Kubeflow(https://github.com/kubeflow)是基于Kubernetes(https://kubernets.io,容器编排与管理服务软件)和TensorFlow(https://tensorflow.org,深度学习库)的机器学习流程工具,使用Ksonnet进行应用包的管理。
本文简要介绍Kubeflow的部署和交互操作的基本概念和方法,对于Kubernetes、Tensorflow和Ksonnet 的了解对于本文内容的理解将 很有帮助,点击下面的链接查看相关的内容。
对部署Kubeflow和运行一个简单的训练任务的手把手教的例子,可以看这个教程( tutorial)。
环境要求
- Kubernetes>=1.8, see here,安装攻略 https://my.oschina.net/u/2306127/blog/1628082
- ksonnet version 0.9.2. (查看 below 有对为什么使用ksonnet的解释)
部署 Kubeflow
我们将使用Ksonnet来部署kubeflow到Kubernetes集群上,支持本地的和GKE、Azure中的集群。
初始化一个目录,包含有ksonnet application。
ks init my-kubeflow
安装Kubeflow packages到Ksonnet application中。
# For a list of releases see: # https://github.com/kubeflow/kubeflow/releases
VERSION=v0.1.2
cd my-kubeflow
ks registry add kubeflow github.com/kubeflow/kubeflow/tree/${VERSION}/kubeflow
ks pkg install kubeflow/core@${VERSION}
ks pkg install kubeflow/tf-serving@${VERSION}
ks pkg install kubeflow/tf-job@${VERSION} 创建Kubeflow core component. 这个core component 包括:
- JupyterHub
- TensorFlow job controller
ks generate core kubeflow-core --name=kubeflow-core
# Enable collection of anonymous usage metrics # Skip this step if you don't want to enable collection. # Or set reportUsage to false (the default).
ks param set kubeflow-core reportUsage true
ks param set kubeflow-core usageId $(uuidgen)
Ksonnet 允许参数化 Kubeflow的部署,可以按照需求设定。我们定义两个环境变量:nocloud和cloud。
ks env add nocloud
ks env add cloud
环境变量 nocloud 用于 minikube和其它的标准 k8s clusters,环境变量 cloud 用于GKE和Azure。
如果使用 GKE, 我们配置云计算环境的参数来使用 GCP的特征,如下:
ks param set kubeflow-core cloud gke --env=cloud 如果集群创建在 Azure 上,使用 AKS/ACS:
ks param set kubeflow-core cloud aks --env=cloud 如果创建时使用acs-engine来代替:
ks param set kubeflow-core cloud acsengine --env=cloud 然后我们设置 ${KF_ENV} 为 cloud 或 nocloud ,从而反映我们在本教程中使用的环境。
$ KF_ENV=cloud|nocloud - 缺水情况下,Kubeflow没有持久化我们在Jupyter notebook所做的工作。
- 如果容器被销毁或重新创建,所有的内容,包括 notebooks 和其它的文件都会被删除。
- 为了持久化这些文件,用户需要一个缺省的 StorageClass,在 persistent volumes 中定义。
- 可以运行下面的命令来检查是否有了一个 storage class。
kubectl get storageclass
-
有了缺省的storage class定义的用户,可以使用jupyterNotebookPVCMount参数去创建一个volume,将被挂载到notebook之中。
ks param set kubeflow-core jupyterNotebookPVCMount /home/jovyan/work- 这里我们挂载卷到
/home/jovyan/work,因为notebook一直以用户jovyan来执行。 - 选中的目录将被存储到集群的缺省存储上(典型地是永久磁盘)。
- 这里我们挂载卷到
创建部署的命名空间(namespace)并且设为换的一部分。可以将namespace设为更适合你自己的kubernetes cluster的名称,如下。
NAMESPACE=kubeflow
kubectl create namespace ${NAMESPACE}
ks env set ${KF_ENV} --namespace ${NAMESPACE} 然后应用该components到我们的Kubernetes cluster。
ks apply ${KF_ENV} -c kubeflow-core
任何时候,可以使用 ks show 探查特定的 ksonnet component在kubernetes的对象定义。
ks show ${KF_ENV} -c kubeflow-core
用法报告(Usage Reporting)
当启用时,Kubeflow将使用 spartakus 报告匿名数据,这是Kubernetes的一个汇报工具。Spartakus不会报告任何个人信息。查看 here 得到更多细节。这是完全志愿的行为,也可以可选将其关闭,如下所示:
ks param set kubeflow-core reportUsage false
# Delete any existing deployments of spartakus
kubectl delete -n ${NAMESPACE} deploy spartakus-volunteer
为了明确开启用法报告,设置 reportUsage 为 true,如下所示:
ks param set kubeflow-core reportUsage true
# Delete any existing deployments of spartakus
kubectl delete -n ${NAMESPACE} deploy spartakus-volunteer
报告数据是你对Kubeflow的显著贡献之一,所以请考虑将其开启。这些数据允许我们改善Kubeflow项目并且帮助Kubeflow上开展工作的企业评估其持续的投资。
你可以改进数据质量,通过给每一个Kubeflow deployment 一个单独的ID。
ks param set kubeflow-core usageId $(uuidgen)
打开 Jupyter Notebook
这里的 kubeflow-core component 部署JupyterHub和对应的load balancer service,查看状态使用下面的 kubectl 命令行:
kubectl get svc -n=${NAMESPACE}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
tf-hub-0 ClusterIP None <none> 8000/TCP 1m
tf-hub-lb ClusterIP 10.11.245.94 <none> 80/TCP 1m
...
缺水情况下,我们使用ClusterIPs来访问JupyterHub UI,在下面情况会有所改变:
-
NodePort (for non-cloud) ,通过指示:
ks param set kubeflow-core jupyterHubServiceType NodePort ks apply ${KF_ENV} -
LoadBalancer (for cloud) ,通过指示:
ks param set kubeflow-core jupyterHubServiceType LoadBalancer ks apply ${KF_ENV}
但是,这将使 Jupyter notebook 开放予Internet网络(有潜在的安全风险)。
本地连接到 Jupyter Notebook 可以使用:
PODNAME=`kubectl get pods --namespace=${NAMESPACE} --selector="app=tf-hub" --output=template --template="{{with index .items 0}}{{.metadata.name}}{{end}}"`
kubectl port-forward --namespace=${NAMESPACE} $PODNAME 8000:8000 然后,到浏览器中打开 http://127.0.0.1:8000,如果设置了代理,需要对该地址关闭 。
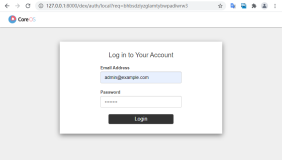
将看到一个提示窗口。
-
使用任何username/password登录。
-
点击 "Start My Server" 按钮,将会打开一个对话框。
-
选择镜像为CPU 或 GPU 类型,在 Image一项有菜单列出预构建的Docker镜像。也可以直接输入Tensorflow的镜像名称,用于运行。
-
分配内存、CPU、GPU和其他的资源,根据需求而定。 (1 CPU 和 2Gi 内存已经是一个好的起点,可以满足初始练习的需要。)
- 分配 GPUs, 需要确认你的集群中有可用数量的 GPUs,GPU将会被容器实例独占使用,如果资源不够,该实例将会一直挂起,处于Pending状态。
- 检查是否有足够的nvidia gpus可用:
kubectl get nodes "-o=custom-columns=NAME:.metadata.name,GPU:.status.allocatable.nvidia\.com/gpu" - 如果 GPUs 可用,你可以调度你的服务器到 GPU node,通过指定下面的json, 在
Extra Resource Limitssection:{"nvidia.com/gpu": "1"}
-
点击 Spawn
-
该镜像将近 10 GBs,下载需要比较长的时间,取决于网络情况。
-
检查 pod 的状态,通过:
kubectl -n ${NAMESPACE} describe pods jupyter-${USERNAME}-
这里 ${USERNAME} 是你 login时用到的名称。
-
GKE users,如果你有 IAP turned on the pod,将会名称有所不同:
- 如果登陆为像 USER@DOMAIN.EXT, pod 被命名为:
jupyter-accounts-2egoogle-2ecom-3USER-40DOMAIN-2eEXT
-
-
-
完成后,将会打开 Jupyter Notebook 初始界面。
上面提供的容器镜像可以用于 Tensorflow models的训练,使用Jupyter即可操作。该镜像包含所有需要的plugins, 包括 Tensorboard,可以用于对模型进行丰富的可视化和探查分析。
未来测试安装情况,我们运行一个基本的hello world应用 (来自 mnist_softmax.py )
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.05).minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
粘贴上面的例子到新的 Python 3 Jupyter notebook,然后 shift+enter 执行代码。这里会得到基于测试数据的 0.9014 结果精度。
需要注意的是,运行大多数 cloud providers时,public IP address 将会暴露到internet,并且缺省是没有安全控制的endpoint。为了产品级部署,需要使用 SSL 和 authentication, 参考 documentation。
使用TensorFlow Serving提供model服务
我们将每一个部署的模型都作为APP中的 component 。
在云计算中创建一个模型的component:
MODEL_COMPONENT=serveInception
MODEL_NAME=inception
MODEL_PATH=gs://kubeflow-models/inception
ks generate tf-serving ${MODEL_COMPONENT} --name=${MODEL_NAME}
ks param set ${MODEL_COMPONENT} modelPath ${MODEL_PATH}
(或者) 创建一个model的component 在 nfs 上,了解和参考 components/k8s-model-server,如下:
MODEL_COMPONENT=serveInceptionNFS
MODEL_NAME=inception-nfs
MODEL_PATH=/mnt/var/nfs/general/inception
MODEL_STORAGE_TYPE=nfs
NFS_PVC_NAME=nfs
ks generate tf-serving ${MODEL_COMPONENT} --name=${MODEL_NAME}
ks param set ${MODEL_COMPONENT} modelPath ${MODEL_PATH}
ks param set ${MODEL_COMPONENT} modelStorageType ${MODEL_STORAGE_TYPE}
ks param set ${MODEL_COMPONENT} nfsPVC ${NFS_PVC_NAME} 部署model component。Ksonnet将选择你的环境中的已存在的参数 (e.g. cloud, nocloud),然后定制化结果部署为合适的:
ks apply ${KF_ENV} -c ${MODEL_COMPONENT} 之前, 一些pods和services已经创建在你的集群中。你可以查询kubernetes得到服务endpoint:
kubectl get svc inception -n=${NAMESPACE}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
inception LoadBalancer 10.35.255.136 ww.xx.yy.zz 9000:30936/TCP 28m
...
在这里,你可以使用的 inception_client 为 ww.xx.yy.zz:9000
在gs://kubeflow-models/inception 的model 是可以公开访问的。但是,如果你的环境没有配置google cloud credential,TF serving 将无法读取model,查看 issue 获取样本。为了设置google cloud credential,你需要环境变量 GOOGLE_APPLICATION_CREDENTIALS 指向credential 文件,或者运行 gcloud auth login. 查看 doc 获取更多详细说明。
通过 Seldon 服务 model
Seldon-core 提供了任意机器学习运行时的部署,将其 packaged in a Docker container。
安装seldon package:
ks pkg install kubeflow/seldon
创建 core components:
ks generate seldon seldon
Seldon 允许复杂的 runtime graphs用于模型推理的部署。一个 end-to-end整合的例子参见 kubeflow-seldon example。更多的细节参考 seldon-core documentation。
提交一个TensorFlow训练任务
注意:在提交训练任务之前,你首先需要有一个 deployed kubeflow to your cluster。提交训练任务时,首先确认 TFJob custom resource 是可用的。
我们将每一个TensorFlow job作为APP中的 component 看待。
A、创建工作任务
为训练任务创建 component:
JOB_NAME=myjob
ks generate tf-job ${JOB_NAME} --name=${JOB_NAME} 为了配置这个 job需要设置一系列的参数。为了查看参数列表,运行:
ks prototype describe tf-job
参数设置使用 ks param ,设置 Docker image 使用:
IMAGE=gcr.io/tf-on-k8s-dogfood/tf_sample:d4ef871-dirty-991dde4
ks param set ${JOB_NAME} image ${IMAGE} 你可以编辑 params.libsonnet 文件,直接设置参数。
警告 由于escaping序列问题,目前命令行的设置参数不能工作 (参见 ksonnet/ksonnet/issues/235)。因此,设置参数需要直接编辑 params.libsonnet 文件。
B、运行工作任务
ks apply ${KF_ENV} -c ${JOB_NAME} C、监视工作任务
监视任务执行情况,参见 TfJob docs.
D、删除工作任务
ks delete ${KF_ENV} -c ${JOB_NAME}
运行例程-TfCnn
Kubeflow 附带了一个 ksonnet prototype ,适合运行 TensorFlow CNN Benchmarks。
创建component:
CNN_JOB_NAME=mycnnjob
ks generate tf-cnn ${CNN_JOB_NAME} --name=${CNN_JOB_NAME}
提交任务:
ks apply ${KF_ENV} -c ${CNN_JOB_NAME} 查看运行情况 (注意 tf-cnn job 也是 tfjobs. 参考 TfJob docs)
kubectl get -o yaml tfjobs ${CNN_JOB_NAME} 删除任务:
ks delete ${KF_ENV} -c ${CNN_JOB_NAME}
该 prototype提供了一系列参数控制任务的运行 (如使用 GPUs,分布式运行等...)。查看参数运行:
ks prototype describe tf-cnn
提交 PyTorch 训练任务
注意:在提交任务之前,你需要有一个部署好Kubeflow的集群(参见 deployed kubeflow to your cluster)。提交,确保 PyTorchJob custom resource 可用。
我们将每一个PyTorch任务看作为APP中的 component 。
为工作任务创建一个 component。
JOB_NAME=myjob
ks generate pytorch-job ${JOB_NAME} --name=${JOB_NAME} 为了配置工作任务,需要设置一系列的参数。 显示参数使用:
ks prototype describe pytorch-job
参数设置使用 ks param ,设置Docker image 使用:
IMAGE=<your pytorch image>
ks param set ${JOB_NAME} image ${IMAGE} 也可以编辑文件 params.libsonnet 来直接设置参数。
警告 由于escaping序列问题,目前命令行的设置参数不能工作 (参见 ksonnet/ksonnet/issues/235)。因此,设置参数需要直接编辑 params.libsonnet 文件。
运行工作任务:
ks apply ${KF_ENV} -c ${JOB_NAME} 删除工作任务:
ks delete ${KF_ENV} -c ${JOB_NAME}
高级定制
- 数据科学家经常要求一个 POSIX 兼容的文件系统:
- 例如,大多数HDF5 libraries 要求 POSIX,对于GCS或S3的object store无法工作。
- 当共享 POSIX 文件系统被挂载到 notebook 环境,数据科学家可以在同一数据集上协同工作。
- 这里将展示如何部署Kubeflow来达到这个要求。
设置磁盘参数,以分号隔开,设置你想要挂载的 Google persistent disks。
- 这些磁盘必须在你的集群的同一个 zone 上。
- 这些磁盘需要通过 gcloud 或 Cloud console手动创建。
- 这些磁盘不能被引用到任何已存在的 VM 或 POD上。
创建磁盘:
gcloud --project=${PROJECT} compute disks create --zone=${ZONE} ${PD_DISK1} --description="PD to back NFS storage on GKE." --size=1TB
gcloud --project=${PROJECT} compute disks create --zone=${ZONE} ${PD_DISK2} --description="PD to back NFS storage on GKE." --size=1TB
配置环境来使用这些磁盘:
ks param set --env=cloud kubeflow-core disks ${PD_DISK1},${PD_DISK2} 部署环境。
ks apply cloud
启动Juptyer,你将可以看见你的 NFS volumes 挂载为 /mnt/${DISK_NAME}。在Juptyer cell中运行:
!df 将看到如下的输出:
https://github.com/jlewi/deepvariant_on_k8s
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 98884832 8336440 90532008 9% /
tmpfs 15444244 0 15444244 0% /dev
tmpfs 15444244 0 15444244 0% /sys/fs/cgroup
10.11.254.34:/export/pvc-d414c86a-e0db-11e7-a056-42010af00205 1055841280 77824 1002059776 1% /mnt/jlewi-kubeflow-test1
10.11.242.82:/export/pvc-33f0a5b3-e0dc-11e7-a056-42010af00205 1055841280 77824 1002059776 1% /mnt/jlewi-kubeflow-test2
/dev/sda1 98884832 8336440 90532008 9% /etc/hosts
shm 65536 0 65536 0% /dev/shm
tmpfs 15444244 0 15444244 0% /sys/firmware
- 这里
jlewi-kubeflow-test1和jlewi-kubeflow-test2是 PDs的名称。
问题解决
Minikube
在 Minikube ,Virtualbox/VMware drivers是已知在 KVM/KVM2 driver 和 TensorFlow Serving之间的问题. 该问题跟踪在 kubernetes/minikube#2377。
我们建议增加 Minikube分配的资源总量,如下:
minikube start --cpus 4 --memory 8096 --disk-size=40g - Minikube 缺省分配 2048Mb RAM给虚拟机,对于 JupyterHub是不够的。
- 最大的磁盘容量需要满足 Kubeflow's Jupyter images,包含额外的库超过10G以上。
如果遇到jupyter-xxxx pod 进入Pending 状态,获取描述信息:
Warning FailedScheduling 8s (x22 over 5m) default-scheduler 0/1 nodes are available: 1 Insufficient memory.
- 然后尝试重新创建 Minikube cluster (重新使用Ksonnet应用 Kubeflow) ,并指定更多的资源。
RBAC clusters
如果你运行的集群开启了RBAC(参考 RBAC enabled),,运行Kubeflow可能遇到如下的错误:
ERROR Error updating roles kubeflow-test-infra.jupyter-role: roles.rbac.authorization.k8s.io "jupyter-role" is forbidden: attempt to grant extra privileges: [PolicyRule{Resources:["*"], APIGroups:["*"], Verbs:["*"]}] user=&{your-user@acme.com [system:authenticated] map[]} ownerrules=[PolicyRule{Resources:["selfsubjectaccessreviews"], APIGroups:["authorization.k8s.io"], Verbs:["create"]} PolicyRule{NonResourceURLs:["/api" "/api/*" "/apis" "/apis/*" "/healthz" "/swagger-2.0.0.pb-v1" "/swagger.json" "/swaggerapi" "/swaggerapi/*" "/version"], Verbs:["get"]}] ruleResolutionErrors=[]
该错误指示没有足够的权限。在大多数情况下,解决这个问题通过创建合适的 clusterrole binding 然后重新部署kubeflow:
kubectl create clusterrolebinding default-admin --clusterrole=cluster-admin --user=your-user@acme.com - 替换
your-user@acme.com为在错误信息提示的用户名。
如果你使用 GKE, 你可以参考 GKE's RBAC docs 去了解如何设置 RBAC,通过 IAM on GCP来实现。
spawning Jupyter pods的问题
如果你 spawning jupyter notebooks遇到麻烦,检查该 pod 是否已经被调度运行:
kubectl -n ${NAMESPACE} get pods
- 查看启动juypter的pod名称。
- 如果使用username/password auth,Jupyter pod 将被命名:
jupyter-${USERNAME} -
如果你使用 IAP on GKE,pod 将被命名为:
jupyter-accounts-2egoogle-2ecom-3USER-40DOMAIN-2eEXT- 这里 USER@DOMAIN.EXT 是在使用IAP时的Google account。
一旦你知道pod的名称:
kubectl -n ${NAMESPACE} describe pods ${PODNAME} - 查看events ,可以看到试图schedule pod的错误原因。
- 无法schedule pod的常见原因是集群上没有足够的资源可用。
OpenShift
如果部署 Kubeflow 在 OpenShift 环境( 是对 Kubernetes的封装),你需要调整 security contexts,为了ambassador 和 jupyter-hub 部署的运行。
oc adm policy add-scc-to-user anyuid -z ambassador
oc adm policy add-scc-to-user anyuid -z jupyter-hub
一旦安全策略设置好,你需要删除失败的pods 然后允许在 project deployment时可以重新创建。
你需要调整 tf-job-operator service 张好的权限,以使TFJobs能够运行。如下运行一个TFJobs:
oc adm policy add-role-to-user cluster-admin -z tf-job-operator Docker for Mac
Docker for Mac 社区版带有Kubernetes支持 (1.9.2) ,可以从edge channel启用。如果决定私用 Kubernetes environment on Mac,部署 Kubeflow时可能遇到如下的问题:
ks apply default -c kubeflow-core
ERROR Attempting to deploy to environment 'default' at 'https://127.0.0.1:8443', but cannot locate a server at that address
该错误是因为Docker for Mac安装时设置的缺省集群为 https://localhost:6443.,一个选项是直接编辑创建的 environments/default/spec.json 文件设置 "server" 变量为正确的位置,然后重试部署。不过,更好的方式是使用希望的kube config来创建Ksonnet app。
kubectl config use-context docker-for-desktop
ks init my-kubeflow
403 API rate limit 超出错误
因为 ksonnet 使用 Github 拉取 kubeflow,除非用户指定Github API token,将会快速消耗最大的 API 匿名调用限量,为了解决该问题,可以创建 Github API token,参考这里 guide,,然后将该token 赋给GITHUB_TOKEN 环境变量。
export GITHUB_TOKEN=<< token >>
ks apply 产生错误 "Unknown variable: env"
Kubeflow 要求版本 0.9.2 或更高,查看 see here。如果你运行 ks apply 使用的老版本ksonnet,将得到错误 Unknown variable: env ,如下所示:
ks apply ${KF_ENV} -c kubeflow-core
ERROR Error reading /Users/xxx/projects/devel/go/src/github.com/kubeflow/kubeflow/my-kubeflow/environments/nocloud/main.jsonnet: /Users/xxx/projects/devel/go/src/github.com/kubeflow/kubeflow/my-kubeflow/components/kubeflow-core.jsonnet:8:49-52 Unknown variable: env
namespace: if params.namespace == "null" then env.namespace else params.namespace
检查ksonnet 版本,如下:
ks version
如果 ksonnet版本低于 v0.9.2, 请升级并按照 user_guide 重新创建app。
为什么 Kubeflow 要使用 Ksonnet?
Ksonnet 是一个命令行工具,使管理包含多个部件的复杂部署变得更为容易,设计为与kubectl各自完成特定的操作。
Ksonnet 允许我们从参数化的模版中创建 Kubernetes manifests。这使参数化 Kubernetes manifests 用于特定的场景变得容易。在上面的例子中,我们为 TfServing 创建了manifests,为model提供用户化的URI。
我蛮喜欢ksonnet的一个原因是,对待 environment (如dev, test, staging, prod) 作为头等的概念。对于每一个环境,我们部署同样的 components只需要对特定环境有一些很小的定制化修改。我们认为这对于通常的工作流来说是非常友好的一种映射。例如,该特征让在本地没有GPU的情况下运行任务,使代码运行通过,然后将其移到带有大量GPU可规模伸缩的云计算环境之中。
本文转自开源中国-Kubeflow 使用指南