
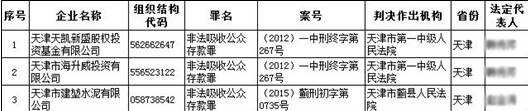
最近接了一个新需求,需要获取一些信用黑名单数据,但是找了很多数据源,都是同样的几张图片,目测是excel表格的截图,就像下面这样:

既然没有找到文本类型的数据源,只能对图片上的文字进行识别了。
尝试一,利用第三方API识别:
说到图像识别我首先想到了网上的各类图像识别服务。试用了一下百度、腾讯的识别服务,效果并不好,部分文字识别错误甚至无法识别,不付费只能使用有限的几次。总之,使用第三方的识别服务是行不通的。
尝试二,利用Tesseract-OCR识别:
接下来只能自己想办法识别了,首先试一下google的工具Tesseract-OCR。Python里的pytesseract模块对这个工具进行了封装,使用起来很方便。

test.png
In [1]: import Image
In [2]: import pytesseract
In [3]: image = Image.open('/home/****/shixin/test.png')
In [4]: image = image.convert('L')
In [5]: text = ''.join(pytesseract.image_to_string(image,, config='-psm 6'))
In [6]: print text
〔Zol l 〕西中执字第
口口o22号
识别结果不太准确,原因是识别场景比较复杂,识别的内容包含了标点符号、汉字、数字和字母。对于只含有数字或者字母的识别场景,pytesseract 的识别已经足够了,但是对于当前较复杂的识别需求,识别的准确率不高。
对于这种情况,可以采用训练字库的方式提高准确率,感兴趣的同学可以参考这篇文章(http://www.cnblogs.com/wzben/p/5930538.html)。但是对于目前的需求,我们并不能得到足够的训练样本,所以此路不通。
尝试三,利用机器学习识别:
机器学习我没有接触过,也没有做过相关的需求,于是我开始学习它。然后我发现这是一门很广博的学科,短期的学习难有成效,只好暂时放弃,尝试用其他办法解决问题。
尝试四,利用图像对比识别:
虽然新技能Get失败了,但是对于搞定需求,我从来都是不抛弃不放弃的。我想到了利用图像相似度识别文字的方法,在这里感谢大学教导我数字图像处理的导师。经过尝试,这是一个可行的方案,接下来就介绍一下识别的过程。识别过程主要分为以下几个步骤:
1. 图像预处理
从网上下载的图片需要进行预处理,包括:
(1)灰度化
将彩色图像转化成为灰度图像的过程称为图像的灰度化。彩色图像中每个像素点的颜色由R、G、B三个分量决定,分别代表红绿蓝三种原色。灰度图像就是R、G、B三个分量相同的特殊彩色图像,每个像素点只有一个代表亮度的灰度值,将图像转变成灰度图像可以方便后续的计算。
(2)二值化
图像的二值化,就是将图像的灰度值(https://baike.baidu.com/item/%E7%81%B0%E5%BA%A6%E5%80%BC)设置为0或255,使得图像上只存在黑白两种颜色,而没有中间的灰色。二值化后灰度图像的噪点会被去除,可以使后续的图像对比更简单。二值化需要指定一个阀值,经过测试,这次要识别的图像的最优二值化阀值为69,即灰度图像中灰度值低于69的像素的灰度值会变为0,反之变为255。代码如下:
def binarizing(image, threshold): pixdata = image.load() w, h = image.size for y in range(h): for x in range(w): if pixdata[x, y] < threshold: pixdata[x, y] = 0 else: pixdata[x, y] = 255 return image
原图.png

灰度化.png
二值化.png
2. 图像切割为单元格
从上面的图可以看出,图像是一个表格的截图,我们需要把它分割成单元格,这是为了方便数据的分类和图像的二次切割。
图片像素矩阵轮廓如下所示:

使用横向和纵向扫描线分别扫描图像的像素矩阵,根据像素灰度值的变化确定表格分割线的坐标,再根据坐标把图像切割成单元格。
有的单元格有多行内容,需要把多行合并为一行,如下所示:

使用横向扫描线扫描这一单元格图像,找到行之间空白部分的坐标,根据坐标确定分割线的位置,然后根据分割线分割图像,最后合并为一行。要注意的是类似于下图的情况:

这种情况下第二行的“号”字是上下结构而且单独占一行,单元格会被分成三行,解决办法是根据汉字的高度跳过间隔高度不足的分割线。
3. 单元格分类
图像的第一行是表头,图像分割为单元格后先使用tesseract识别表头,这样就可以根据表头判断列的类型,如案号、组织机构代码等,从而指定不同的策略将单元格分割为字符。比如案号的内容含有数字、字母、汉字和标点符号,而组织机构代码只含有数字,这就需要使用不同的分割方式。
4. 单元格分割为字符
单元格中字符的分割可以说是耗时最久最难的部份了,有很多需要注意的点。
对于如下所示的只含有数字和字母的单元格,分割起来比较简单,直接使用纵向扫描线扫描,得出字符间的空白部分的坐标,然后根据坐标计算分割线进行分割即可。
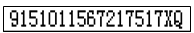
而对于含有数字、字母、汉字和标点符号的单元格,需要对分割线进行二次加工,这是因为存在左右结构、左中右结构、左中中右结构的汉字。如下所示:

其中“刑”字是左右结构,“川”字是左中右结构,“顺”字是左中中右结构。
在本次识别过程中,对含有汉字的单元格分割出的每个字符做如下处理:
(1)判断是否是左右结构的汉字
若当前字符与它后面一个字符的高度均大于9px,或者这两个字符中有一个的宽度小于4px,说明这两个字符可能是一个左右结构的汉字。那么忽略两个字符间的分割线,将这两个字符作为一个完整字符进行识别,识别成功则说明这两个字符是一个汉字,去除两个字符中间的分割线,为二次分割做准备。
(2)判断是否是左中右结构的汉字
若上一步的两个字符没有判断为汉字,将当前字符与它后面的两个字符作为一个新字符切割下来,如果这三个字符合并后的新字符宽度等于12px且高度大于10px,说明新字符是一个左中右结构的汉字,去除三个字符中间的分割线,为二次分割做准备。
(3)判断是否是左中中右结构的汉字
若上一步的三个字符没有判断为汉字,将当前字符与它后面的三个字符作为一个新字符切割下来,如果这四个字符合并后的新字符宽度等于12px且高度大于10px,说明新字符是一个左中中右结构的汉字,去除四个字符中间的分割线,为二次分割做准备。代码逻辑片段如下:
tmp_img_l = clear_image(image.crop((white_line[index - 1] + 1, 0, white_line[index], h))) tmp_img_r = clear_image(image.crop((white_line[index] + 1, 0, white_line[step_1], h))) tmp_w_l, tmp_h_l = tmp_img_l.size tmp_w_r, tmp_h_r = tmp_img_r.size word_image = clear_image(image.crop((white_line[index - 1] + 1, 0, white_line[step_1], h))) if ((tmp_h_r > 9 and tmp_h_l > 9) or (tmp_w_l < 4 or tmp_w_r < 4)) and parse_character(word_image, word_data): for tmp_index in range(index, step_1): tmp_white_line[tmp_index] = None else: for tmp_index in range(step_1 + 1, len(white_line)): if white_line[tmp_index] - white_line[tmp_index - 1] > 1: step_2 = tmp_index if None not in tmp_white_line[index - 1: step_2] and white_line[step_2] - white_line[index - 1] == 12: tmp_img = clear_image(image.crop((white_line[index - 1] + 1, 0, white_line[step_2], h))) tmp_w, tmp_h = tmp_img.size if tmp_h > 10: for tmp_index in range(index, step_2): tmp_white_line[tmp_index] = None else: for tmp_index in range(step_2 + 1, len(white_line)): if white_line[tmp_index] - white_line[tmp_index - 1] > 1: step_3 = tmp_index if None not in tmp_white_line[index - 1: step_3] and white_line[step_3] - white_line[index - 1] == 12: tmp_img = clear_image(image.crop((white_line[index - 1] + 1, 0, white_line[step_3], h))) tmp_w, tmp_h = tmp_img.size if tmp_h > 10: for tmp_index in range(index, step_3): tmp_white_line[tmp_index] = None break break5. 生成对比字符时使用的参照数据集
仔细的观察图片里的文字,再利用网站识别字体,很幸运的找到了图片原作者使用的字体。接下来我们就可以生成对比字符时使用的参照数据集了。
首先下载字体文件,然后利用字体文件把文字渲染到空白图片上,最后把图片转换为矩阵存储到文件中。渲染的字体的大小要和识别的图片上的字体一致,这里是12px。下面给出文字转换为图像矩阵的函数:
def paste_word(word): # 生成单个文字矩阵 pygame.init() font = pygame.font.Font('***/***.TTF', 12) rtext = font.render(word, False, (0, 0, 0), (255, 255, 255)) sio = StringIO.StringIO() pygame.image.save(rtext, sio) sio.seek(0) image = Image.open(sio) image = clear_image(image.convert('L')) # 去除图片四周的空白 if image: return numpy.asarray(image) return None本次识别搜录的字符有7869个,生成的数据集保存到一个文件中。
6. 对比识别字符
最后的一步是对比识别字符,代码如下:
def parse_character(word_image, word_data): word_matrix = numpy.asarray(word_image) for word, matrix in word_data.items(): try: if word in '4679BCDEFHIJKLMNOQRSTUVWXYZ': threshold = 256 elif word in u'()AG': threshold = 516 else: threshold = 1 if numpy.subtract(matrix, word_matrix).sum() <= threshold: if word == 'B' and numpy.subtract(word_data['P'], word_matrix).sum() <= 1: word = 'P' if word == 'E' and numpy.subtract(word_data['F'], word_matrix).sum() <= 1: word = 'F' return word except Exception: pass return ''其中word_image是分割得到的字符图片,word_data是预先生成的参照字符矩阵,把word_image转化为矩阵,然后对两个矩阵的差求和,如果求得的和小于等于阀值threshold,说明字符匹配完成,字符识别成功。
总结:
这种识别方法的准确率并不是100%,识别失败的情况有两种。一种情况是有些含有多行文本的单元格高度不足,单元格中最上和最下两行的文字只显示了一半,如下图所示:

这种情况人眼也无法识别,只能放弃;另一种情况是识别的汉字中存在异体字,如“昇”、“堃”等,字体文件无法生成这类文字的图像矩阵,导致识别失败。识别失败的情况极少,所以手动矫正就可以了。
这种识别方法的缺点是适用范围小,识别的效率也不高。不过识别效率仍有提升空间,比如可以利用多线程和多进程并发识别,提高资源利用率,也可以使用二分法、插值法等算法优化识别字符时的匹配过程。
识别过程中最大的难点是汉字的分割,这需要对汉字的特点进行深入了解。
这种识别方法只能算是“权宜之计”,要更快更好的识别图像,还是要用机器学习,有兴趣的同学可以一起学习。更多文字识别内容详见商业新知-文字识别

