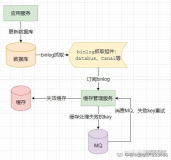
分库分表,做到永不迁移数据和避免热点的方法:
基础:
1、数据拆分方式:垂直拆分,水平拆分。
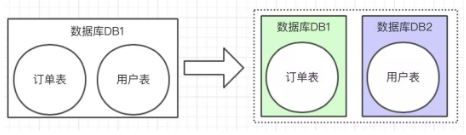
2、垂直拆分:原来就一个数据库,数据量一大了,就拆分为多个数据库。
3、水平拆分:原来是t_order表,拆分成t_order_1、t_order_2、t_order_3、t_order_4。
4、Mysql单表存储推荐是百万级,尽量别到千万级。
分库分表方案:
1、常用的方案:hash取模、range范围方案,分库分表方案最主要的就是路由算法,把路由的key按照指定的算法进行路由存放。
2、hash取模方案(无热点问题,扩容困难)
(一)、首先预估一下总数据量m,设定每张表的最大数据量n,m/n=z 是表个数。
(二)、hash方案就是对指定的路由key(如:id)对z进行取模,"t_order_"+id%z 是表名字。
(三)、优缺点:优点是数据均匀的分布在每张表中,不会有热点问题;缺点是数据的迁移或者扩容会很麻烦。
3、range范围方案(不需要迁移数据,有热点问题)
(一)、range方案是以范围进行数据拆分:id=50在0~1000的在t_order_0表、id=1050在1000~2000的t_order_1表等。
(二)、优缺点:优点是扩容方便,不需要数据迁移;缺点是id在0-1000时,t_order_0会很忙,t_order_1,t_order_2...t_order_n...都没有数据的访问,一段时间只有一个热点表。
4、range和hash组合方案
(一)、设计是比较简单的,就三张表,把group,db,table之间建立好关联关系。
group表字段:group_id,group_name,start_id,end_id
db表字段:db_id,db_name,group_id,hash_value
group和db的关系表字段:table_id,table_name,db_id,start_id,end_id
分库分表就会带来各种join组合条件的分页查询问题,怎样解决分页查询问题,很有挑战性。
1.事务问题:
(1)、分布式事务 (2)、通过应用程序与数据库共同控制实现事务
方案一:使用分布式事务
优点:交由数据库管理,简单有效
缺点:性能代价高,特别是shard(分片)越来越多时
方案二:由应用程序和数据库共同控制
原理:将一个跨多个数据库的分布式事务分拆成多个仅处
于单个数据库上面的小事务,并通过应用程序来总控
各个小事务。
优点:性能上有优势
缺点:需要应用程序在事务控制上做灵活设计。如果使用
了spring的事务管理,改动起来会面临一定的困难。
2.跨节点Join的问题
只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。
3.跨节点的count,order by,group by以及聚合函数问题这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。
解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。