
cp alluxio-site.properties.template alluxio-site.properties
## 编辑配置文件
vi alluxio-site.properties
alluxio.master.hostname=hostname
alluxio.master.mount.table.root.ufs=/home/bigdata/alluxio/data
alluxio.worker.tieredstore.level0.dirs.path=/home/bigdata/alluxio/dat初始化
## 验证Alluxio环境
./bin/alluxio validateEnv local
## 格式化Alluxio日志和工作程序存储目录
./bin/alluxio format启停服务
## 启动服务
./bin/alluxio-start.sh local SudoMount
## 停止服务
./bin/alluxio-stop.sh local验证服务
启动日志
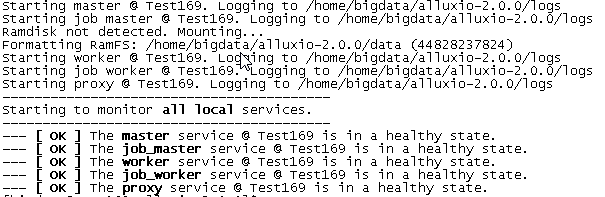
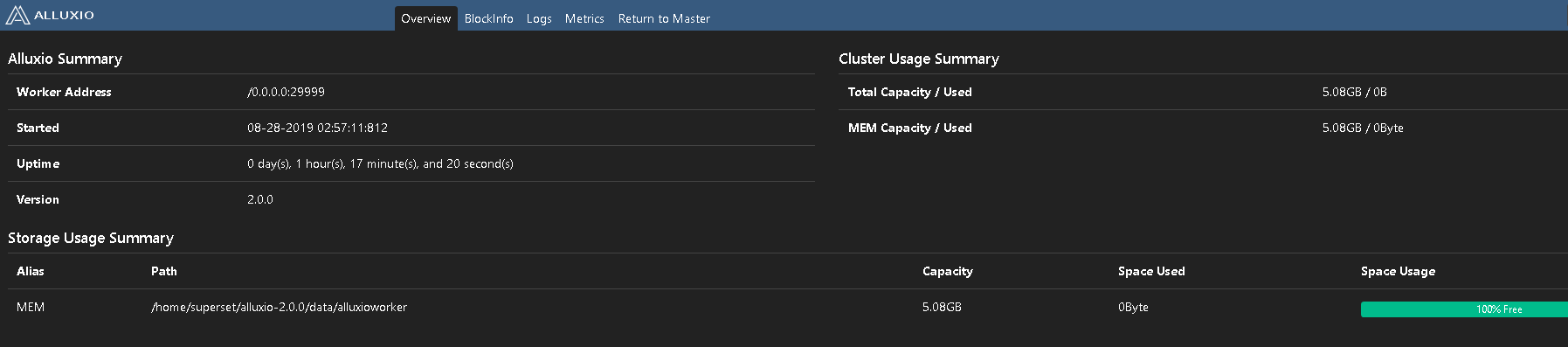
页面
Master url: http://hostname:19999
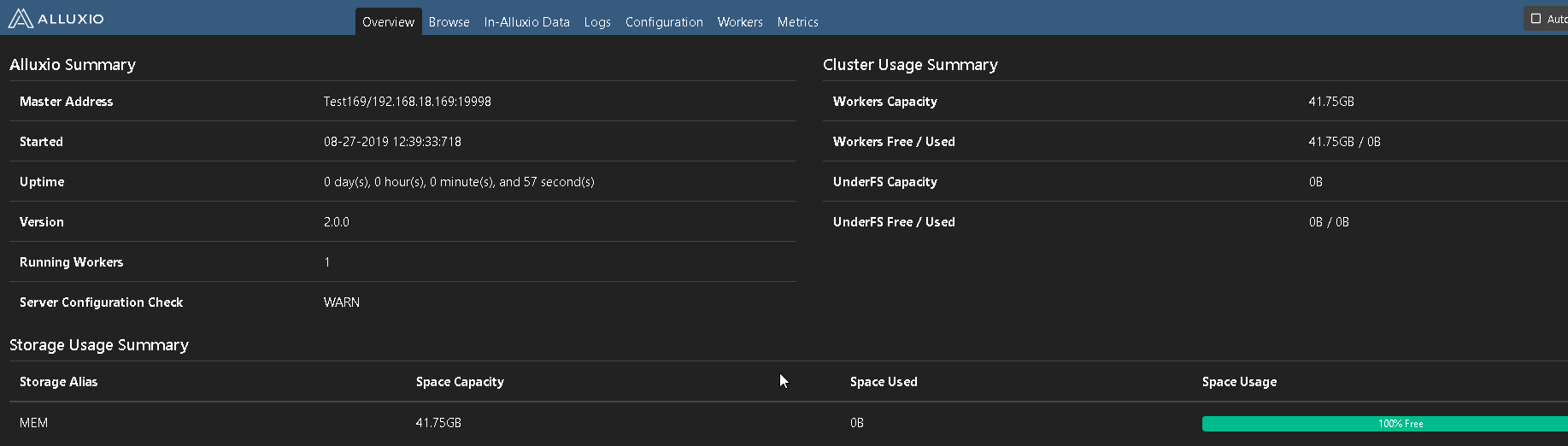
Worker url: http://hostname:30000