Spark2.4.0源码分析之WorldCount Stage提交顺序(DAGScheduler)(五)
更多资源
时序图

主要内容描述
- 理解FinalStage是如何按stage从前到后依次提交顺序
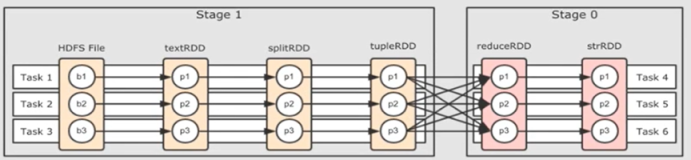
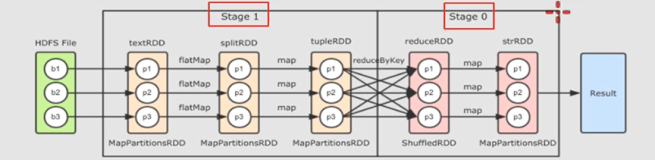
).FinalStage(Stage0) -> Stage1 -> Stage2 -> Stage3
).Stage0的parents stage是Stage1,Stage1的parents stage是Stage2,Stage2的parents stage是Stage3
).Stage提交的顺序是,先提交最顶上的Stage(Stage3),等Stage3计算完成后,再提交Stage2,等Stage2计算完成后,再提交Stage1,等Stage1计算完成后,再提交Stage0
).所以Stage的计算顺序是:依次从最顶级Stage开始提交,等待该Stage计算完成后,再依次提交该Stage的直接下级Stage
源码分析
DAGScheduler.submitStage
- DAGScheduler.handleJobSubmitted()处理作业提交事件,计算完成FinalStage后,调用函数DAGScheduler.submitStage(FinalStage)
-
Stage的提交计算逻辑
- 首先拿到FinalStage进行判断,判断该Stage是不是已经处理过,如果已经处理过,就不会再次提交
- 如果FinalStage是第一次提交过来,就调用函数DAGScheduler.getMissingParentStages(Stage),找到当前Stage的上级没有被处理过的Stage(即parent Stage)
- parent stage 为空,就可以提交当前Stage,parent stage不为空,就先提交parent stage
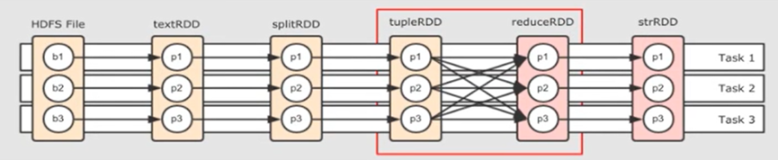
- FinalStage(ResultStage) 的 parent stage为ShuffleMapStage,此时parent stage 不为空,所以先调用DAGScheduler.submitStage(parent)函数,即DAGScheduler.submitStage(ShuffleMapStage),submitStage函数中自己调自己
- submitStage(ShuffleMapStage)此时,ShuffleMapStage的parent stage 为Nil,所以为空,这一次就可以调用函数DAGScheduler.submitMissingTasks(ShuffleMapStage),这个函数会去真正的提交Stage,ShuffleMapStage提交完成后,把ResultStage加到waitingStages中(等待提交的Stage)
- 注意,虽然submitStage()这个函数在此时,已调用了两次,其实只干了这一件事DAGScheduler.submitMissingTasks(ShuffleMapStage),处理了ShuffleMapStage,FinalStage此时是没有提交的,那FinalStage是什么时候提交的了?接着看下面
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
DagScheduler.handleTaskCompletion(completion)
- 每个任务完成后,都会触发事件completion: CompletionEvent,DAGSchedulerEventProcessLoop.doOnReceive()函数会调用DagScheduler.handleTaskCompletion(completion)函数进行处理
- 这个函数比较长,但是关注重点就好理解了
- ShufleMapStage是可以划分成多个任务的,ShufleMapStage划分的任务数n,也就是每个ShuffleMapTask完成后,都会调用这个函数进行处理,当n个ShuffleMapTask全部完成后,才会触发提交ShuffleMapStage的直接下级Stage,也就是ResultStage
- task match 当是ShuffleMapTask时,ShuffleMapStage中的变量pendingPartitions记录着ShuffleMapStage中所有的任务对应的partitionId,也就是有多少个ShuffleMapTask任务就有多少个分区,每完成一个任务,把当前任务对应的partitionsId移除,当pendingPartitions为空时,说明所有的任务全部完成了,就可以进行下级Stage的操作了
- 当ShuffleMapStage中所有的ShuffleMapTask完成后,就会调用函数DagScheduler.submitWaitingChildStages(shuffleStage),注意,此时的参数是ShuffleMapStage
/**
* Responds to a task finishing. This is called inside the event loop so it assumes that it can
* modify the scheduler's internal state. Use taskEnded() to post a task end event from outside.
*/
private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
val task = event.task
val stageId = task.stageId
outputCommitCoordinator.taskCompleted(
stageId,
task.stageAttemptId,
task.partitionId,
event.taskInfo.attemptNumber, // this is a task attempt number
event.reason)
if (!stageIdToStage.contains(task.stageId)) {
// The stage may have already finished when we get this event -- eg. maybe it was a
// speculative task. It is important that we send the TaskEnd event in any case, so listeners
// are properly notified and can chose to handle it. For instance, some listeners are
// doing their own accounting and if they don't get the task end event they think
// tasks are still running when they really aren't.
postTaskEnd(event)
// Skip all the actions if the stage has been cancelled.
return
}
val stage = stageIdToStage(task.stageId)
// Make sure the task's accumulators are updated before any other processing happens, so that
// we can post a task end event before any jobs or stages are updated. The accumulators are
// only updated in certain cases.
event.reason match {
case Success =>
task match {
case rt: ResultTask[_, _] =>
val resultStage = stage.asInstanceOf[ResultStage]
resultStage.activeJob match {
case Some(job) =>
// Only update the accumulator once for each result task.
if (!job.finished(rt.outputId)) {
updateAccumulators(event)
}
case None => // Ignore update if task's job has finished.
}
case _ =>
updateAccumulators(event)
}
case _: ExceptionFailure | _: TaskKilled => updateAccumulators(event)
case _ =>
}
postTaskEnd(event)
event.reason match {
case Success =>
task match {
case rt: ResultTask[_, _] =>
// Cast to ResultStage here because it's part of the ResultTask
// TODO Refactor this out to a function that accepts a ResultStage
val resultStage = stage.asInstanceOf[ResultStage]
resultStage.activeJob match {
case Some(job) =>
if (!job.finished(rt.outputId)) {
job.finished(rt.outputId) = true
job.numFinished += 1
// If the whole job has finished, remove it
if (job.numFinished == job.numPartitions) {
markStageAsFinished(resultStage)
cleanupStateForJobAndIndependentStages(job)
listenerBus.post(
SparkListenerJobEnd(job.jobId, clock.getTimeMillis(), JobSucceeded))
}
// taskSucceeded runs some user code that might throw an exception. Make sure
// we are resilient against that.
try {
job.listener.taskSucceeded(rt.outputId, event.result)
} catch {
case e: Exception =>
// TODO: Perhaps we want to mark the resultStage as failed?
job.listener.jobFailed(new SparkDriverExecutionException(e))
}
}
case None =>
logInfo("Ignoring result from " + rt + " because its job has finished")
}
case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
shuffleStage.pendingPartitions -= task.partitionId
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from executor $execId")
} else {
// The epoch of the task is acceptable (i.e., the task was launched after the most
// recent failure we're aware of for the executor), so mark the task's output as
// available.
mapOutputTracker.registerMapOutput(
shuffleStage.shuffleDep.shuffleId, smt.partitionId, status)
}
if (runningStages.contains(shuffleStage) && shuffleStage.pendingPartitions.isEmpty) {
markStageAsFinished(shuffleStage)
logInfo("looking for newly runnable stages")
logInfo("running: " + runningStages)
logInfo("waiting: " + waitingStages)
logInfo("failed: " + failedStages)
// This call to increment the epoch may not be strictly necessary, but it is retained
// for now in order to minimize the changes in behavior from an earlier version of the
// code. This existing behavior of always incrementing the epoch following any
// successful shuffle map stage completion may have benefits by causing unneeded
// cached map outputs to be cleaned up earlier on executors. In the future we can
// consider removing this call, but this will require some extra investigation.
// See https://github.com/apache/spark/pull/17955/files#r117385673 for more details.
mapOutputTracker.incrementEpoch()
clearCacheLocs()
if (!shuffleStage.isAvailable) {
// Some tasks had failed; let's resubmit this shuffleStage.
// TODO: Lower-level scheduler should also deal with this
logInfo("Resubmitting " + shuffleStage + " (" + shuffleStage.name +
") because some of its tasks had failed: " +
shuffleStage.findMissingPartitions().mkString(", "))
submitStage(shuffleStage)
} else {
markMapStageJobsAsFinished(shuffleStage)
submitWaitingChildStages(shuffleStage)
}
}
}
case FetchFailed(bmAddress, shuffleId, mapId, _, failureMessage) =>
val failedStage = stageIdToStage(task.stageId)
val mapStage = shuffleIdToMapStage(shuffleId)
if (failedStage.latestInfo.attemptNumber != task.stageAttemptId) {
logInfo(s"Ignoring fetch failure from $task as it's from $failedStage attempt" +
s" ${task.stageAttemptId} and there is a more recent attempt for that stage " +
s"(attempt ${failedStage.latestInfo.attemptNumber}) running")
} else {
failedStage.failedAttemptIds.add(task.stageAttemptId)
val shouldAbortStage =
failedStage.failedAttemptIds.size >= maxConsecutiveStageAttempts ||
disallowStageRetryForTest
// It is likely that we receive multiple FetchFailed for a single stage (because we have
// multiple tasks running concurrently on different executors). In that case, it is
// possible the fetch failure has already been handled by the scheduler.
if (runningStages.contains(failedStage)) {
logInfo(s"Marking $failedStage (${failedStage.name}) as failed " +
s"due to a fetch failure from $mapStage (${mapStage.name})")
markStageAsFinished(failedStage, errorMessage = Some(failureMessage),
willRetry = !shouldAbortStage)
} else {
logDebug(s"Received fetch failure from $task, but its from $failedStage which is no " +
s"longer running")
}
if (mapStage.rdd.isBarrier()) {
// Mark all the map as broken in the map stage, to ensure retry all the tasks on
// resubmitted stage attempt.
mapOutputTracker.unregisterAllMapOutput(shuffleId)
} else if (mapId != -1) {
// Mark the map whose fetch failed as broken in the map stage
mapOutputTracker.unregisterMapOutput(shuffleId, mapId, bmAddress)
}
if (failedStage.rdd.isBarrier()) {
failedStage match {
case failedMapStage: ShuffleMapStage =>
// Mark all the map as broken in the map stage, to ensure retry all the tasks on
// resubmitted stage attempt.
mapOutputTracker.unregisterAllMapOutput(failedMapStage.shuffleDep.shuffleId)
case failedResultStage: ResultStage =>
// Abort the failed result stage since we may have committed output for some
// partitions.
val reason = "Could not recover from a failed barrier ResultStage. Most recent " +
s"failure reason: $failureMessage"
abortStage(failedResultStage, reason, None)
}
}
if (shouldAbortStage) {
val abortMessage = if (disallowStageRetryForTest) {
"Fetch failure will not retry stage due to testing config"
} else {
s"""$failedStage (${failedStage.name})
|has failed the maximum allowable number of
|times: $maxConsecutiveStageAttempts.
|Most recent failure reason: $failureMessage""".stripMargin.replaceAll("\n", " ")
}
abortStage(failedStage, abortMessage, None)
} else { // update failedStages and make sure a ResubmitFailedStages event is enqueued
// TODO: Cancel running tasks in the failed stage -- cf. SPARK-17064
val noResubmitEnqueued = !failedStages.contains(failedStage)
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
// If the map stage is INDETERMINATE, which means the map tasks may return
// different result when re-try, we need to re-try all the tasks of the failed
// stage and its succeeding stages, because the input data will be changed after the
// map tasks are re-tried.
// Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
// guaranteed to be determinate, so the input data of the reducers will not change
// even if the map tasks are re-tried.
if (mapStage.rdd.outputDeterministicLevel == DeterministicLevel.INDETERMINATE) {
// It's a little tricky to find all the succeeding stages of `failedStage`, because
// each stage only know its parents not children. Here we traverse the stages from
// the leaf nodes (the result stages of active jobs), and rollback all the stages
// in the stage chains that connect to the `failedStage`. To speed up the stage
// traversing, we collect the stages to rollback first. If a stage needs to
// rollback, all its succeeding stages need to rollback to.
val stagesToRollback = scala.collection.mutable.HashSet(failedStage)
def collectStagesToRollback(stageChain: List[Stage]): Unit = {
if (stagesToRollback.contains(stageChain.head)) {
stageChain.drop(1).foreach(s => stagesToRollback += s)
} else {
stageChain.head.parents.foreach { s =>
collectStagesToRollback(s :: stageChain)
}
}
}
def generateErrorMessage(stage: Stage): String = {
"A shuffle map stage with indeterminate output was failed and retried. " +
s"However, Spark cannot rollback the $stage to re-process the input data, " +
"and has to fail this job. Please eliminate the indeterminacy by " +
"checkpointing the RDD before repartition and try again."
}
activeJobs.foreach(job => collectStagesToRollback(job.finalStage :: Nil))
stagesToRollback.foreach {
case mapStage: ShuffleMapStage =>
val numMissingPartitions = mapStage.findMissingPartitions().length
if (numMissingPartitions < mapStage.numTasks) {
// TODO: support to rollback shuffle files.
// Currently the shuffle writing is "first write wins", so we can't re-run a
// shuffle map stage and overwrite existing shuffle files. We have to finish
// SPARK-8029 first.
abortStage(mapStage, generateErrorMessage(mapStage), None)
}
case resultStage: ResultStage if resultStage.activeJob.isDefined =>
val numMissingPartitions = resultStage.findMissingPartitions().length
if (numMissingPartitions < resultStage.numTasks) {
// TODO: support to rollback result tasks.
abortStage(resultStage, generateErrorMessage(resultStage), None)
}
case _ =>
}
}
// We expect one executor failure to trigger many FetchFailures in rapid succession,
// but all of those task failures can typically be handled by a single resubmission of
// the failed stage. We avoid flooding the scheduler's event queue with resubmit
// messages by checking whether a resubmit is already in the event queue for the
// failed stage. If there is already a resubmit enqueued for a different failed
// stage, that event would also be sufficient to handle the current failed stage, but
// producing a resubmit for each failed stage makes debugging and logging a little
// simpler while not producing an overwhelming number of scheduler events.
logInfo(
s"Resubmitting $mapStage (${mapStage.name}) and " +
s"$failedStage (${failedStage.name}) due to fetch failure"
)
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(ResubmitFailedStages)
},
DAGScheduler.RESUBMIT_TIMEOUT,
TimeUnit.MILLISECONDS
)
}
}
// TODO: mark the executor as failed only if there were lots of fetch failures on it
if (bmAddress != null) {
val hostToUnregisterOutputs = if (env.blockManager.externalShuffleServiceEnabled &&
unRegisterOutputOnHostOnFetchFailure) {
// We had a fetch failure with the external shuffle service, so we
// assume all shuffle data on the node is bad.
Some(bmAddress.host)
} else {
// Unregister shuffle data just for one executor (we don't have any
// reason to believe shuffle data has been lost for the entire host).
None
}
removeExecutorAndUnregisterOutputs(
execId = bmAddress.executorId,
fileLost = true,
hostToUnregisterOutputs = hostToUnregisterOutputs,
maybeEpoch = Some(task.epoch))
}
}
case failure: TaskFailedReason if task.isBarrier =>
// Also handle the task failed reasons here.
failure match {
case Resubmitted =>
handleResubmittedFailure(task, stage)
case _ => // Do nothing.
}
// Always fail the current stage and retry all the tasks when a barrier task fail.
val failedStage = stageIdToStage(task.stageId)
if (failedStage.latestInfo.attemptNumber != task.stageAttemptId) {
logInfo(s"Ignoring task failure from $task as it's from $failedStage attempt" +
s" ${task.stageAttemptId} and there is a more recent attempt for that stage " +
s"(attempt ${failedStage.latestInfo.attemptNumber}) running")
} else {
logInfo(s"Marking $failedStage (${failedStage.name}) as failed due to a barrier task " +
"failed.")
val message = s"Stage failed because barrier task $task finished unsuccessfully.\n" +
failure.toErrorString
try {
// killAllTaskAttempts will fail if a SchedulerBackend does not implement killTask.
val reason = s"Task $task from barrier stage $failedStage (${failedStage.name}) " +
"failed."
taskScheduler.killAllTaskAttempts(stageId, interruptThread = false, reason)
} catch {
case e: UnsupportedOperationException =>
// Cannot continue with barrier stage if failed to cancel zombie barrier tasks.
// TODO SPARK-24877 leave the zombie tasks and ignore their completion events.
logWarning(s"Could not kill all tasks for stage $stageId", e)
abortStage(failedStage, "Could not kill zombie barrier tasks for stage " +
s"$failedStage (${failedStage.name})", Some(e))
}
markStageAsFinished(failedStage, Some(message))
failedStage.failedAttemptIds.add(task.stageAttemptId)
// TODO Refactor the failure handling logic to combine similar code with that of
// FetchFailed.
val shouldAbortStage =
failedStage.failedAttemptIds.size >= maxConsecutiveStageAttempts ||
disallowStageRetryForTest
if (shouldAbortStage) {
val abortMessage = if (disallowStageRetryForTest) {
"Barrier stage will not retry stage due to testing config. Most recent failure " +
s"reason: $message"
} else {
s"""$failedStage (${failedStage.name})
|has failed the maximum allowable number of
|times: $maxConsecutiveStageAttempts.
|Most recent failure reason: $message
""".stripMargin.replaceAll("\n", " ")
}
abortStage(failedStage, abortMessage, None)
} else {
failedStage match {
case failedMapStage: ShuffleMapStage =>
// Mark all the map as broken in the map stage, to ensure retry all the tasks on
// resubmitted stage attempt.
mapOutputTracker.unregisterAllMapOutput(failedMapStage.shuffleDep.shuffleId)
case failedResultStage: ResultStage =>
// Abort the failed result stage since we may have committed output for some
// partitions.
val reason = "Could not recover from a failed barrier ResultStage. Most recent " +
s"failure reason: $message"
abortStage(failedResultStage, reason, None)
}
// In case multiple task failures triggered for a single stage attempt, ensure we only
// resubmit the failed stage once.
val noResubmitEnqueued = !failedStages.contains(failedStage)
failedStages += failedStage
if (noResubmitEnqueued) {
logInfo(s"Resubmitting $failedStage (${failedStage.name}) due to barrier stage " +
"failure.")
messageScheduler.schedule(new Runnable {
override def run(): Unit = eventProcessLoop.post(ResubmitFailedStages)
}, DAGScheduler.RESUBMIT_TIMEOUT, TimeUnit.MILLISECONDS)
}
}
}
case Resubmitted =>
handleResubmittedFailure(task, stage)
case _: TaskCommitDenied =>
// Do nothing here, left up to the TaskScheduler to decide how to handle denied commits
case _: ExceptionFailure | _: TaskKilled =>
// Nothing left to do, already handled above for accumulator updates.
case TaskResultLost =>
// Do nothing here; the TaskScheduler handles these failures and resubmits the task.
case _: ExecutorLostFailure | UnknownReason =>
// Unrecognized failure - also do nothing. If the task fails repeatedly, the TaskScheduler
// will abort the job.
}
}DagScheduler.submitWaitingChildStages(shuffleStage)
- waitingStages中存的是所有待提交的Stage,过滤出,ShuffleMapStage的直接下级Stage,然后调用DagScheduler.submitStage(stage)进行提交,此时相当于DagScheduler.submitStage(ResultStage)
- 注意,此时由于ResultStage的parent stage 是ShuffleMapStage已经计算完成了,所以DagScheduler.getMissingParentStages 计算ResultStage的上级stage时,会为Nil,也就是为空,所以此时就提交ResultStage
/**
* Check for waiting stages which are now eligible for resubmission.
* Submits stages that depend on the given parent stage. Called when the parent stage completes
* successfully.
*/
private def submitWaitingChildStages(parent: Stage) {
logTrace(s"Checking if any dependencies of $parent are now runnable")
logTrace("running: " + runningStages)
logTrace("waiting: " + waitingStages)
logTrace("failed: " + failedStages)
val childStages = waitingStages.filter(_.parents.contains(parent)).toArray
waitingStages --= childStages
for (stage <- childStages.sortBy(_.firstJobId)) {
submitStage(stage)
}
}
DagScheduler.getMissingParentStages(Stage)
- 计算Stage的待提交上级Stage,如果上级Stage的所有任务已经完成,上级待提交Stage为空,就可以直接提交Stage
- 如果Stage上级Stage没有处理,就需要先提交上级Stage
- 如果上级Stage已提交,在if判断就进不来,waitingStages,runningStages,failedStages会记录已处理过的Stage
-
判断上级Stage是否可用的关键点
- stage.isAvailable返回true,所以这个时候!mapStage.isAvailable就不满足条件,就不会把mapStage加到missing中(就不会加到待提交的上级Stage中)
- 这个时候就可以提交ResultStage了
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new ArrayStack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}ShuffleMapStage.isAvailable
- numAvailableOutputs记录已完成的ShuffleMapStage任务数(已完成的ShufleMapTask个数)
- numPartitions,ShuffleMapStage的分区个数
- 如果这两个参数相等,相当于,ShuffleMapStage所有的ShuffleMapTask已经计算完成了
/**
* Number of partitions that have shuffle outputs.
* When this reaches [[numPartitions]], this map stage is ready.
*/
def numAvailableOutputs: Int = mapOutputTrackerMaster.getNumAvailableOutputs(shuffleDep.shuffleId)
/**
* Returns true if the map stage is ready, i.e. all partitions have shuffle outputs.
*/
def isAvailable: Boolean = numAvailableOutputs == numPartitions
end