
免费开通大数据服务:https://www.aliyun.com/product/odps
大数据平台的成熟使得更多种类的非结构化、半结构化的数据分析成为可能,其中应用非常广泛的一种场景就是日志分析。在日志类型数据的清洗转换过程中把IP地址转换为归属地又是极为常见的一种场景。那么利用MaxCompute如何实现IP地址向归属地的转换呢?
俗话说:巧妇难为无米之炊,要实现IP地址与归属地的转换必须要有IP地址库,不过好在互联网上已经有一些资源,而且还提供免费版本的IP数据库下载详见:www.ipip.net(请叫我雷锋^_^)。没错,我们首先要把它下载到本地,命名为ip.dat。
米已经有了,接下来就考虑怎么下厨了。想要在MaxCompute中实现用户自定义逻辑的代码处理,最常用的就是MR和SQL UDF。考虑到大部分用户使用偏好以及工作成果的可重用性,此处我们给大家介绍通过UDF的实现方式。如果客官还对MaxCompute如何实现UDF不熟悉,请自行脑补:https://help.aliyun.com/document_detail/27866.html,文档中都有代码示例。UDF分为三种,分别是UDF、UDAF、UDTF,此处不过多介绍,毫无疑问这种需求场景需要采用第一种实现。
实现用户自定义函数要继承com.aliyun.odps.udf.UDF,具体实现分两个步骤:
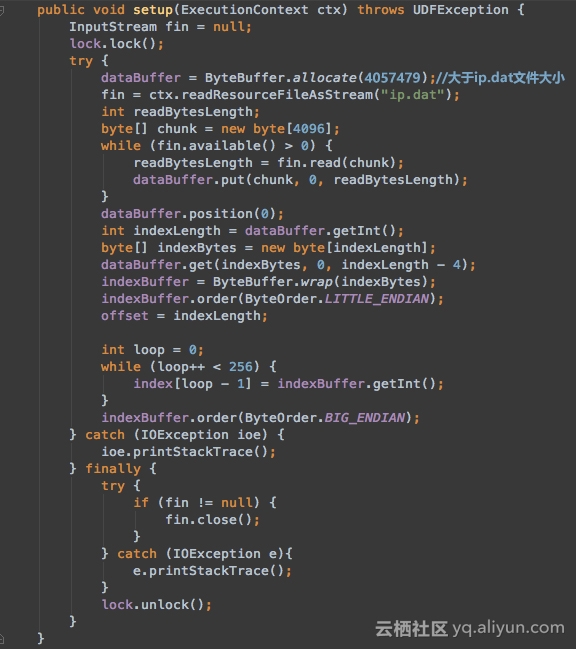
一、实现setup方法加载IP地址库数据,并做初始化,代码片段如下图:
注意:ip.dat 的大小,修改ByteBuffer.allocate(),不要溢出,可以大一些,如ByteBuffer.allocate(4057479)
二、实现evaluate方法,完成用户数据IP地址到归属地的转换逻辑,代码片段如下图:
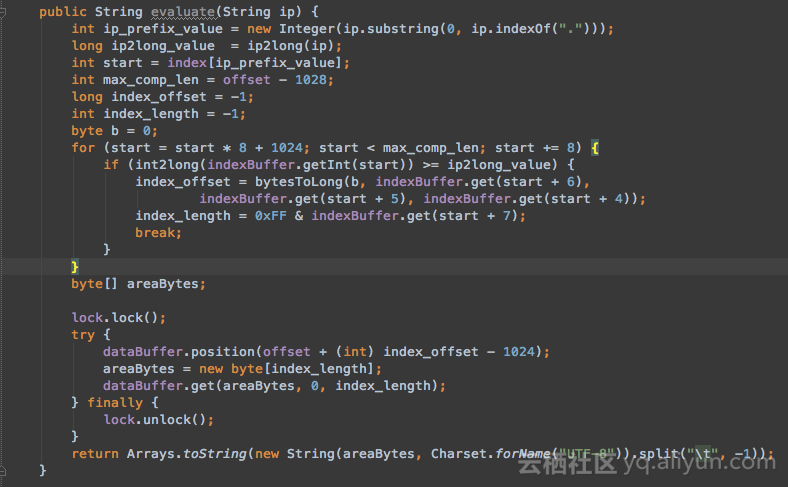
此处需要注意的是,MaxCompute中是采用UTF-8编码的,为了避免出现中文乱码,我们在输出是可以指定编码方式为UTF-8。
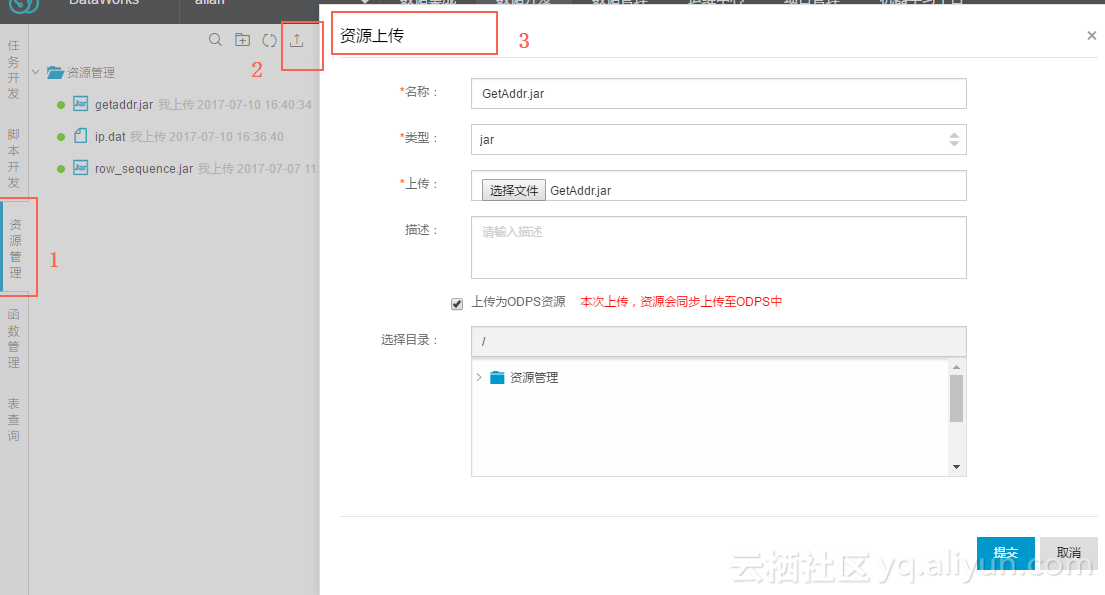
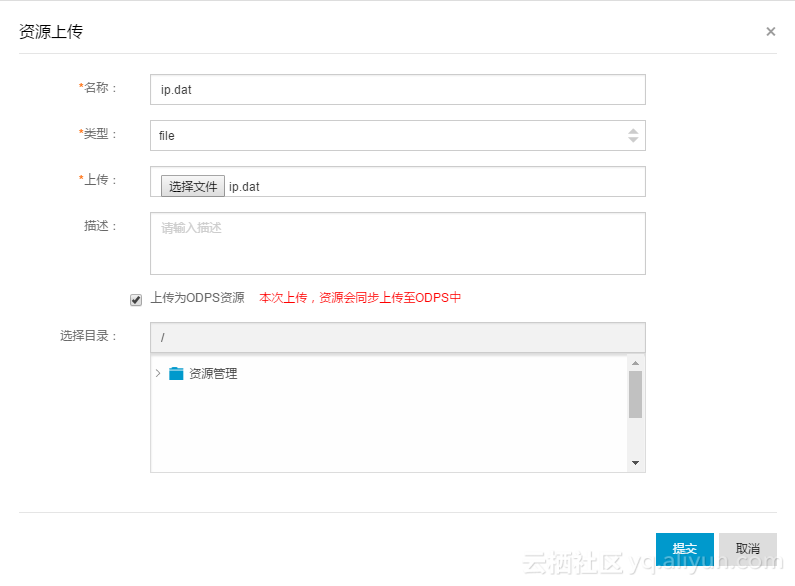
Coding完成后编译打包,命名为getaddr.jar。而后我们需要把ip.dat以及getaddr.jar作为资源上传到MaxCompute项目空间。上传资源可以通过数加DataIDE中向导的方式,也可以通过Console中执行命令的方式。两种方式截图如下:
方式一:
用阿里云数加大数据开发套件中的数据开发->函数管理上传getaddr.jar和ip.dat,如图。
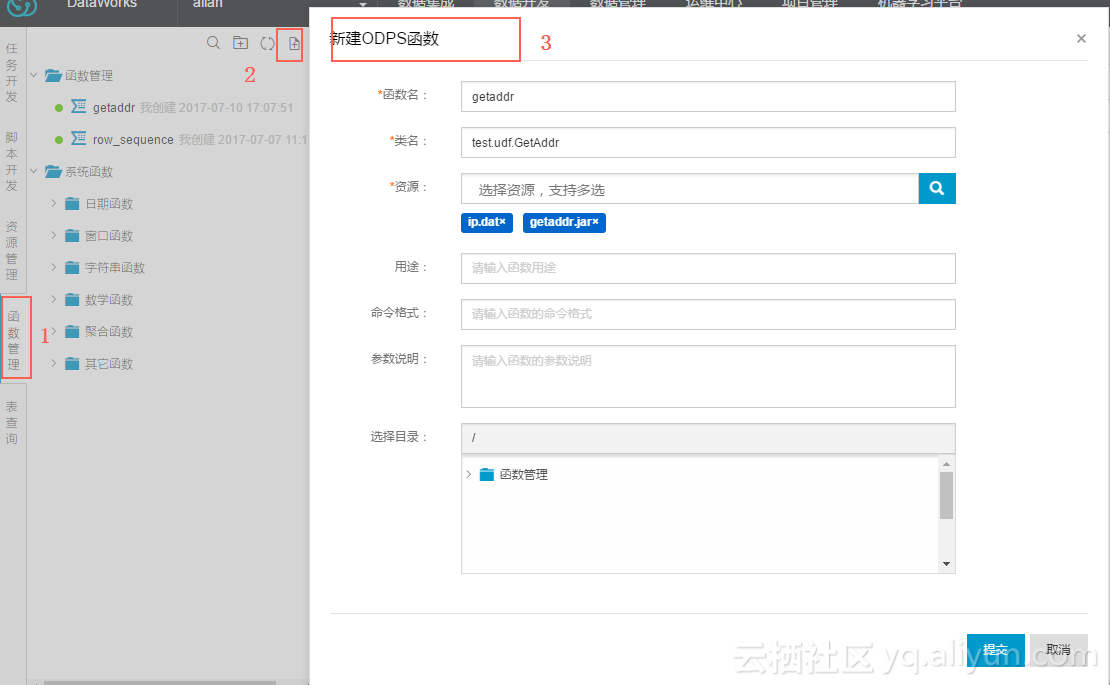
用数据开发->函数管理,注册UDF函数,命名getaddr。
注意:把上一步上传的getaddr.jar和ip.dat资源,注册为一个函数名,如图。
新建MaxCompute SQL任务,任选一张表,我这里用了user_info,执行
select getaddr('116.11.34.15') from user_info limit 1;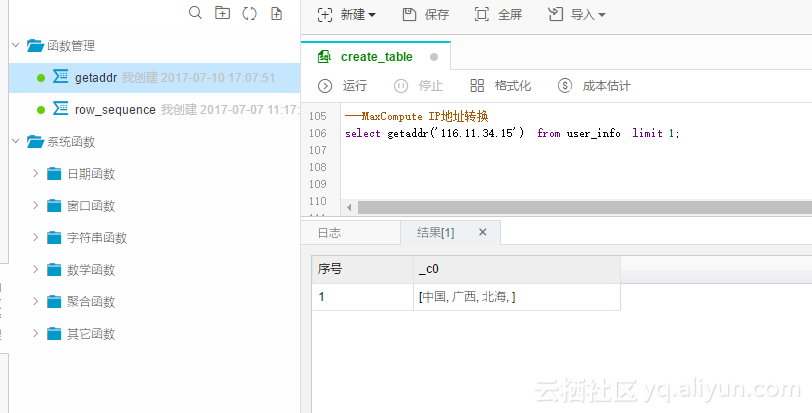
方式二:
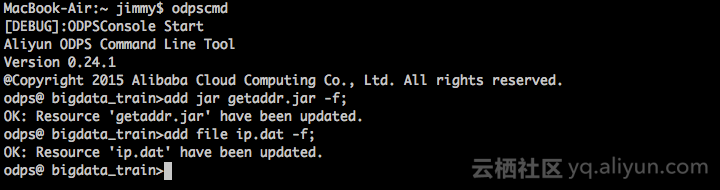
资源上传完毕后需要创建Function,在控制台或者数加DataIDE窗口中执行命令,如图:

至此,UDF已经实现完成,我们需要做个验证,比如我们可以通过UDF查询116.11.34.15这个IP地址的所属地,如下图:
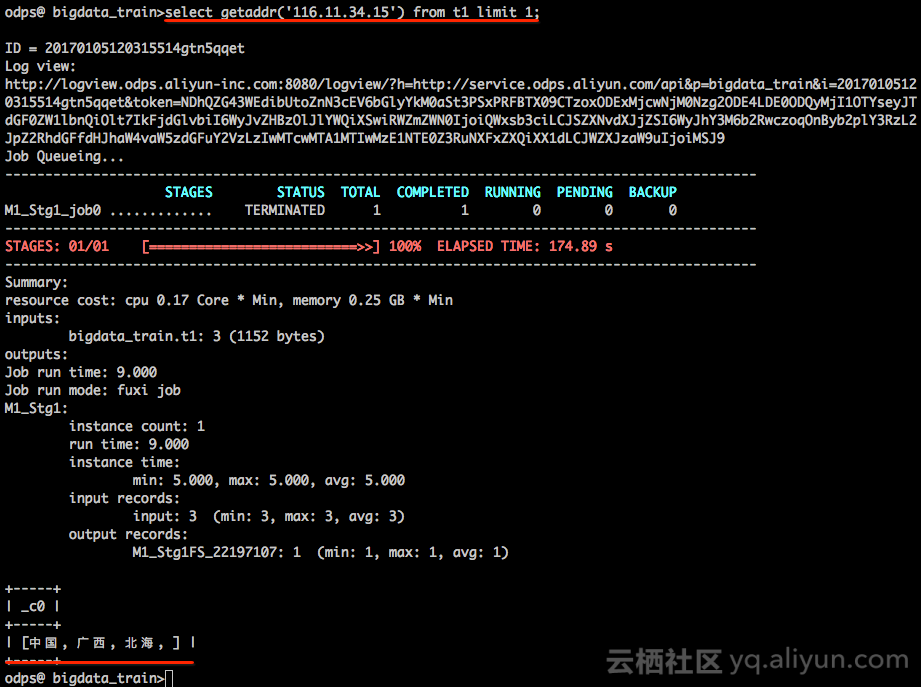
准确性验证,如下图:

当然准确性一方面是我们解析匹配的逻辑,更重要的也取决于IP地址库本身是否准确。
GetAddr.java代码下载:https://yq.aliyun.com/attachment/download/?spm=0.0.0.0.oMX36t&filename=GetAddr_...[%E9%9A%90%E6%9E%97].1499678865.rar
常见问题:
Q:用大数据开发套件执行报错,2017-07-10 14:51:48 M1_Stg1_job0:0/0/1[FAILED],FAILED: ODPS-0123131:User defined function exception - com_aliyun_odps_examples_udf_GetAddr - Call Java udf method.
A:注册函数的时候,没有附上ip.dat。
Q:用大数据开发套件执行报错,FAILED: ODPS-0123131:User defined function exception - Traceback:
java.nio.BufferOverflowException
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:189)
at odps.test.GetAddr.setup(GetAddr.java:144)
A:ByteBuffer.allocate(2657479)->ByteBuffer.allocate(4057479)根据ip.dat文件大小调大一些。


