前言:
高可用的定义,指的是“一个系统经过特有的设计与改造,减少因不确定故障停服的时间,从而对业务使用方来说可以保证其服务的高度可用性”。在生产环境中,往往会存在很多不可预知的故障因素,比如虚拟机宕机、磁盘损坏和网络故障等,因此系统自身的高可用是任何工业级产品所需重点考虑的因素。
对于消息队列服务来说,考虑到故障切换和业务感知等问题,传统的高可用方式(冷备或者热备)一般都不太适用。在经过多种技术方案对比后,我们发现采用基于 Raft 共识算法的多副本设计方案可以满足我们产品的要求,因此在鉴权认证组件和API计量服务组件中,我们集成了蚂蚁金服开源的 SOFAJRaft 库,实现这两个组件应对单点故障的高可用。
GitHub 地址:
https://github.com/alipay/sofa-jraft
一、背景知识:Raft 共识性算法是什么?
Raft 是一种分布式系统中易于理解的共识算法,该协议本质上是 Paxos 算法的精简版,而不同的是依靠 Raft 模块化的拆分以及更加简化的设计,其实现起来更加容易和方便。[1]
模块化的拆分主要体现在 Raft 把一致性协议划分为如下几部分:
- Leader 选举;
- Membership 变更;
- 日志复制;
- Snapshot。
而更加简化的设计则体现在:Raft 不允许类似 Paxos 中的乱序提交、简化系统中的角色状态(算法定义 Leader、Follower 和 Candidate 三种角色)、限制仅 Leader 可写入、采用随机超时触发 Leader Election 机制来避免“瓜分选票”等等。[2]
1.1 Raft 算法的整体结构概览

从上面的 Raft 算法整体结构图中可以看出,整个分布式系统中同一时刻有且仅有一个 Leader 角色的节点(如图最右边的服务器),只有 Leader 节点可以接受 Client 发送过来的请求。Leader 节点负责主动与所有 Follower 节点进行网络通信(如图左边两个服务器),负责将本地的日志发送给所有 Follower 节点,并收集分布式系统中多数派的 Follower 节点的响应。此外,Leader 节点,还需向所有 Follower 节点主动发送心跳维持领导地位(即:保持存在感)。
所以,只要各个节点上的日志保持内容和顺序是一致的,那么节点上的状态机就能以相同的顺序执行相同的命令,这样它们执行的结果也都是一样的。
1.2 Raft算法的三个角色及转换
(1) Follower:完全被动,不能发送任何请求,只接受并响应来自 Leader 和 Candidate 的 Message,每个节点启动后的初始状态一般都是 Follower;
(2)Leader:处理所有来自客户端的请求、复制 Log 到所有 Follower,并且与 Follower 保持心跳请求;
(3)Candidate:节点竞选 Leader 时的状态。Follower 节点在参与选举之前,会将自己的状态转换为 Candidate。

1.3 任期与逻辑时钟概念

**
(1)时间被划分为多个任期 term(如同总统选举一样),term id 按时间轴单调递增;
(2)每一个任期开始后要做的第一件事都是选举 Leader 节点,选举成功之后,Leader 负责在该任期内管理整个分布式集群,“日志复制”、“通过心跳维护自己的角色”;
(3)每个任期至多只有一个 Leader 节点,也可能没有 Leader (由于“分票”导致)。
1.4 Raft 算法的实际应用实现
目前,Raft 算法已经成熟地应用于诸多知名的开源项目中。业界非常著名的 Etcd(Kubernetes 高可用强一致性的服务发现组件)和 TiKV (高性能开源 KV 存储)均是 Raft 算法的实现。
二、BC-MQ 基于 Raft 的高可用设计
为满足企业上云和构建万物相连的物联网业务需求,中国移动苏州研发中心结合自身在云计算产品和技术的较多积累,研发了大云消息队列中间件产品 BC-MQ。该产品基于 Apache 开源社区的 RocketMQ 内核,同时结合云端 PAAS 产品架构和消息中间件的应用业务需求进行深度优化和定制化的研发,提供了一款可以满足于云端场景的高性能、高可靠、低延迟和高可用的工业级产品。
本节从解决原有高可用技术方案的问题视角出发,同时结合选型 SOFAJRaft 库的缘由,将详细阐述 BC-MQ 产品中的安全认证和 API 计量采集服务的高可用设计方案(注:这里不会涉及到安全认证和 API 计量采集组件本身的技术方案细节)。
2.1 GlusterFS+Keepalived 高可用方案与问题
1. GlusterFS+Keepalived 高可用设计方案
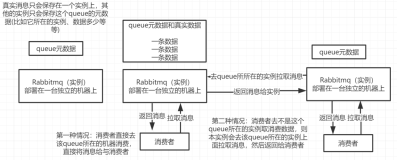
在BC-MQ原有的方案中,多组安全认证服务各自独立部署组建集群,各个安全认证服务相互独立,没有主从关联,服务本身无状态,可水平任意扩展。安全认证服务的高可用依赖于RPC通信的客户端保证,其主要通过负载均衡算法从安全认证服务集群选择一个节点发送RPC请求来实现租户级鉴权认证元数据的获取。在生产环境中,如果出现其中一个安全认证节点宕机不可用时,客户端的RPC通信层能够及时感知并从本地的Node列表中剔除不可用节点。
集群中有状态的租户级安全认证元数据的强一致性由GlusterFS分布式文件存储的同步机制来保证。安全认证服务组建高可用集群的具体设计方案图如下所示:体设计方案图如下所示:
而BC-MQ中API计量采集服务组件的高可用性则是依靠Keepalived组件的冷备模式结合GlusterFS分布式文件存储的同步机制共同保证,从而在一定程度上解决了API计量采集服务的单点不可用问题。API计量采集服务的具体高可用设计方案图如下所示:
2. GlusterFS+Keepalived 高可用方案遇到的问题
初步看上面的这种高可用技术方案挺完美的。但是经过验证和仔细推敲后就发现在生产环境中可能会存在如下几个问题:
- 上面所述的高可用设计方案中引入了GlusterFS分布式文件存储系统和Keepalived组件,这增加了系统整体的运维复杂度,给运维人员带来很多人工介入排查和部署的工作负担;另一方面,GlusterFS和Keepalived本身的可靠性、稳定性和性能指标等问题也需要软件研发人员重点关注,这增加了系统整体设计的复杂度;
- 在实际的生产环境中,Keepalived组件采用冷备方式作为高可用方案需要考虑主机故障宕机后切换到备机的时间成本消耗。在这段时间内,API计量服务是短暂不可用的。因此,Keepalived组件的主备切换会造成业务感知影响,导致一些业务的风险发生。
2.2 基于 SOFAJRaft 库的高可用设计方案
由于“GlusterFS+Keepalived”的高可用方案存在上一节阐述的两个问题,所以我们考虑是否可以采用其他的高可用方案来解决这两个问题?目标:即使生产环境出现部分节点故障后,安全认证和API计量组件依旧能够正常提供服务,做到业务无感知。
为了实现当分布式集群中的部分节点出现故障停服后,集群仍然能够自动选主继续正常对外提供服务,使得故障对外部业务不会产生任何影响,同时高可用方案又不能依赖外部系统,那我们也就想到了Raft算法。Raft算法设计,简洁易懂,没有任何外部依赖,可以完成一个高可靠、高可用、强一致的数据复制系统,解决我们前面遇到的问题。
业界有一些Raft算法的实现,目前比较流行的主要有百度开源的Braft和蚂蚁金服开源的SOFAJRaft。从官方github上对两款开源Raft实现框架支持的功能和特性来看,基本相近,但Braft是C/C++语言实现的,而SOFAJRaft是JAVA语言实现的,因此我们从技术栈、集成难易和运维成本等角度综合考虑,最终选择了SOFAJRaft。
1. 为何技术选型 SOFAJRaft 库?
SOFAJRaft 是一个基于 Raft 一致性算法的生产级高性能 JAVA 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。使用 SOFAJRaft,使用者可以更加专注于自己的业务领域,由 SOFAJRaft 负责处理所有与 Raft 算法相关的技术难题,并且 SOFAJRaft 比较易于使用,用户可以通过 Github 上的几个示例在很短的时间内掌握并使用它。下面先简单介绍下 SOFAJRaft 的特性和增强功能点:
其中:
- Membership change 成员管理:集群内成员的加入和退出不会影响集群对外提供服务。
- Transfer leader:除了集群根据算法自动选出 Leader 之外,还支持通过指令强制指定一个节点成为 Leader。
- Fault tolerance 容错性:当集群内有节点因为各种原因不能正常运行时,不会影响整个集群的正常工作。
- 多数派故障恢复:当集群内半数以上的节点都不能正常服务的时候,正常的做法是等待集群自动恢复,不过 SOFAJRaft 也提供了 Reset 的指令,可以让整个集群立即重建。
- Metrics:SOFAJRaft 内置了基于 Metrics 类库的性能指标统计,具有丰富的性能统计指标,利用这些指标数据可以帮助用户更容易找出系统性能瓶颈。

为了提供支持生产环境运行的高性能,SOFAJRaft主要做了如下几部分的性能优化,其中:
- 并行append log:在 SOFAJRaft中 Leader本地持久化 Log 和向 Follower发送 Log 是并行的。
- 并发复制 Leader 向所有 Follwers 发送 Log 也是完全相互独立和并发的。
- 异步化:SOFAJRaft中整个链路几乎没有任何阻塞,完全异步的,是一个完全的 Callback 编程模型。
因此,综上所述我们最终选用SOFAJRaft的理由如下:
- SOFAJRaft基于JAVA实现,能够很方便的与BC-MQ中安全认证服务和API计量服务组件进行集成。
- SOFAJRaft作为一个实现Raft协议的框架,提供了易于实现的状态机接口,只需要实现它提供的接口即可完成高可用的改造。
- 从实际的验证结果来说,SOFAJRaft的性能和稳定性能够完全满足甚至超过我们的预期。
- SOFAJRaft的功能性能够解决上面篇幅中BC-MQ原有“GlusterFS+Keepalived”高可用方案中所遇到的问题。
2. BC-MQ 组件集成 SOFAJRaft 的优化设计
BC-MQ在集成SOFAJRaft库后在部署架构、数据持久化和高可用模式上都进行了能力升级,较好地解决了“GlusterFS+Keepalived”中的问题。
1.部署架构:集成SOFAJRaft库后,BC-MQ的安全认证和API计量服务的高可用部署不再依赖“GlusterFS+Keepalived”这两个外部组件;安全认证和API计量服务组件按照配置文件独立部署组成相应的RaftGroup即可对外提供服务;
2.数据持久化:数据的强一致性不再依赖“GlusterFS分布式文件存储”。通过SOFAJRaft的日志复制和状态机,实现集群中Leader节点和Follower节点的数据同步保证主备节点的数据一致性;
3.高可用模式:从原有的“KeepaLived冷备切换”转变为“Raft自动Leader选举”,发生故障后,API计量服务仍然能够对外正常提供服务,故障转移的过程无需运维人员介入。
组件服务端的状态机接口实现
针对具体的业务应用而言(对 BC-MQ 来说,就是 API 计量统计和安全认证鉴权),状态机(StateMachine)是业务逻辑实现的主要接口,状态机运行在每个Raft节点上,提交的 任务 Task 如果成功,最终都会复制应用到分布式集群中的每个节点的状态机上。
在 SOFAJRaft 中提供了一个已经具备绝大部分默认实现的抽象适配类— StateMachineAdapter,直接继承它可以使得业务应用避免实现所有的接口。我们根据 BC-MQ 组件改造的需求,对部分接口做了如下的实现:
1. void onApply(Iterator iter):该方法是 SOFAJRaft 中最为核心的接口。在整个分布式集群环境中,待同步的数据会封装成 LogEntry 复制到其他节点。在数据同步完成之后,进程会提交到自身状态机的这个方法中执行。在 BC-MQ 中,API 计量采集服务在计量统计数据日志同步至 Follower 节点后,SOFAJRaft 在业务状态机的 onApply 方法中调用 API 计量采集服务组件的存储接口进行持久化。
2. void onLeaderStart(long term)/void onLeaderStop(Status status):这个两个方法是在节点通过选举成为 Leader 和失去 Leader 资格时调用,BC-MQ 的安全认证和 API 计量服务组件本身也维护了 Raft 的角色状态(这里的角色状态与 SOFAJRaft 本身的是保持一致的)。在节点的角色发生转变的时候,需要调用这个方法,将组件的角色和状态转变一致。这样实现主要是与 BC-MQ 的业务场景相关,在集群中经过重新选举后节点角色转变时,只有API 计量组件服务的 Leader 节点才能够执行消息队列的 API 计量采集相关的定时任务。
3. void onSnapshotSave(SnapshotWriter writer, Closure done)/boolean onSnapshotLoad(SnapshotReader reader):这两个方法是 SOFAJRaft 快照相关的接口调用,快照本身的作用就是在有新的节点加入到 SOFAJRaft Group 时,不需要加载全部的 Log 日志数据,而只需要从最近的 index 开始加载,这可以节省从 Leader 节点同步大量日志信息所造成的网络通信开销。BC-MQ 的安全认证和 API 计量采集服务组件实现了这两个方法,用于实现快照的特性。
客户端请求重定向机制优化
SOFAJRaft 中默认只有 Leader 节点能够被客户端访问到,所有的日志提交都需要先提交到集群的 Leader 节点,然后由Leader节点同步到其他的 Follower 节点。BC-MQ 的安全认证服务和 API 计量服务组件通过 SOFAJRaft 改造后,在 BC-MQ 中原有的客户端 RPC 请求访问方式也需要经过一些优化设计,为了让客户端能够实时感知到分布式集群环境中当前的 Leader 节点,因此需要在客户端缓存一个集群的节点列表 NodeList 和 LeaderId。
仅仅在客户端维护一个本地缓存还不够,因为如果集群中的 Leader 节点出现了宕机的故障时,集群会发生重新选举,那么客户端缓存的 Leader 节点信息就会过期,这就需要客户端就能够感知到 Leader 节点的变化。为解决这个问题,我们采用了 RPC 请求重定向机制来保证,一旦RPC请求发送到了集群中的 Follower 节点,那么 Follower 会将该请求重定向到 Leader。以下为 BC-MQ 客户端通信重定向机制优化设计图:
三、BC-MQ 的高可用与节点管理性验证
下面展示的是 BC-MQ 的安全认证服务和 API 计量服务组件的部分测试用例,从用例的实际执行情况来看,与我们的预期结果完全一致可以满足生产环境高可用的业务场景。
| 序号 | 具体业务场景 | 预期结果 | 实际结果 |
|---|---|---|---|
| 1 | 安全认证组件3节点部署,Kill掉其中1个节点,客户端持续发布/订阅带鉴权的消息 | 安全认证组件Leader角色转换,客户端发布/订阅带鉴权消息无任何影响 | 与预期一致 |
| 2 | 安全认证的5节点部署,Kill掉其中2个节点,客户端持续发布/订阅带鉴权的消息 | 安全认证组件Leader角色转换,客户端发布/订阅带鉴权消息无任何影响 | 与预期一致 |
| 3 | API计量组件3节点部署,Kill掉其1个节点,客户端持续;发布/订阅带鉴权的消息 | API计量组件Leader角色转换,输出的API计量文件正确 | 与预期一致 |
| 4 | API计量组件5节点部署,Kill掉其2个节点,客户端持续发布/订阅带鉴权的消息 | API计量组件Leader角色转换,输出的API计量文件正确 | 与预期一致 |
| 5 | 在集群中模拟出现网络分区(对称/非对称)的场景,安全认证服务集群是否会出现脑裂现象,鉴权认证数据是否正确 | 网络分区(对称/非对称)场景下,集群不会出现脑裂,并且鉴权数据是正确的 | 与预期一致 |
| 6 | 在集群中模拟出现网络分区(对称/非对称)的场景,API计量服务集群是否会出现脑裂现象,API计量数据是否正确 | 网络分区(对称/非对称)场景下,集群不会出现脑裂,并且API计量数据是正确的 | 与预期一致 |
| 7 | 在3节点组成的安全认证服务集群的负载工作的场景下,向该RaftGroup添加1/2节点,客户端持续发布/订阅带鉴权的消息 | 客户端发布/订阅带鉴权消息无任何影响 | 与预期一致 |
| 8 | 在5节点组成的安全认证服务集群的负载工作的场景下,移除该RaftGroup中的1/2节点,客户端持续发布/订阅带鉴权的消息 | 客户端发布/订阅带鉴权消息无任何影响 | 与预期一致 |
四、总结
本文主要介绍了中国移动苏州研发中心自主研发的 BC-MQ 产品中两个重要组件—安全认证和 API 计量服务是如何通过集成开源的 SOFAJRaft 库解决原来“GlusterFS+Keepalived”高可用方案中遇到的问题,以实现大规模消息队列云服务集群的高可用部署优化方案。由于文章篇幅的原因,本文没有对 BC-MQ 本身多项重要的特性进行详细介绍,作者将在后续的文章中继续进行阐述。同时,限于笔者的才疏学浅,对本文内容可能还有理解不到位的地方,如有阐述不合理之处还望留言一起探讨。
五、参考文献
[]()[1] Diego Ongaro and John Ousterhout. Raft Paper. 2013
[]()[2] https://mp.weixin.qq.com/s/zDusnG6WJGP0EX8UmbqtxQ
作者介绍:
胡宗棠,中国移动苏州研发中心云计算中间件团队负责人,Apache RocketMQ Committer,Linux OpenMessaging Advisory Borad Member,SOFAJRaft Contributor,熟悉分布式消息中间件的设计原理、架构以及各种应用场景。