4 月 24 日,在 Spark+AI 峰会 上,我们很高兴地宣布推出 .NET for Apache Spark。Spark 是一种流行的开源分布式处理引擎,用于分析大型数据集。Spark 可用于处理批量数据、实时流、机器学习和即席查询(ad-hoc query)。
.NET for Apache Spark 旨在使 .NET 开发人员可以跨所有 Spark API 来访问 Apache® Spark™。到目前为止,Spark 已经可以通过 Scala、Java、Python 和 R 来访问,但尚不能通过 .NET 来访问。
我们计划在 open(作为.NET Foundation 成员项目)中为 Apache Spark 开发 .NET,同时与 Spark 和 .NET 社区一起开发,以确保开发人员能够在这两方面都做得很好。
本文将阐述关于以下主题的更多细节:
什么是 .NET For Apache Spark?
.NET for Apache Spark 入门
.NET for Apache Spark 性能
.NET For Apache Spark 的下一步
结语
什么是 .NET for Apache Spark?
.NET for Apache Spark 提供了高性能 API,用于使用 C# 和 F# 中的 Spark。通过这个 .NET API,开放人员可以访问 Apache Spark 的所有方面,包括 Spark SQL、DataFrame、Streaming、MLLib 等。.NET for Apache Spark 允许 .NET 开发人员重用已有的所有知识、技能、代码和库。
绑定到 Spark 的 C#/F# 语言将被编写到一个新的 Spark 互操作层上,该层提供了更容易的可扩展性。这一新的 Spark 互操作层的编写,考虑到了语言扩展的最佳实践,并针对互操作性和性能进行了优化。从长期来看,这种可扩展性可用于在 Spark 中增加对其他语言的支持。
你可以通过访问这个 提案 来了解更多关于这项工作的细节
NET for Apache Spark 与 .NET Standard 2.0 兼容,可以在 Linux、macOS 和 Windows 系统上使用,就像 .NET 的其余部分一样。.NET for Apache Spark 在 Azure HDInsight 中默认可用,并且可以安装在 Azure Databricks 等软件中。
.NET for Apache Spark 入门
在开始使用。NET for Apache Spark 之前,需要安装一些东西。按照 以下步骤 开始使用 .NET for Apache Spark。
设置完成之后,我们可以通过三个简单的步骤在 .NET 中开始编写 Spark 应用。
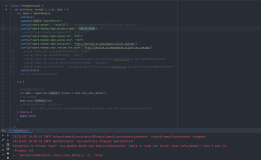
在我们的第一个 .NET Spark 应用中,我们将编写一个基本的 Spark 管道,用于计算文本段中每个单词的出现次数。
// 1. Create a Spark session
var spark = SparkSession
.Builder()
.AppName("word_count_sample")
.GetOrCreate();
// 2. Create a DataFrame
DataFrame dataFrame = spark.Read().Text("input.txt");
// 3. Manipulate and view data
var words = dataFrame.Select(Split(dataFrame["value"], " ").Alias("words"));
words.Select(Explode(words["words"])
.Alias("word"))
.GroupBy("word")
.Count()
.Show();.NET for Apache Spark 性能
我们很高兴地宣布,.NET fro Apache Spark 的第一个预览版本在流行的 TPC-H 基准 测试中表现良好。TPC-H 基准由一组面向业务的查询组成。下图展示了 .NET Core 与 Python、Scala 在 TPC-H 查询集上的性能对比。

上图显示了 .NET for Apache Spark 与 Python 和 Scala 的每个查询性能对比。.NET for Apache Spark 对阵 Python 和 Scala 时表现出色。此外,在 UDF 性能至关重要的情况下,例如查询 1,其中在用于 Apache Spark 的 JVM 和 CLR 之间传递 3B 行的非字符串数据,就其传递速度而言,.NET 要比 Python 快上 2 倍。
同样重要的是,这是我们为 Apache Spark 开发的第一个 .NET 预览版,我们的目标是进一步致力于改进和基准测试性能(如 Arrow 优化)。你可以按照我们的说明在 Github repo 上对其进行基准测试。
.NET For Apache Spark 的下一步
今天 .NET for Apache Spark 的发布,是我们征途的第一步。以下是我们近期路线图的一些功能,请关注我们的 GitHub repo 的 完整路线图。
- 简化入门体验、文档与示例。
- 与 Visual Studio、Visual Studio Code、Jupyter notebooks 等开发工具进行原生整合。
- .NET 支持用户定义的聚合函数。
- 用于 C# 和 F# 的 .NET 惯用 API(如,使用 LINQ 编写查询)。
- 对 Azure Databricks、Kubernetes 等开箱即用的支持。
- 将 .NET for Apache Spark 作为 Spark Core 的部分。你可以访问此 网址 跟踪进程。
结语
.NET for Apach Spark 是我们将 .NET 打造成构建大数据应用程序的重要技术堆栈的第一步。
我们需要你的帮助来为 .NET for Apache Spark 塑造未来。我们期待你使用 .NET for Apache Spark 进行构建。你可以通过我们的 GitHub repo,向我们伸出援助之手。
原文链接:https://www.infoq.cn/article/meOQHWjeosl6q-l4iC05
翻译自:https://devblogs.microsoft.com/dotnet/introducing-net-for-apache-spark/