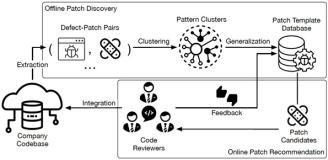
阿里妹导读:菜鸟供应链业务链路长、节点多、实体多,使得技术团队在建设供应链实时数仓的过程中,面临着诸多挑战,如:如何实现实时变Key统计?如何实现实时超时统计?如何进行有效地资源优化?如何提升多实时流关联效率?如何提升实时作业的开发效率? 而 Blink 能否解决这些问题?下面一起来深入了解。
背景
菜鸟从2017年4月开始探索 Blink(即 Apache Flink 的阿里内部版本),2017年7月开始在线上环境使用 Blink,作为我们的主流实时计算引擎。
为什么短短几个月的探索之后,我们就选择Blink作为我们主要的实时计算引擎呢?
在效率上,Blink 提供 DataStream、TableAPI、SQL 三种开发模式,强大的 SQL 模式已经满足大部分业务场景,配合半智能资源优化、智能倾斜优化、智能作业压测等功能,可以极大地提升实时作业的开发效率;在性能上,诸如MiniBatch&MicroBatch、维表 Async&Cache、利用 Niagara 进行本地状态管理等内部优化方案,可以极大地提升实时作业的性能;在保障上,Blink 自带的 Failover 恢复机制,能够实现线程级的恢复,可以做到分钟级恢复,配合 Kmonitor 监控平台、烽火台预警平台,可以有效地实现实时作业的数据保障。
接下来,我将结合供应链业务的一些业务场景,简要说明,Blink 如何解决我们遇到的一些实际问题。
回撤机制
订单履行是供应链业务中最常见的物流场景。什么是订单履行呢?当商家 ERP 推单给菜鸟之后,菜鸟履行系统会实时计算出每笔订单的出库、揽收、签收等节点的预计时间,配送公司需要按照各节点的预计时间进行订单的配送。为了保证订单的准点履约,我们经常需要统计每家配送公司每天各个节点的预计单量,便于配送公司提前准备产能。
看似很简单的实时统计加工,我们在开发过程中遇到了什么问题呢?履行重算!当物流订单的上游某个节点延迟时,履行系统会自动重算该笔订单下游所有节点的预计时间。比如某个物流订单出库晚点后,其后的预计揽收时间、预计签收时间都会重算。而对于大部分的实时计算引擎来说,并不能很友好的支持这种变 Key 统计的问题。以前,数据量没那么大的时候,还可以通过 OLAP 数据库来解决这类场景,当量上来后, OLAP 方案的成本、性能都是很大的问题。
除了 OLAP 方案,我们提倡采用 Blink 已经内置的 Retraction 机制,来解决这类变 Key 统计的问题,这也是我们在2017年初就开始尝试 Blink 的重要原因。Blink 的Retraction 机制,使用 State 在内存或者外部存储设备中对数据进行统计处理,当上游数据源对某些汇总 Key 的数据做更新时,Blink 会主动给下游下发一个删除消息从而“撤回”之前的那条消息,并用最新下发的消息对表做更新操作。
下面是一个简化后的案例,供了解Blink Retraction的内部计算过程:

对于上述案例,可以通过 Blink 提供的强大的、灵活的、简易的 SQL 开发模式来实现,只需要几行 SQL 即可完成。
select plan_tms_sign_time
,sum(1) as plan_tms_sign_lgtord_cnt
from
(select lg_order_code
,last_value(plan_tms_sign_time) as plan_tms_sign_time
from dwd_csn_whc_lgt_fl_ord_ri
group by lg_order_code
) ss
group by plan_tms_sign_time
;维表关联
供应链业务的实体角色非常多(仓、配、分拨、站点、小件员、货主、行业、地区等),实体繁多,这意味着我们在建设实时明细中间层的时候,会使用大量的维表关联,这对 Blink 在维表关联的性能上提出了更高的要求——如何提升大量的大小维表的关联性能?Blink 从来没让用户失望,Blink SQL 模式在维表关联的性能上,也做了大量的优化:
优化1:Async IO,有一些实时计算引擎,维表关联是采用同步访问的方式,即来一条数据,去数据库查询一次,等待返回后输出关联结果。这种方式,可以发现网络等待时间极大地阻碍了吞吐和延迟。而 Blink 采用了异步访问的模式,可以并发地处理多个请求和回复,从而连续地请求之间不需要阻塞等待,吞吐量大大提升。
优化2:缓存,维表关联涉及到大量的维表查询请求,其中可能存在大量相同 Key 的重复请求。Blink SQL 模式提供了缓存的机制,并提供 LRU 和 ALLCache 两种缓存方案。
用户可以通过配置 Cache='LRU' 参数,开启 LRU 缓存优化。开启后,Blink 会为每个 JoinTable 节点创建一个 LRU 本地缓存。当每个查询进来的时候,先去缓存中查询,如果存在则直接关联输出,减少了一次 IO 请求。如果不存在,再发起数据库查询请求,请求返回的结果会先存入缓存中以备下次查询。
如果维表数据不大,用户可以通过配置 Cache='ALL' 参数,对维表进行全量缓存。这样,所有对该维表的查询操作,都会直接走本地缓存模式,几乎没有 IO,关联的性能非常好。
优化3:缓存无效 Key,如果维表很大,无法采用 ALLCache 的方案,而在使用 LRU 缓存时,会存在不少维表中不存在的 Key 。由于命中不了缓存,导致缓存的收益较低,仍然会有大量请求发送到数据库,并且LRU模式下缓存里的key不会永久保留,可以通过调整参数,设置保留时间。
优化4:Distribute By 提高缓存命中率,默认情况下,维表关联的节点与上游节点之间是 Chain 在一起,不经过网络。这在缓存大小有限、Key 总量大、热点不明显的情况下, 缓存的收益可能较低。这种情况下可以将上游节点与维表关联节点的数据传输改成按 Key 分区。这样通常可以缩小单个节点的 Key 个数,提高缓存的命中率。
除了上述几点优化,Blink SQL 模式还在尝试引入 SideInput、Partitioned ALL Cache 等优化方案,相信在随后开源的 Blink 版本中,维表关联的性能会越来越好。
下面是一张来自 Flink Committer 云邪 异步查询的流程图,供理解与同步请求的差异。

数据倾斜
无数据不倾斜,我们在实时数仓建设过程中,也当然会遇到数据倾斜问题。在统计卖家的单量时,有些卖家单量大,有些卖家单量小,单量超大的卖家,就会产生数据倾斜;在统计行业的单量时,有些行业单量大,有些行业单量小,单量超大的行业,就会产生数据倾斜;在统计货品的库存流水情况时,有些货品库存流水频繁,一些货品库存流水较少,库存流水超频繁的货品就会产生数据倾斜……
我们应该如何处理数据倾斜问题呢?以统计卖家的单量为例,以前我们会先把订单这个 Key 作 Hash,先针对 Hash 之后的值做一次去重的聚合操作,再在此基础上,再做一次针对原 Key 去重的聚合操作。两次类似的聚合操作,导致代码写起来比较复杂,体力劳动比较多。
2017年,我们的实时数据开始全面切换到 Blink 上,Blink 在数据倾斜这块,又给我们提供了什么的方案呢?Blink 给出的答案是:MiniBatch/MicroBatch+LocalGlobal+PartialFinal。
MiniBatch/MicroBatch,可以实现微批处理,进而减少对 State 的访问,提升吞吐。因为微批处理会导致一定的延迟,最好结合 Blink 提供的允许延迟的相关参数来使用。
LocalGlobal,分为 Local 和 Global 两个阶段,有点类似 MapReduce 中的Combine 和 Reduce 两个阶段。LocalGlobal 可以很好地处理非去重类的聚合操作,但对 Count Distinct 的优化效果一般,因为在 Local 阶段,可能 Distinct Key的去重率并不会很高,进而导致后续的 Global 阶段,仍然会有热点。
PartialFinal,可以很好地解决 Count Distinct 带来的数据倾斜问题。PartialFinal 可以将 Distinct Key 自动打散,先聚合一次,在此基础上,再聚合一次,从而实现打散热点的作用。PartialFinal 跟手动 Hash 再聚合两次的效果一致,通过 Blink 提供的 PartialFinal 参数,可以自动实现,不再需要人为手工编写 Hash 再聚合两次的代码。
由上可以看出,Blink 在数据倾斜的处理上,已经实现了自动化,以前人为编写的打散热点方案,现在几个参数就能全部搞定,大大提升了代码的编写效率。
下面是相关参数,用户可以直接在 Blink 的作业参数中进行配置。
miniBatch/microBatch攒批的间隔时间
blink.miniBatch.allowLatencyMs=5000
blink.microBatch.allowLatencyMs=5000防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
开启LocalGlobal
blink.localAgg.enabled=true
开启PartialFinal
blink.partialAgg.enabled=true
超时统计
上架是仓储业务的重要组成部分。上架,顾名思义,就是要把到仓的货品,上到仓库的存储货架上。上架一般分为采购上架、销退上架、调拨上架等。及时上架是对仓库的重要考核项之一,无论哪一种类型的上架,我们经常需要针对到货后超过 x 小时未上架的订单进行预警。
但是,Blink 的计算是消息机制,需要上游发送消息才能触发下游计算,而上述的场景中,未上架就说明不会有上架的消息流入 Blink,进而无法完成下游的计算。
对于这种实时超时统计的问题,应该如何来解呢?我们尝试了几种方案,供参考:
方案1:针对部分 Source Connector,Blink 提供了"延时下发"的功能,用户可以通过指定 DataDeliveryDelayMs 参数,实现消息延迟下发。正常的消息正常流入,正常消息也可以通过配置该参数,使其按照自己的需求延时流入。这样,通过正常流入的消息关联延时流入的消息,可以触发 Blink 在消息正常流入时计算一次,在延时消息流入时再触发计算一次。这种方案,可以实现我们的业务需求,但是这种方案会把所有消息重新发送一遍,而不仅仅是到货后超过x小时未上架的消息,这样会造成计算资源的浪费,我们不建议在数据量很大的场景下使用该方案。
方案2:如果有第三方的消息中间件,而这个消息中间件又能支持配置超时下发的规则,这将是一个比较好的方案。据了解,Kafka 的最新版本已经能够根据业务需求,配置消息超时下发的规则。我们只需要在 Blink 中,通过正常流入的消息流关联关键Kafka 超时下发的消息流,就可以触发 Blink 进行超时消息的统计。这样,除了Blink,我们需要同时保障 Kafka 的稳定性。Kafka的超时消息订阅,可以参见:[1]。
方案3:我们能够很自然的想到 CEP,而 Blink 也已经提供了 CEP 的功能,且已经SQL化。用户可以通过 Blink CEP 完成上述业务需求的统计。在实操过程中,我们发现,通过 Blink CEP 统计的结果,往往与真实结果(明细汇总统计)有一定的出入。什么原因呢?原来到货时间,被回传了多次,有可能开始回传的是9点,但是后面发现回传错了,改成了8点,而 CEP 的 Watermark 是全局地向前走的,对于这种场景,无法很好的适配。
方案4:Flink 的 ProcessFunction,是一个 Low-Level 的流处理操作。通过改写其中的 ProcessElement 方法,可以告诉 Blink的State 里面存什么,以及如何更新State;通过改写 OnTimer 方法,可以告诉 State 何时下发超时消息。通过对上述几种方案的原理对比及性能压测,我们最终选择的也是这套方案。由于超时场景,在供应链业务中非常常见,我们已经将该方案沉淀下来,同样的场景,通过 1min 配置下相关参数,即可完成类似场景超时消息的下发。
下面是方案4简化后的实现框架图,供了解相关实现及优势。

零点起跳
每次大促,大屏上零点时刻双十一的零点时刻一直是大家关注的焦点,为了在零点一过就让各项指标尽快在大屏上展现出来,我们进行了一些端到端的优化,供参考。
优化1:合理调整 Blink 读取上游消息源的 FlushInterval 。我们知道 Blink 是以Block 的形式传输数据,如果 Block 一直积攒不满,Block 可能一直等待无法下发。这种情况,我们可以通过调整 FlushInterval 参数,直接控制多长时间往下游 sink 一次。这样,Block 积满或间隔达到满足其中一个条件,Block 就会往下流。
优化2:合理调整 MiniBatch/MicroBatch的size 和 AllowLatency 参数。前文提到,MiniBatch/MicroBatch 是微批处理模式,都会带来一定的延迟,可以通过合理控制 Size 和 AllowLatency 参数,来控制该模式带来的延迟。与优化1一样,两者满足其一,就会往下继续执行。
优化3:合理控制写 Checkpoint 的方式以及 Checkpoint 的大小。利用 Checkpoint 实现 Exactly Once 的容错方式一直是 Flink 作为流引擎的一个亮点。但是过于复杂的运算和网络环境有可能导致 checkpoint 的对齐时间过长,从而导致整个 Job 的延迟变长。同时,Exactly Once 模式下做 Checkpoint 的时间间隔与整个任务中数据流的延迟也是一个 Trade Off。因此我们在处理特别复杂的 Job 时也将这个因素考虑了进去,并没有使用默认的 Exactly Once 方式,而是依旧实际需求采用了 At Least Once 。同时,将 Checkpoint 的周期设置为了60s,尽可能的保证了任务在延迟较小的情况下,在 Failover 的情形下仍然能做到快速恢复。
优化4:除了 Blink 端,在数据服务端,大屏上的实时数据,我们建议采用查询性能优异的 Hbase 作为存储引擎,可以保证零点一过,三秒内便能实现大屏数据的跳动。
……
未来展望
Blink 在不断快速地发展,不仅仅是流处理,当前也开始支持批处理,用户只需要写一套代码就可以同时实现批和流的数据开发,当前在日志型的数据场景上,我们也正在探索利用 Blink 直接实现批流混合模式;不仅仅是半智能资源调优,当前开始内测智能资源调优,Blink 可以根据吞吐量、算子复杂度等因素,对线上作业的资源配置进行全智能自适应调优,再也不用在大促前手动更改资源配置;不仅仅是 Java,更期望有 Python 等多语言生态,来描述计算逻辑,相信开发效率又会上一个新的台阶;不仅仅是 ETL,更期望有更广阔的大数据算法集成,可以实现复杂的大数据AI场景……未来已来,我们相信,Blink 已经做好了迎接未来的准备。
参考资料:
[1]https://ketao1989.github.io/2016/01/02/delayed-message-consume-service-use-kafka/
原文发布时间为: 2019-05-23
本文作者: 晨笙、缘桥
本文来自云栖社区合作伙伴“ 阿里技术”,了解相关信息可以关注“ 阿里技术”。