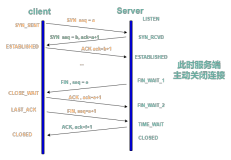
本文介绍了一个在阿里云环境下某客户端ECS机器上突然发现TIME_WAIT突然增高的问题和排查过程。
问题场景:原来客户端直接访问后端Web服务器,TIME_WAIT数量非常少。现在引入了7层SLB来实现对后端服务器的负载均衡。客户端SLB访问后端服务器,但是发现客户端的TIME_WAIT状态的socket很快累积到4000多个,并且客户反映没有修改任何内核参数。
梳理问题
收到这个信息后,基本上可以推断出来的信息:
客户端通过短连接连接SLB(服务器),客户端是连接的主动关闭方。并且并发比较大。
如果之前没有发现TIME_WAIT堆积,而现在堆积,在访问模式不变的情况下,极有可能之前有TIME_WAIT socket的快速回收或复用。那么基本上可以推断下面几个TCP内核参数设置大概率如下:
- net.ipv4.tcp_tw_recycle = 1
- net.ipv4.tcp_tw_reuse = 1
- net.ipv4.tcp_timestamps = 1
客户确认了如上信息。
排查
在这个案例中我们目前能确认的唯一变化就是引入了SLB,那就需要看下SLB对TIME_WAIT的影响到底是什么。对于客户端来说,如果TCP内核参数tcp_tw_recycle和tcp_timestamps同时为1,正常情况下处于TIME_WAIT状态的socket会被快速回收 (这个描述不严谨,后面可以看看源代码),客户现在的现象是看起来是TIME_WAIT状态的socket没有被快速回收。
因为tcp_tw_recycle是一个系统参数,而timestamp是TCP option里携带的一个字段,我们主要需要关注下timestamp的变化。如果你足够熟悉SLB,可能并不需要抓包就知道SLB对TCP timestamp做了什么。但是我们这里按照正常的排查方法:抓包,比较在引入SLB之前和之后报文有什么区别。
在引入SLB后,客户端访问SLB,在客户端抓包。可以看到如下客户端到SLB的SYN,里面的TCP Option中包含有Timestamps。TSval是根据本端系统的CPU tick得出的值;TSecr是echo对方上次发过来的TSval值,根据对端系统的CPU tick得出,以便计算RTT,这里因为是首个建立TCP连接的SYN,所以TSecr值为0。

而在客户端观察SLB的回包时,可以看到TCP Option中的TCP tiemstamps已经不存在了,而客户端在直接访问后端服务器时TCP tiemstamps是一直存在。通过对比,发现这就是引入SLB后带来的变化:SLB抹去了TCP Option中的timestamps字段。

排查到这里,我们差不多把这个变化的因素抓住了。但是抹去TCP timestamps具体是怎么影响TIME_WAIT状态socket数目变化的呢?还得具体看看TCP TIME_WAIT快速回收的代码逻辑。
TCP TIME_WAIT的快速回收
tcp_time_wait的逻辑
Linux kernel不同版本的代码可能会有小的,这里根据的是3.10.0版本的代码。TCP进入TIME_WAIT(FIN_WAIT_2)状态的逻辑在tcp_minisocks.c中的tcp_time_wait()中。

可以看到这里有个recycle_ok的bool变量,它确定了处于TIME_WAIT状态的socket是否被快速recycle。而只有当tcp_death_row.sysctl_tw_recycle和tp->rx_opt.ts_recent_stamp都为true时,recycle_ok才有机会被置为true。
前面提到过一个不严谨的表述:“如果TCP内核参数tcp_tw_recycle和tcp_timestamps同时为1,正常情况下处于TIME_WAIT状态的socket会被快速回收“,不严谨的原因在于:是否recycle看的是tcp_sock中的rx_opt.ts_recent_stamp,而非当前系统的TCP内核参数设置。这里从SLB的回包中显然已经没有TCP timestamps的信息了,所以这里recycle_ok只能是false。后面的逻辑如下:

理解回收时间和RTO
关于TIME_WAIT的具体回收时间,就在上面这段代码中:
- recycle_ok为true时,TIME_WAIT回收的时间是rto;
- 而recycle_ok为false时,回收时间是正常的2MSL:TCP_TIMEWAIT_LEN (60s,在tcp.h中写死,内核编译后固定,不可调)。
上面代码中的rto只是个本地变量,它在函数中赋值为3.5倍的icsk->icsk_rto (RTO, Retrasmission Timeout):
const int rto = (icsk->icsk_rto << 2) - (icsk->icsk_rto >> 1);icsk->icsk_rto根据实际网络情况动态计算而成,可参考文章中的具体描述。在tcp.h中规定了RTO的最大和最小值,如下:
#define TCP_RTO_MAX ((unsigned)(120*HZ))
#define TCP_RTO_MIN ((unsigned)(HZ/5))HZ为1s,TCP_RTO_MAX = 120s, TCP_RTO_MIN = 200ms。所以在局域网内网环境下,即使RTT小于1ms,TCP超时重传的RTO最小值也只能是200ms。
所以在内网环境中,可以理解成TIME_WAIT socket快速回收的时间为3.5*200ms = 700ms。而对于极端糟糕的网络环境,这里可能有个坑,TIME_WAIT“快速回收”的时间可能大于正常回收的60s。
结论
在这个案例中,因为TIME_WAIT的回收时间从3.5倍RTO时间变成了60秒,并且客户端有比较大的TCP短连接并发,所以导致了客户端迅速堆积处于TIME_WAIT状态的socket。
总结
本文中提到的是一个7层SLB的案例,但实际上这个抹去TCP timestamp的行为会发生在full nat模式的LVS中,所以以full nat模式LVS作为vip的产品都有可能会出现这个问题。
如何解决
对于没有TCP timestamp信息的客户端来说,要让这么多的TIME_WAIT socket迅速消失,比较优雅的方法是使用TCP长连接来代替短连接。
如何理解
换一个角度,为什么要解决呢?在客户端出现4000多个TIME_WAIT是不是个问题呢?其实在正常系统环境中算不上问题,只是可能令你的netstat/ss输出比较不友好而已。TIME_WAIT socket对于系统资源的消耗影响非常小,而真正需要考虑因为TIME_WAIT多而触碰到限制的是如下几个方面:
- 源端口数量 (net.ipv4.ip_local_port_range)
- TIME_WAIT bucket 数量 (net.ipv4.tcp_max_tw_buckets)
- 文件描述符数量 (max open files)
如果TIME_WAIT数量离上面这些limit还比较远,那我们可以安安心心地让子弹再飞一会。