1、为什么选择 Nginx
Nginx 是一个 web 服务器,常用作反向代理、负载均衡以及 web 缓存。天生具有高并发能力,并且具有速度快、功能丰富、可靠性高以及占用资源少等诸多优点。
Nginx 在容器化/云端部署方面十分普遍,并且根据最新的 Docker 使用报告,在 45000 个样本容器中,使用量最大的就是 nginx。
Nginx 可以作为一个 Web 应用服务器,也可以一组微服务的网关或负载,甚至可以作为网络入口(Internet-facing entrypoint)(就好像 Kubernetes 的 Ingress 控制器那样)。当作为负载均衡器时,与 nginx 相似的其他可供选择的方案有:HAProxy、新流行起来的 Linkerd、像 AWS ELB 那样的公有云、或者负载均衡器硬件设备。
2、Nginx的 stub_status 配置
为了能够暴露出nginx 的内部运行情况(internal performance metrics)和连接状态(connection status metrics),需要启用 stub_status 模块。付费版的 Nginx Plus 可以提供一些额外的监控维度,能够通过 status 模块更好的展现连接状态报告(connection status reporting )和 HTTP 返回码计数(HTTP return code counters),尽管如此,稍后 Sysdig 也能够将为大家呈现其中的部分信息。
默认情况下,nginx 的 Docker 官方镜像 和常见的 linux 发行版的二进制包中,已经包含了该模块。
运行 nginx -V,查找其中的 –with-http_stub_status_module 来确定该模块是否被启用。
$ docker exec -ti nginx nginx -V nginx version: nginx/1.11.13 built by gcc 4.9.2 (Debian 4.9.2-10) built with OpenSSL 1.0.1t 3 May 2016 TLS SNI support enabled configure arguments: --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx ... --with-http_stub_status_module ...
如果你需要引入一些必要的额外的配置来启用该模块,可以使用 kubernetes 的 ConfigMap。如果你需要一些自定义的配置,也可以直接自定义一个 Nginx 镜像。
下面是 nginx 的默认配置文件nginx.conf,在 /nginx_status 里启用 stub_status ,然后将请求代理到一个 Kubernetes 的 wordpress 服务中。
server { server_name _; location /nginx_status { stub_status on; access_log on; allow all; # REPLACE with your access policy } location / { proxy_pass http://wordpress:5000; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_redirect off; } }
[查看完整的 nginx.conf 文件]
下面创建 ConfigMap 来应用我们刚才创建的 nginx.conf 配置文件:
$ kubectl create configmap nginxconfig --from-file nginx.conf
接下来就可以在 Kubernetes 中通过 Deployment, ReplicaSet 或者 ReplicationController 来创建 nginx 容器,然后通过 Service 暴露为一个 Kubernetes 服务:
$ kubectl create -f nginxrc.yaml
查看完整的 nginxrc.yaml 文件]
3、查看Nginx的状态
如果使用类似curl的命令请求我们刚刚配置好的服务链接,应该得到类似下面这样的内容:
$ curl nginx-wordpress/nginx_status Active connections: 6 server accepts handled requests 100956 100956 101022 Reading: 0 Writing: 4 Waiting: 2
这仅仅是个开始,你可以想要得到更多的监控信息,比如:historical data, graphs, dashboards, alerts…
可以通过 Kubernetes 的 metadata 和 labels 来配置所有的这些监控维度,之后你就可以得到像“每个服务的平均请求时间(Average request time per service)”或者在进程日志中可以看到的一些像 “top HTTP requests” 和 “slowest HTTP requests” 等比较常见的信息。所有这些 nginx 的状态模块提供的监控维度信息, Sysdig Monitor 也都可以实现。
你可以开启一个 SysDig Monitor 的免费版本 , 这里 介绍了如何使用 Kubernetes 的 DaemonSet 来安装代理。
4、Nginx 的监控维度
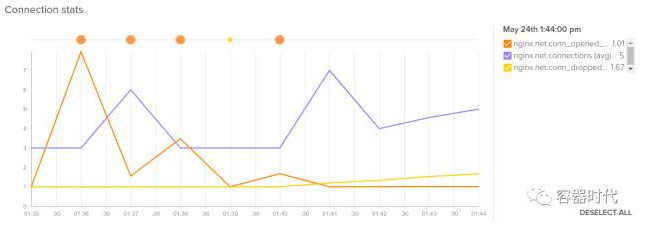
A、Nginx 连接
Nginx 提供了来自于客户端的 TCP 连接信息,以及这些连接相关联的 HTTP 请求和响应信息。在 HTTP/1 中每个请求只需要一个连接,但是在 HTTP/2 中每个连接中可能会发起多次请求。为了加速请求,这些长连接可能会一直保持开启等待状态,来等待处理同一个客户端可能会发生的多次请求,这个也叫做 Keepalive。
- 网络连接 nginx.can_connect:一个检查 nginx 服务是否可用的二进制值
- 当前连接数 nginx.net.connections:当前激活的总连接数
- 每秒产生的新连接数 nginx.net.conn_opened_per_s:每秒产生新连接的速度,和上面的 nginx.net.connections 对比一下,你就可以得到一个有效的吞吐量值。
- 每秒被丢弃的连接数 nginx.net.conn_dropped_per_s:被 nginx 服务器每秒丢弃的连接数,丢弃的原因可能是无效的客户端请求、服务器端的速率限制或者其他的 nginx 配置规则。
B、Nginx HTTP 应用维度
Nginx+ 中可以看到 HTTP 响应码,但如果想要看到像请求时间这样的更高级的维度信息,我们需要在日志模块(log module)中开启 $request_time,这样通过日志系统就可以计算请求时间了。
SysDig Monitor 有更加简便的方法。没有必要去做这些复杂的配置,从日志里来计算这些维度,只需要取出 nginx 对于 sockets 文件描述符关于 read() 和 write() 等系统调用的装载量就可以自动完成这些统计。通过这种方式,无需任何代码,SysDig 将提供一些有趣的 HTTP 协议应用层的信息。
- Top URLs: net.request.count|net.http.request.count segmented by net.http.url:Rate of hits per HTTP URL. 在监控用户行为、最受欢迎资源和检查异常连接方面非常有用。
- Slowest URLs: net.http.url segmented by net.http.request.time: 所有连接当中最耗时间的。这些是你需要去利用的关于系统总体反应的潜在瓶颈。
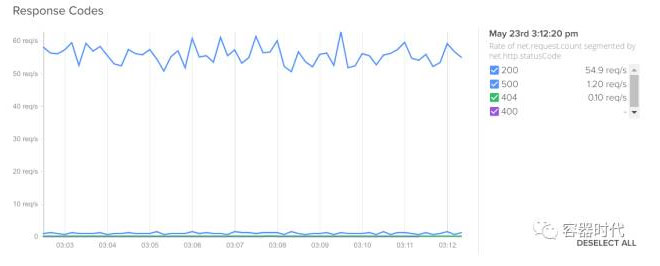
- HTTP 返回码: net.http.statusCode:HTTP 返回码可以提供大量的关于服务健康状况的有用信息,更多见这里。
- 服务请求时间:net.request.time|net.http.request.time两者的平均值。
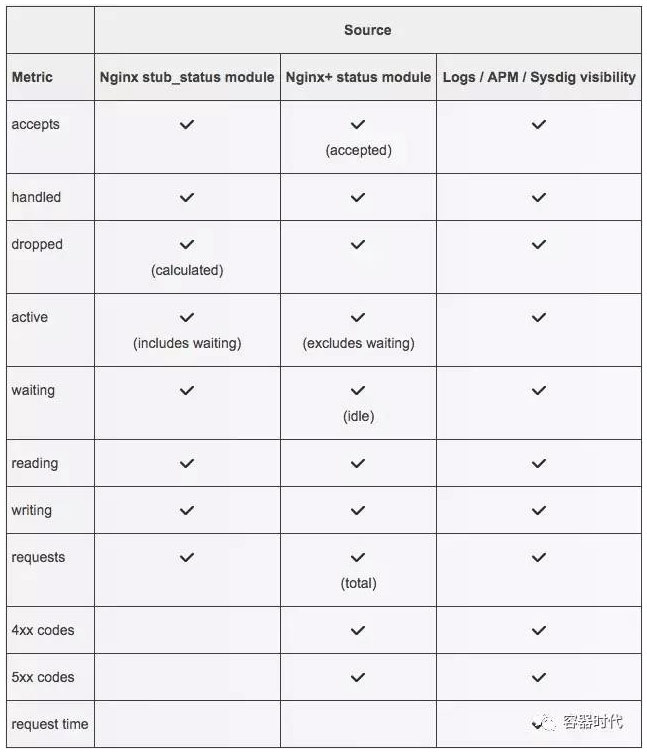
下表介绍了各种维度,以及它们的来源:
C、nginx 的系统和资源维度
这里我们也应该关注一下系统资源的监控情况:
- CPU 使用率 cpu.used.percent
- 平均负载,load.average.percpu.1m, 5m, 15m
- 内存使用,包括固定时间段(absolute terms) memory.bytes.used(虽然名字为bytes,但是显示出来的是更容易读的Mega or Giga)和百分比 memory.used.percent
- 总 IOPS ,file.iops.total 比如,你正在使用本地内容缓存(a local content cache)
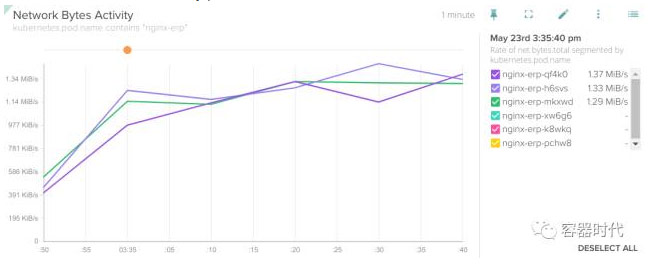
- 网络状况 net.bytes.total, net.bytes.in, net.bytes.out,通过这些你可以知道是否达到了网络峰值,是否该升级网络了
- 网络错误计数 net.error.count 链接问题,注意其中的 HTTP-level error codes(Net error count net.error.count connectivity problems, not to be confused with the HTTP-level error codes.)
现在我们已经讨论了最重要的维度,下面我们来看看如何将它们可视化以及我们能用他们来干什么。
5、Nginx Dashboards
你可以在 Dashboard tab 中创建 Nginx Dashboard,点击 ADD DASHBOARD 然后找到 nginx 模板。通过 scope 可以选择 kubernetes 的资源维度比如 node, namespace, Service, Deployment, 甚至想 AWS 区域 这样的也是可能的。

一旦创建了 Dashboard 就可以自定义它了:添加/删除图表、改变 scope 或者 segmentation of each graph,查看图表事件,改变大小等等。
默认的 Dashboard 包括:连接状态(读、写、等待)、CPU 负载、网络状况、每秒请求、Top URLs、Slowest URLs、激活的连接、丢弃的连接和响应码。
HTTP 控制台模板(HTTP dashboard template) 包含一些应用层的维度(metrics),比如:平均请求时间、最大请求时间和请求类型(GET,POST等),你可以用Copy Panel按钮将多个你感兴趣的维度合并成一个,也可以将他们的组合放到另一个控制台中去。
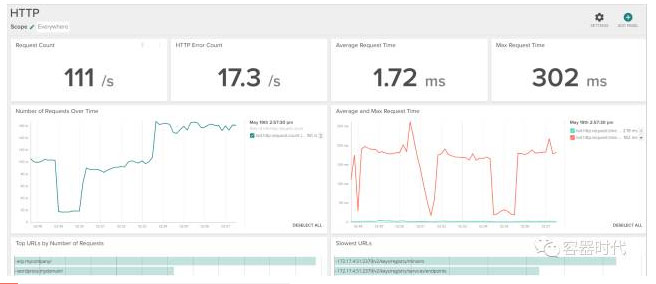
A、使用 Kubernetes 标签监控 Nginx
在像 kubernetes 这样的微服务架构的平台中,你可能除了监控应用层的 nginx 维度外,也想知道单个的容器或者 pod 的情况。这时就可以使用 kubernetes 里 metadata 中的 labels 属性了,但是使用 SysDig 的话,你就可以使用任何可用的 metadata 了,不管是来自 kubernetes 还是 docker 或者是 AWS 这样的云服务提供商。
B、通过 Kubernetes 命名空间进行隔离
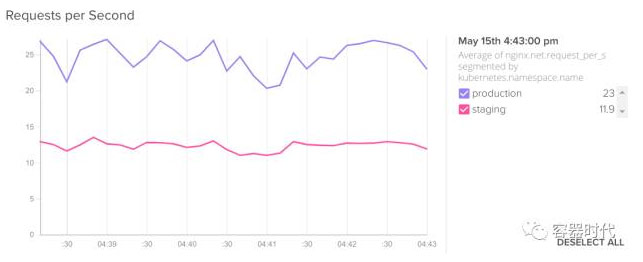
假设你有 development , staging 和 production 3 个完全隔离的命名空间环境。而你现在可能想知道每秒钟每个环境都有多少请求,这时我们就可以用 kubernetes.namespace.name:

一种更普遍的情况是,在你的 CI/CD Pipeline中,你需要实时的知道生产环境和Stage环境的对比情况。我们再来对比一下生产环境和Stage环境的每秒处理请求情况:
再来看看 HTTP 错误响应:
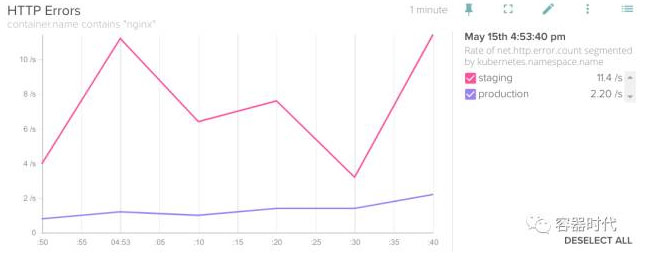
根据这张图,好像 stage 环境还是有一些问题,不能推到 production 环境中。
C、Kubernetes 服务维度的分割
在微服务架构中,我们最想知道的就是每个子服务的情况。通常我们都想找出来哪个子服务最慢,也就是说到底谁是整个应用的瓶颈所在。
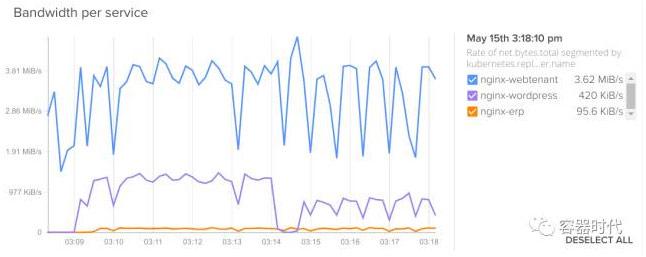
在这个例子中,我们每个服务都对应一个 ReplicationController,这样请求就可以被有效的分割开。一般情况下,你可以使用 kubernetes.replicationController.name 或kubernetes.service.name 来分割时序图表中的任何维度。
比如你想要知道哪一个服务需要更大的带宽:
或者每秒接收到更多的请求:
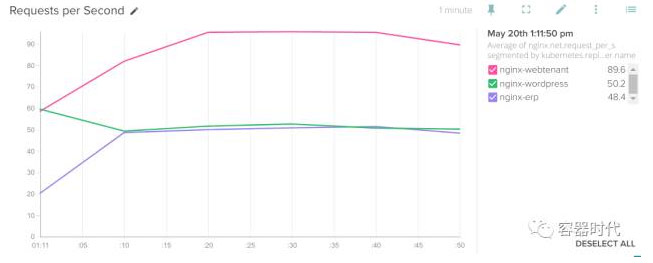
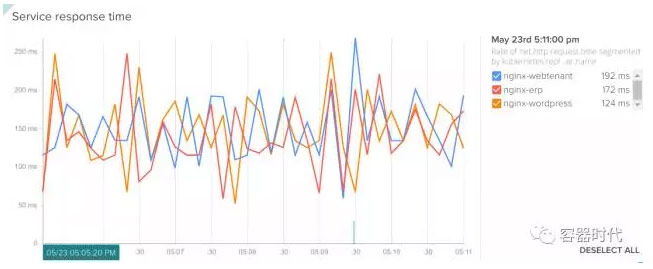
另一种常见情况是你想要知道哪一个服务在处理用户请求上花费了更多的时间。SysDig 可以不添加任何额外的代码而且不需要伴随监控容器(sidecar monitoring container)等复杂配置的情况下给出每一个微服务的响应时间。这可能是在微服务架构里,一旦出问题最有效最直接的解决问题的切入点了。
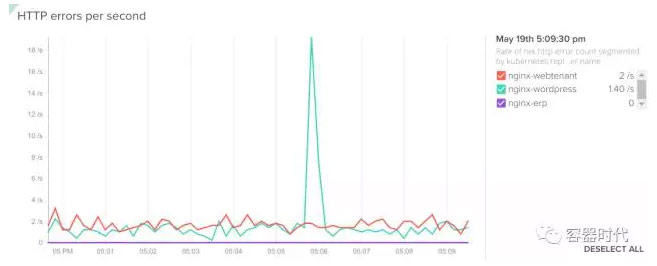
可能你在某一个确定的时间段内发现应用出现了一些问题,而想要找到每个服务在这个时间段内的 HTTP error 统计。
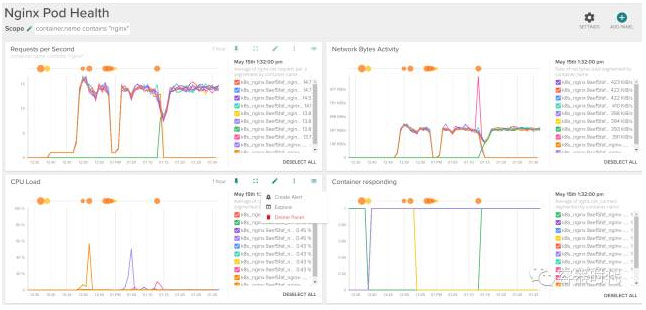
D、按 Pod 维度统计
想要一个以每个容器的折线图统计?只需要按 pod.name 分组即可:
特别有趣的是,当你寻找某个容器的表现与同一个服务中的其他容器表现不一致时,也可以轻松的创建出来:
E、以 HTTP 响应码和 HTTP 方法分组
我们之前已经阐述过了 nginx 监控维度,连带着也说了像 response time, HTTP URL, response code or HTTP method 这样的应用维度。
监控 HTTP 方法(POST, GET, PUT, PATCH, DELETE…)可以审计客户端是如何访问你的 REST APIs 的。
HTTP 响应码在你应用的 API 层面上可以提供大量的有用信息。你不能仅仅只关注 404 和 500 这样的错误,更要关注一些像 disallowed methods, bad gateway 和 gateway timeouts 这样的错误:
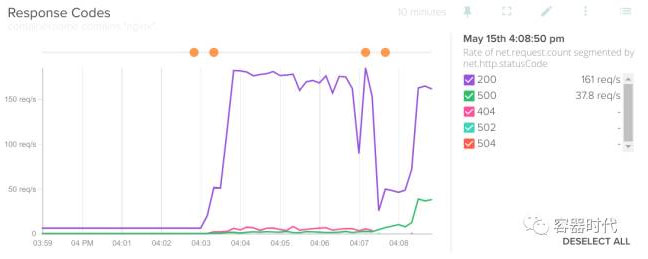
也许你已经猜到了,当监控到太多的 4xx 或者 5xx 这样的错误时,就改告警了。
6、总结
Nginx 在云计算中举足轻重。他的灵活性和简洁性意味着它既可以做一些简单的部署任务,在复杂的情况下也能有出色的表现。他占用资源如此之少,你甚至在做多节点高可用性的时候都不需要犹豫。
Nginx 服务器通常在你的云服务基础设施中占有特权位置,用来分析服务响应、监控瓶颈和后台失败告警,不要错过充分利用这些监控信息的机会。SysDig 既能监控 Nginx 的应用层,比如:service response time, HTTP methods, response code and top 和 slowest URls,也可以在不用其他额外的编码的情况下监控微服务架构。
持续关注本系列的第二篇文章,我们将介绍 nginx 的一般失败告警配置和本章所提到的一些使用示例。
本文转自中文社区-在Kubernetes中监控Nginx
