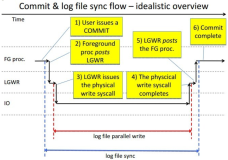
Write-Ahead Logging (WAL)是保证数据完整性的标准方法,在大多数关于事务处理的书中都可以找到详细的描述。
简单的说,WAL的核心思想是确保数据文件的更改必须在这些更改被写入日志之后才能进行。
遵循这个原则,就不需要在每个事物中将数据刷新到磁盘提交。因为在发生崩溃时,我们能够使用日志,将没有写入到磁盘的任何更改从日志记录中重新执行(这是前滚恢复,也称为重做)。
PG数据库中有很多WAL相关的参数,通过正确的配置能够提高数据库的性能。
检查点
检查点与WAL有密不可分的联系。
检查点是事务序列中的点,在这些事务序列中,需要保证表和索引数据文件已经使用检查点之前的所有信息进行了更新。
在检查点发生时,将所有脏数据页刷新到磁盘,并将一个特殊的检查点记录写入日志文件。(更改记录以前被刷新到WAL文件中。)
min_wal_size、max_wal_size
在PostgreSQL 10以前版本中存在的checkpoint_segments参数已经消失,原意是指在日志文件段数量达到设置的最大值时,触发检查点。
原来是通过参数checkpoint_segments来直接指定的,而现在通过如下方式计算。(来自网络)
target = (double) max_wal_size / (2.0 + CheckPointCompletionTarget);
/* round down */
CheckPointSegments = (int) target;
if (CheckPointSegments < 1)
CheckPointSegments = 1;CheckPoint_Completion_Target 取值范围是 (0.0,1.0)
所以最终CheckPoint_Segments得到的值范围是 max_wal_size 的 1/3 ~ 1/2
现在CheckPoint_Segments已经不存在,但是通过两个参数计算的结果可以得出,在pg_wal文件数量超过max_wal_size 1/3~1/2的时候,仍然会触发检查点。
触发检查点的方式
服务器的checkpointer进程会自动执行检查点。
- checkpoint_timeout,当达到该参数的时间时,自动触发检查点
- max_wal_size,当数据量将超过该参数配置的最大值时,自动触发检查点
- 当pg_wal目录下日志文件段的数量超过一定数量时
- 手工执行CHECKPOINT命令
checkpoint_timeout,max_wal_size两个参数的默认配置分别是5分钟和1GB。哪个先满足条件,先触发执行检查点。
降低checkpoint_timeout或者max_wal_size的大小,会使检查点执行的频率更高。
检查点的执行对数据库来说是“相当昂贵”的,首先是因为写出当前所有脏缓冲区会对IO造成冲击。其次,如果配置了参数full_page_writes ,它们会导致额外WAL读写压力。
full_page_writes (boolean)
当启用此参数时,PostgreSQL服务器将在检查点之后第一次修改该页时将每个磁盘页的全部内容写入WAL.
有时这是必需的,因为在操作系统崩溃期间正在进行的读写操作可能只完成了部分,从而导致磁盘上的页面包含新旧数据的混合。
通常存储在WAL中的行级更改数据不足以在崩溃后完全恢复,存储完整的页面镜像可以确保这点;
但这是以增加写入WAL的数据量为代价的。
checkpoint_warning
当检查点过于频繁,两个检查点的时间间隔少于参数checkpoint_warning设置的时间时,则会向服务器日志输出一条消息,建议增加max_wal_size。
2019-07-23 04:55:45.818 UTC [2185] LOG: checkpoints are occurring too frequently (24 seconds apart)
2019-07-23 04:55:45.818 UTC [2185] HINT: Consider increasing the configuration parameter "max_wal_size".checkpoint_completion_target
为了避免大量的页面写操作增加IO负载,检查点期间写脏缓冲区的操作要分散在一段时间内。这个周期由checkpoint_completion_target参数控制。
场景1:
•checkpoint_completion_target=0.5
•checkpoint_timeout = 5min
•00G数据(需要刷进磁盘的数据量)
•1G/s
•100/(0.5*5*60)*1024≈670M/s (数据写入速度)
场景2:
•checkpoint_completion_target=0.9
•checkpoint_timeout = 5min
•100G数据
•1G/s
•100/(0.9560)*1024≈380M/s
一般服务器写入速度为500M/s-1200M/s,checkpoint_completion_target设置的越高的情况下,写入速度越低,对整体性能的影响越小。反之,较低的值可能会引起I/O峰值,导致“卡死”的现象。
在同一时间通过检查点,将所有脏数据页刷新到磁盘,会导致显著增加I/O的负载。因此,对检查点活动进行节流,确保I/O从检查点从开始到完成是在下一个检查点开始前。这将有效改善检查点期间的性能下降。
wal_segment_size 日志文件段的大小
pg_wal目录下的文件大小,由该参数决定。该参数只能在initdb时指定
默认值为16MB
pg_wal目录中wal段文件的个数
pg_wal目录中的WAL段文件的数量取决于min_wal_size、max_wal_size和以前检查点周期中生成的WAL的数量。
可以简单理解为,当服务器不繁忙时,文件个数处于一定个数,并循环使用。
即便使用 select pg_switch_wal();命令,也不会增加文件的个数。
但是当存在大量插入操作的时候,由于没有及时触发检查点,会导致wal段文件迅速增长,直到触发检查点后重复使用文件,或在转为不繁忙时,定期删除不用的wal文件段。