袋鼠云日志团队时常遇到各种各样的甲方大人,毕竟我们是一个非常优秀的企业服务公司(自信满满),当然面对甲方大人的时候要做到处变不惊,临危不乱,镇定自若的接受需求……
甲方大人的常用台词一定要记住:我们很忙,有好几套监控系统,能不能再不砍掉监控系统的情况下,帮助我们搞定日运维需求呢?这样的需求每天通过项目经理→产品经理→研发经理→浣熊(我)。
But,这个需求有点麻烦呀~

我捋过我日渐稀疏的发,只能加油干啦!

先说下甲方大人的需求和痛点,甲方大人说平日的系统运维工作主要围绕应用、主机、数据库和业务四个方面。
(1)应用发布平台是IBM的WebSphereApplicationServer(简称WAS),应用的性能监控基于WAS自带监控模块
(2)主机监控基于IBMTivoliMonitoringSystem,业务监控则通过分析应用日志的方式实现
(3)数据库监控依赖一个古老的oracle性能监控工具
(4)应用日志需要登陆到AIX业务机器上查看
“每当出现一个问题,先登陆was看下业务进程性能趋势,再登陆Tivoli查看主机性能趋势,然后登陆数据库监控查看数据库性能趋势,再然后登陆AIX主机查看日志。一套下来肚子就饿了,到食堂发现好吃的饭菜已经被别人抢光了,希望你们能帮我们改善改善伙食“。嗯,听上去影响蛮大的,不过他们怎么知道我烧菜的手艺的,上周末做的清蒸鲈鱼味道还不错...
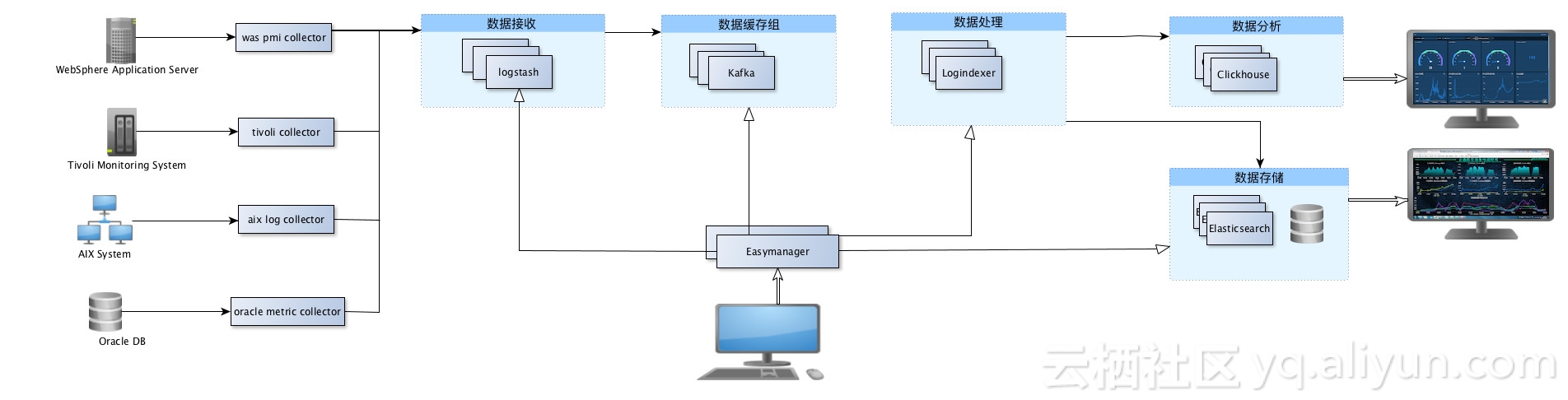
四个字,赶紧干活。在了解了甲方大人的需求和痛点后,经过一番苦思冥想,设计了下面的看上去有点复杂的架构图。大道至简,借鉴老子的一段话附和一下这张图,“人法地、地法天、天法道、道法自然”,老子用了十三个字,将天、地、人乃至整个宇宙的生命规律精辟涵括、阐述出来。
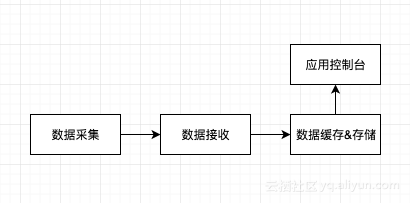
菜谱准备好了,小葱拌豆腐,开始下锅。
数据采集上,针对WAS、Tivoli、Oracle和AIX应用主机的采集需求,需要coding了(没有什么需求是一坨代码解决不了的,如果有那就两坨),前方高能,请做好笔记:
(1)开发一个WAS进程性能采集器,参考https://github.com/alexivkin/WebSphere-Performance-Monitor,万能的python,哦no,这个是Jython,看起来跟python一样嘛,无非就是python里面用java,java里面跑python。由于是三年前的版本,加上没有IBM WAS的测试环境,花掉一个上午时间脑补调试,什么是脑补调试法,答按行过目代码、眼睛输入,大脑跑跑(非专业人士请勿模仿);
(2)开发一个Tivoli数据收集器,又花掉一个晚上,Tivoli支持Soap方式拉取新能数据,我不会告诉你可以用一个CURL拉取所有主机性能所有数据的,想知道的留言处扣666;
(3)开发一个Oracle数据库性能采集器,还好elastic 大佬开源了beats(https://github.com/elastic/beats),坑爹的是竟然不支持oracle,莫非oracle大佬的开发人员都休眠了么;花了两个晚上捣鼓捣鼓,支持个tps、qps、物理读、逻辑度、吞吐量还是可以的,小算一下支持200多个指标吧,oracle采集beat依赖oracle client不是一般的麻烦;
https://www.oracle.com/technetwork/topics/intel-macsoft-096467.html
(4)开发一个AIX日志文件采集器,袋鼠云有技术大牛开发了一个,拿过来直接集成;
https://github.com/DTStack/jfilebeat
数据接收和解析组件,袋鼠云自研了java版本的logstash,参考:
https://github.com/DTStack/jlogstash
日志接收和解析性能是ruby版本性能5倍以上,关键是配置简单,分钟内上手![]()
数据存储方面,最近一周的日志数据全部投递到elasticsearch里,以防哪天甲方大人心血来潮想搜个日志啥的;结构化的应用进程数据、主机性能数据、数据库性能数据和业务日志数据投递到clickhouse里,通过clickhouse强大的聚合计算能力(多表数据关联,sum/avg等聚合计算),计算出同一时间线上的业务和进程、主机以及数据库性能的关联趋势图。
一句话总结下ck吧,在sql里计算我只服ck!
链接:
https://clickhouse-docs.readthedocs.io/en/latest/functions/
源码请见:
https://github.com/yandex/ClickHouse
坚持看到这里就是真爱了,贴上一张系统架构图,图中左方是数据采集层,easymanager是公司自研的自动部署神器(不用想了,没有开源),右边是数据展示端,把应用、主机、数据库、日志数据统一展示在一张大屏上,废话不说了,上菜!