本篇分享一个hanlp分词工具应用的案例,简单来说就是做一图库,让商家轻松方便的配置商品的图片,最好是可以一键完成配置的。
先看一下效果图吧:

商品单个推荐效果:匹配度高的放在最前面

这个想法很好,那怎么实现了。分析了一下解决方案步骤:
1、图库建设:至少要有图片吧,图片肯定要有关联的商品名称、商品类别、商品规格、关键字等信息。
2、商品分词算法:由于商品名称是商家自己设置的,不是规范的,所以不可能完全匹配,要有好的分词库来找出关键字。还有一点,分词库要能够自定义词库,最好能动态添加。如果读者不知道什么是分词,请自行百度,本文不普及这个。
3、推荐匹配度算法:肯定要最匹配的放在前面,而且要有匹配度分数。商家肯定有图库没有的商品,自动匹配的时候,不能随便配置不相关的图片。
先说明一下,本文企业没有搜索引擎之类的工具,所以本质就靠的是数据库检索。
首页让我们先分析一下图库,下面是图库的设置界面。

让我们先贴一下图库的表结构
CREATE TABLE wj_tbl_gallery (gallery_id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',fileid int(11) NOT NULL COMMENT '文件服务器上的文件ID',ptype tinyint(4) NOT NULL DEFAULT '0' COMMENT '图片类型,0 点歌屏点餐图片',materialsort varchar(50) DEFAULT NULL COMMENT '商品分类',materialbrand varchar(50) DEFAULT NULL COMMENT '商品品牌',materialname varchar(100) NOT NULL COMMENT '商品名称',material_spec varchar(50) DEFAULT NULL COMMENT '商品规格',material_allname varchar(200) DEFAULT NULL COMMENT '商品完整名称',status tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态,0正常,1停用,2删除',updatedatetime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',keyword varchar(200) DEFAULT NULL COMMENT '商品关键字,用逗号隔开',bstorage tinyint(4) NOT NULL DEFAULT '0' COMMENT '关键字是否入库 0没有,1有',
PRIMARY KEY (gallery_id),
KEY idx_fileid (fileid)
) ENGINE=InnoDB AUTO_INCREMENT=435 DEFAULT CHARSET=utf8 COMMENT='图库信息表';
数据示例:

简单说一下material_allname是干什么用的呢,主要就是拼接商品名称、规则 、关键字字段。用来写sql的时候比较方便。关键字字段是干什么用的呢,作用有两个。1是商品可能有多个名字,补充名称的。二是给分词库动态添加词库。图库简单说到这。
再说一下分词库,笔者选择的是开源的汉语言分词库-hanlp分词工具
优点是词库大,有词性分析,可以自定义词库。缺点当然也有,就是不支持数据库方法动态读取词库。后面说一下我自己的解决办法。
上代码:
分词代码,这时差会去掉一些没用字符。

我们分词,就是调用SegmentUtils.segmentTerm(materialname);
动态添加词库方法:
private void addCustomerDictory(){
Integer max = galleryRepository.getMaxGallery();
if(CommonUtils.isNotEmpty(max) && max > 0 && max > SegmentUtils.CACHE_GALLERY_ID){
int oldid = SegmentUtils.CACHE_GALLERY_ID;
SegmentUtils.CACHE_GALLERY_ID = max;
List<String> gallery = galleryRepository.getGallery(oldid,max);
if(CommonUtils.isNotEmpty(gallery)){
Map<String,Boolean> dicMap = new HashMap<>();
for(String w : gallery){
if(CommonUtils.isNotEmpty(w)){
String[] array = w.split(",");
if(CommonUtils.isNotEmpty(array)){
for(String item : array){
String value = item.trim();
if(CommonUtils.isNotEmpty(value)){
dicMap.put(value, true);
}
}
}
}
}
Set<String> keys = dicMap.keySet();
if(CommonUtils.isNotEmpty(keys)){
SegmentUtils.insertCustomDictory(keys);
}
}
}
}
/**
* 获取关键字
*
* @author deng
* @date 2019年3月13日
* @param galleryId
* @return
*/
@Query("select keyword from Gallery a where galleryId > ?1 and galleryId<=?2 and a.keyword !='' and bstorage=0")
public List<String> getGallery(int bgalleryId, int egalleryId);
@Cacheable(value = CacheConstants.CACHE_GALLERY, keyGenerator = CacheConstants.KEY_GENERATOR_METHOD)
@Query(value = "select gallery_id from wj_tbl_gallery a where a.keyword !='' and bstorage=0 order by gallery_id desc limit 1", nativeQuery = true)
public Integer getMaxGallery();
说一下解决思路,由于hanlp文档上没有看到从mysql上动态添加词库方法,只有CustomDictionary.insert能动态添加单个实例词库,系统如果重启,就要重新添加。我就想出一个办法,就是分词的时候,查一下类的保存的最大图库表的主键是什么,如果跟数据库一样,就不动态添加。如果小于图库的主键,就把没有的那一段用CustomDictionary.insert添加进去。系统一般不重启,如果重启就在分词的时候重新添加一下。查询数据库当然都有缓存,编辑图库的时候,把对应缓存清除一下。这种方式也能支持分布式环境,多个实例都是一样处理的。每过一段时间,就把图库表的关键字词库搞成文件的词库,避免动态添加太多,占用太多内存。自定义词库其实是很重要的,任何分词库都不可能包含所有的词库,而分词算法是根据词库来展开的,可以说词库决定了分词结果的准确性。
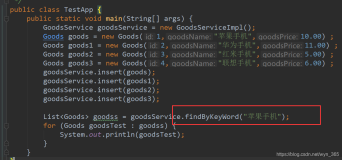
让我们看一下分词的效果
商品名称为”雪碧(大)“的分词结果 雪碧/nz, 大/a ,其中nz表示专有词汇,a表示形容词。
再看一下不理想的分词结果:
商品品名称:”蕾芙曼金棕色啤酒“,类别名称:啤酒,
分词结果:蕾/ng,芙/n,曼/ag,金/ng,棕色/n,啤酒/nz
很明显,分词结果不理想,蕾芙曼金棕色其实是一个商品名,不能分开。怎么办呢,这时候动态添加词汇功能就派上用场了。
再图库关键字时差添加蕾芙曼金棕色啤酒,保存一下,再看一下分词效果:

物品名称:蕾芙曼金棕色啤酒,类别名称:啤酒,分词结果:蕾芙曼金棕色/nz,啤酒/nz
蕾芙曼金棕色被分到了一起,达到预期效果,这其实就是 CustomDictionary.insert(data, "nz 1024");再起作用。hanlp具体API功能,请参考官方文档,本文就不介绍了。
最后重头戏来了,商品图片匹配度分析。作者就是采用了mysql的sql词句的方法搞定了,其实就用到了LOCATE函数,很简单。SQL示例如下
SELECT gallery_id, fileid, materialname, material_allname, score
, ROUND(score / 4 * 100, 0) AS rateFROM (
SELECT a.gallery_id, a.fileid, materialname, material_allname
, IF(LOCATE('雪碧', a.material_allname), 2, 0) + IF(LOCATE('大', a.material_allname), 1, 0) + IF(LOCATE('饮料', a.material_allname), 1, 0) AS score
FROM wj_tbl_gallery a
WHERE a.STATUS = 0
AND (a.material_allname LIKE '%雪碧%'
OR a.material_allname LIKE '%大%'
OR a.material_allname LIKE '%饮料%')) b
ORDER BY score DESC, materialname
LIMIT 0, 8
执行结果:

可以看出gallery_id是第一条,它的rate的是75,满分是100,匹配度蛮高的。
说一下匹配度算法原则,如果完全匹配就是1百分,肯定就上了。然后去除某些关键字后,也匹配上了就是90分。最后采用分词算法,按照1百分打分,其中如果高于50分,可以算基本匹配,自动配置图片的时候,就可以当成匹配成功。总体原则就是匹配词汇越多,分数越多。但是两个字的词汇,和5个字的词汇,分数是不一样的。还有词性,专属词汇理论上应该比形容词分数高。详见下面的calculateWeight代码,自己体会了。
public List> queryList(String searchstr, int pagenumber, int pagesize, String materialsortname,
List<Term> segmentList) {
String name = "%" + searchstr + "%";
// 先简单搜索 ,完全匹配100分
List<Map<String, Object>> list = queryList(name, pagenumber, pagesize, 100);
if (CommonUtils.isEmpty(list)) {
searchstr = searchstr.replaceAll("\\s", "");
String regEx = "(特价)|(/)|(\\()|(\\))|(()|())|(\\d+ml)|(买.送.)|(/)|(\\*)";
searchstr = searchstr.replaceAll(regEx, "");
if (CommonUtils.isNotEmpty(searchstr)) {
name = "%" + searchstr + "%";
// 简单过滤 90分
list = queryList(name, pagenumber, pagesize, 90);
}
// 剩下分词 靠计算
if (CommonUtils.isEmpty(list)) {
if (CommonUtils.isNotEmpty(segmentList)) {
list = queryListTerm(pagenumber, pagesize, segmentList, materialsortname);
}
// 如果只有分类,先定10分
else if (CommonUtils.isNotEmpty(materialsortname))
list = queryList(materialsortname, pagenumber, pagesize, 10);
}
}
return list;
}
private List<Map<String, Object>> queryList(String name, int pagenumber, int pagesize, int rate) {
String sql = "SELECT\n" + " a.gallery_id,\n" + " a.fileid,a.material_allname,a.materialname \n, " + rate
+ " rate FROM\n" + " wj_tbl_gallery a\n" + "WHERE\n"
+ " a.material_allname LIKE :searchstr and a.status = 0 order by length(materialname) LIMIT :pagenumber,:pagesize ";
Dto param = new BaseDto();
param.put("searchstr", name).put("pagenumber", pagenumber * pagesize).put("pagesize", pagesize);
return namedParameterJdbcTemplate.queryForList(sql, param);
private List<Map<String, Object>> queryListTerm(int pagenumber, int pagesize, List<Term> segmentList,
String materialsortname) {
Dto param = new BaseDto();
StringBuffer sb = new StringBuffer();
StringBuffer wsb = new StringBuffer(" (");
// 总权重
int tw = 0;
if (CommonUtils.isNotEmpty(segmentList)) {
for (int i = 0; i < segmentList.size(); i++) {
String str = segmentList.get(i).word;
int w = SegmentUtils.calculateWeight(segmentList.get(i));
str = StringUtils.escapeMysqlSpecialChar(str);
tw += w;
sb.append("if(LOCATE('").append(str).append("', a.material_allname),").append(w).append(",0) ");
wsb.append(" a.material_allname like '%").append(str).append("%' ");
if (i < segmentList.size() - 1) {
sb.append(" + ");
wsb.append(" or ");
}
}
// 类别单独处理,目前权重较低
// 表示字符串是否为空
int emptylen = 3;
if (CommonUtils.isNotEmpty(materialsortname)) {
if (sb.length() > emptylen) {
sb.append(" + ");
wsb.append(" or ");
}
tw += SegmentUtils.DWEIGHT;
materialsortname = StringUtils.escapeMysqlSpecialChar(materialsortname);
sb.append(" if(LOCATE('").append(materialsortname).append("', a.material_allname),")
.append(SegmentUtils.DWEIGHT).append(",0) ");
wsb.append(" a.material_allname like '%").append(materialsortname)
.append("%' ");
}
if (sb.length() > emptylen) {
sb.append(" as score ");
wsb.append(") ");
String scoreSelect = sb.toString();
String scorewhere = wsb.toString();
String sql = "select gallery_id,fileid,materialname,material_allname,score,ROUND(score/" + tw
+ "*100, 0) rate from (SELECT " + " a.gallery_id, "
+ " a.fileid,materialname,material_allname, " + scoreSelect + " FROM "
+ " wj_tbl_gallery a " + "WHERE " + " a.status = 0 and " + scorewhere
+ " ) b order by score desc ,materialname LIMIT " + pagenumber * pagesize + "," + pagesize;
param.put("pagenumber", pagenumber * pagesize).put("pagesize", pagesize);
logger.debug("商家搜索图库的SQL语句是{}", sql);
List<Map<String, Object>> list = namedParameterJdbcTemplate.queryForList(sql, param);
if (CommonUtils.isNotEmpty(list)) {
return list;
}
}
}
/**
* 计算分词权重
* @author deng
* @date 2019年6月21日
* @param term
* @return
*/
public static int calculateWeight(Term term) {
// 汉字数
int num = countChinese(term.word);
// 大于3个汉字,权重增加
int value = num >= 3 ? 2 + (num - 3) / 2 : DWEIGHT;
// 专属词,如果有两个字至少要最小分是2分
if (term.nature == Nature.nz && value <= DWEIGHT) {
value = DWEIGHT + 1;
}
return value;
}总结一下,本文介绍的商品图片推荐和自动匹配方法,可以看出来是相当简单的,本质就是mysql的like%% 优化来的,依赖sql语句和hanlp分词库,做法简单,但是能满足专门商品的匹配,适合小图库。自然比不上大公司搞的搜索引擎来的效率高,仅供参考。



![推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐](https://ucc.alicdn.com/images/user-upload-01/4bb7aa49561c48a182a410713ddfb1f9.png?x-oss-process=image/resize,h_160,m_lfit)