再前段echosong 写了一遍关于mysql 数据同步实现业务读写分离的文章,今天咱们来看下SQL Server的复制订阅实现数据的读写分离
比起mysql的复制,SQL server 复制相对强大
一、 名词解释
1、复制的 机构组成(类比报纸流通):
1)、发布服务器(报社出版)
生产维护数据源,审阅所有出版数据的更改 发送给 分发服务器(邮局)
2)、分发服务器 (邮局)
分发服务器包括分发数据库,并且存储元数据、历史数据和事务。
3)、订阅服务器(订报人,读者)
保持数据的副本,并接收对所修改出版的更改。取决于所实现的复制选项,可能还允许更新者更新数据,并将其复制回服务器或者其它订阅者。
2、复制类型
1)快照复制
快照复制是完全按照数据和数据库对象出现时的状态来复制和分发它们的过程。快照复制不需要连续地监控数据变化,因为已发布数据的变化不被增量地传播到订阅服务器,而是周期性的被一次复制。 适用于 数据主要是静态的,比如将数据仓库复制到数据集市中一段时间内允许有已过时的数据拷贝的情况
2)事务复制
使用事务复制,初始快照数据将被传播到订阅服务器,因此该订阅服务器就具有了一个所谓的初始负载,这是可以开始工作的内容。当出版服务器上发生数据修改时,这些单独的事务会被及时捕获并复制到订阅服务器。并保留事务边界,当所有的改变都被传播后,所有订阅服务器将具有与传播服务器相同的值 需要数据修改经常在其发生的几秒钟内被传播到订阅服务器需要事务是原子性的 订阅服务器在通常是连接到出版服务器上的 应用程序不能忍受订阅服务器接收改变的高延迟
3)合并复制
合并复制允许一组站点自治工作,在线或离线。然后在将来的某个时刻,数据按照在多个已复制站点上发生的修改或插入情况被合并成一个统一的结果。在订阅服务器上应用初始快照,作为其初始负载,然后SQL Server跟踪在出版服务器上和订阅服务器上已发布数据的更改。数据按照预先定义或调度的时间,或者按需在服务器间同步。然后更新被独立应用在多个服务器上。这意味着相同的数据可能由出版服务器或多个订阅服务器进行了更新,因而当数据更新合并时将发生冲突。 多个订阅服务器需要在不同时刻更新数据,并将这些数据传播到出版服务器和其他订阅服务器。 订阅服务器需要接收数据,脱机更改数据,然后将更改同步到出版服务器和其他订阅服务器 应用程序的延迟需求可高可低 站点的自治性很关键
3、复制模式
1)、推模式(Push)
分发代理程序在分发服务器上运行,即为推模式
2)、拉模式(Pull)
分发代理在订阅服务器运行,即为拉模式
二、工作流程
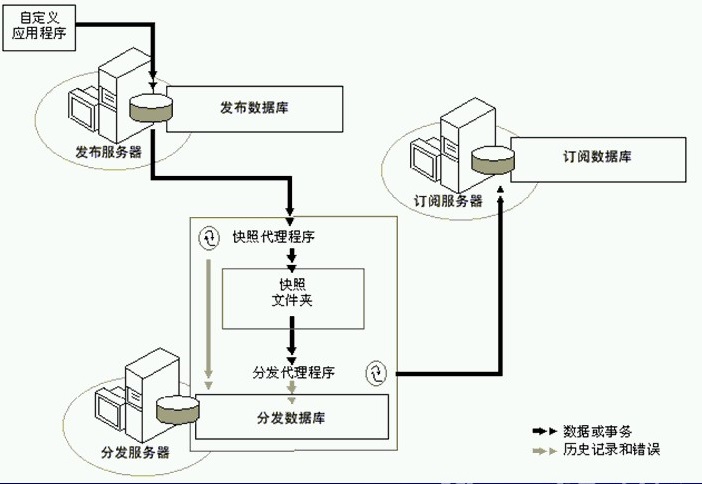
1、快照复制
1)、发布服务器,将要发布的数据库整个做一个快照,
2)、订阅服务器的快照代理程序把发布服务器的快照读取过来,放在本地的快照文件夹内
3)、订阅服务器的发布代理程序把快照文件夹中的快照发布到订阅服务器上。历史记录和快照记录在分发服务器中。
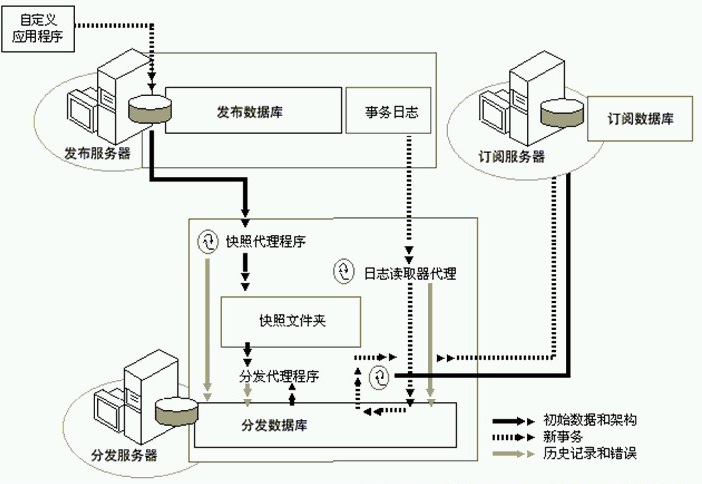
2、事务复制
1)、初始数据和架构(通过快照复制来完成),从这里可以体现出来快照复制,是所有复制的基础 。快照复制在订阅服务器上建立了订阅数据库。
2)、发布服务器的数据修改后,写事务日志,
3)、分发服务器的日志读取代理读取发生改变的数据的事务日志,把这些事务日志保存在发布服务器的发布数据库中。
4)、分发服务器的分发代理程序 将分发数据库中的事务日志分发到各个订阅服务器上,然后把历史记录和错误记录在分发数据库中
三、具体操作流程
1、发布复制(推送模式)
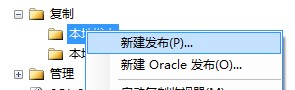
1)、展开SQL Server 2008 服务器下的 【复制】 节点,会发现有【本地发布】和【本地订阅】两个节点,右击【本地发布】节点,选择【新建发布】
2)、设置分发服务器和发布服务器为同一台(推送模式)

3)、选择数据元位置
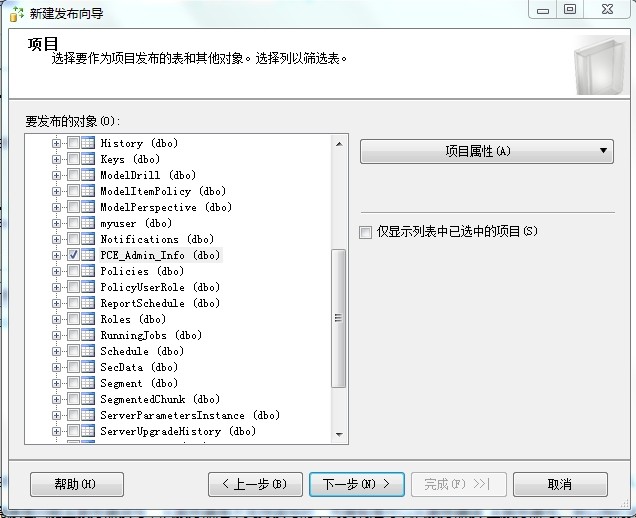
4、选择同步的数据库对象
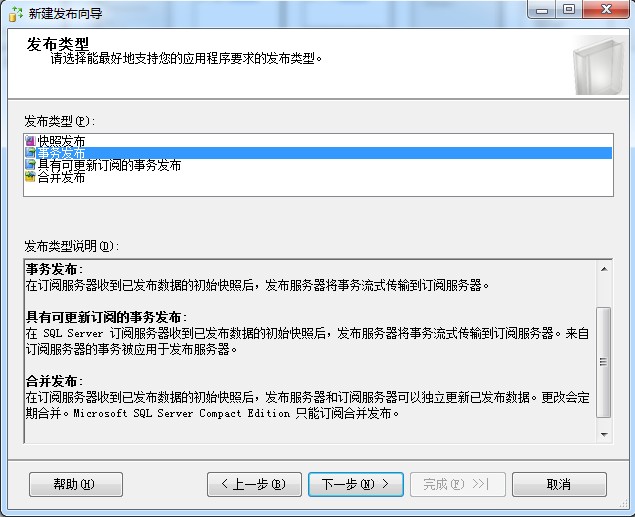
5、发布复制类型
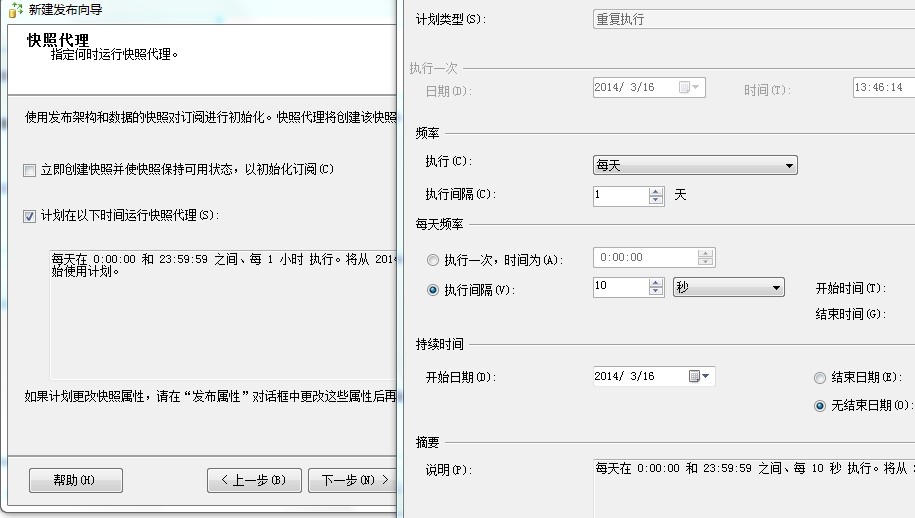
6、设置同步计划
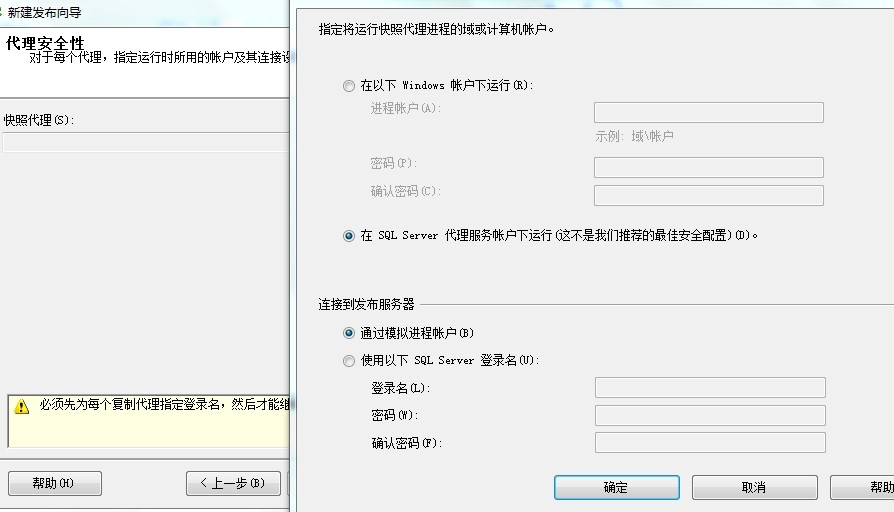
7、设置代理安全性
8、发布完成取名字
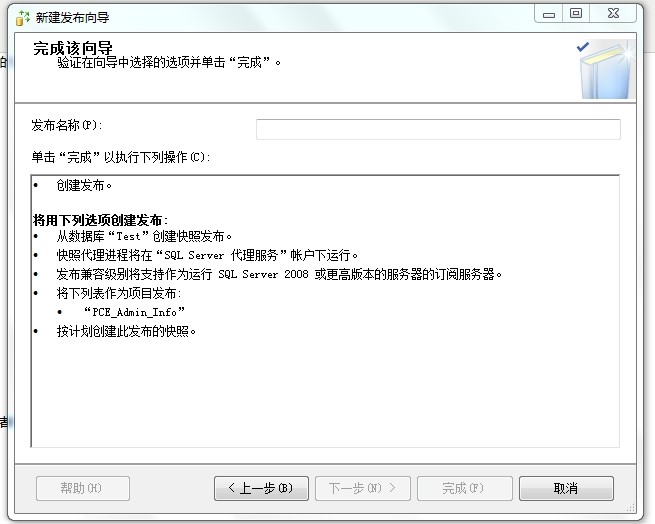
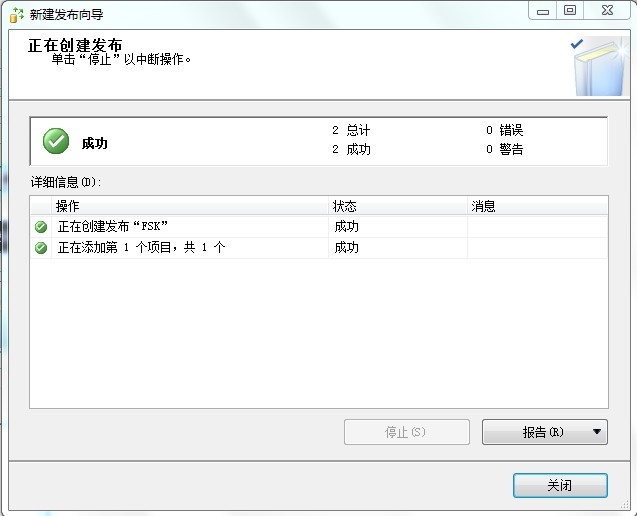
2、订阅复制
1)、右键点击【本地订阅】节点,打开,【新建订阅向导】对话框
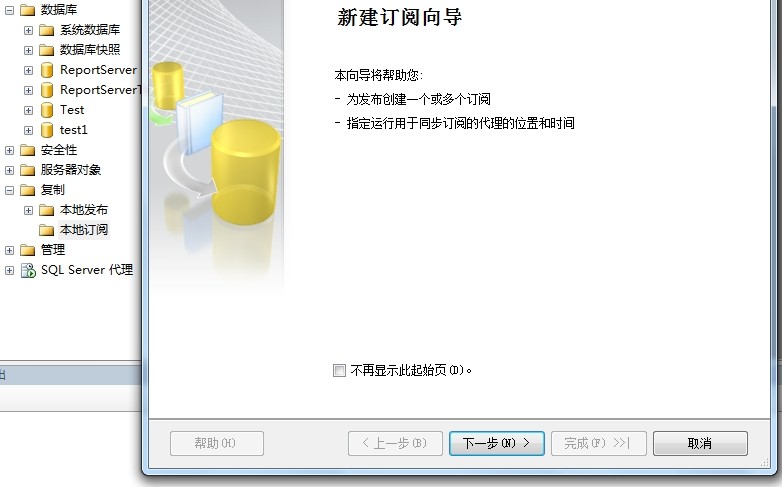
2)搜索发布服务器去订阅
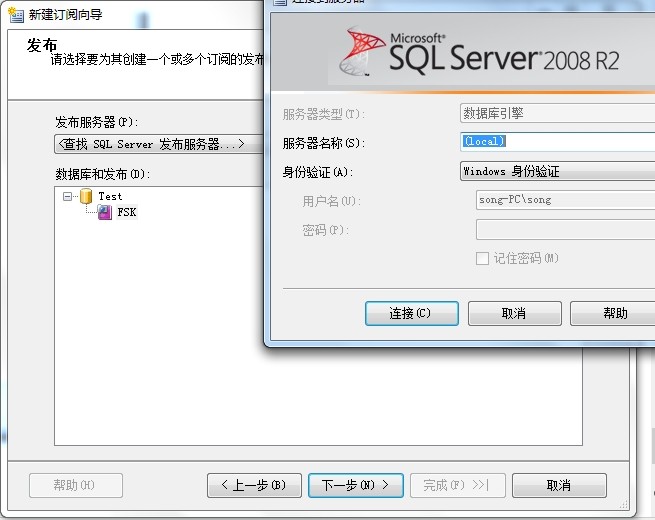
3)、由于上面发布的和分发的是同一台服务器所以选择推送订阅
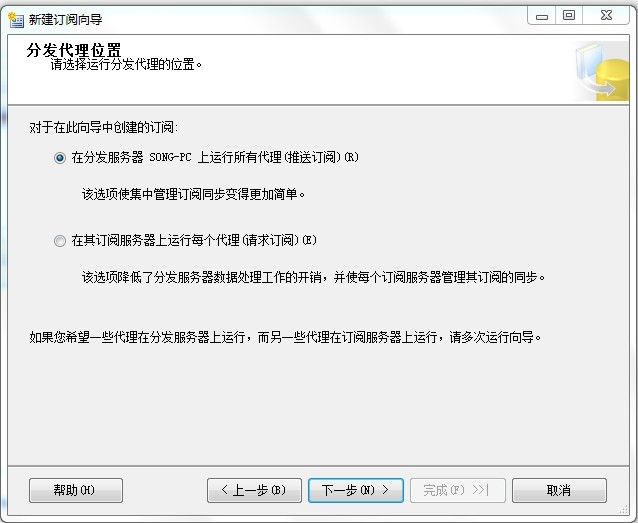
4)、选择订阅接受的对象(也就是获取数据的数据库,上面发布了 test 库 pce_admin_info,这里用本机的test1来接受,同步时如果没有表会自动在test1库创建表)

5)、设置连接安全性
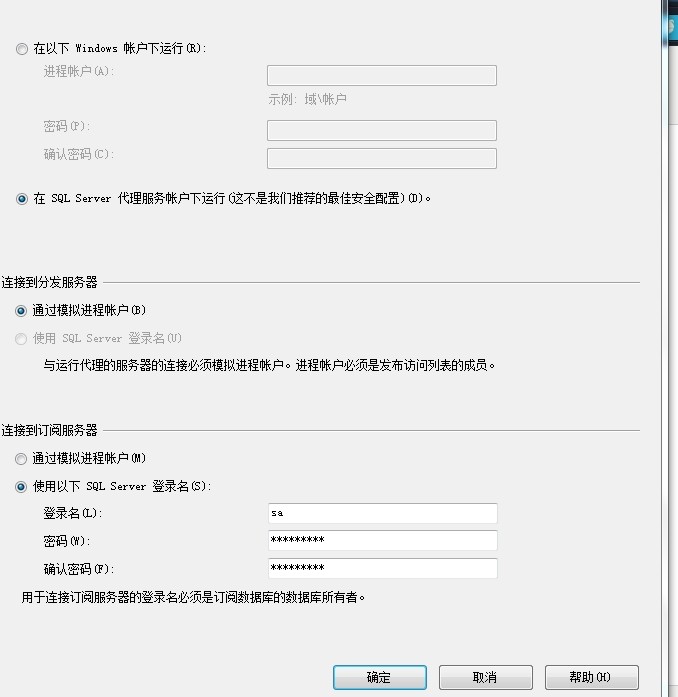
6)后面一直默认点下一步,完成订阅
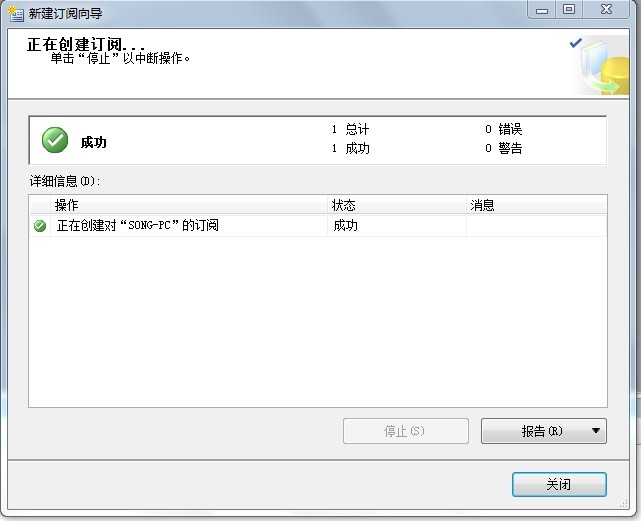
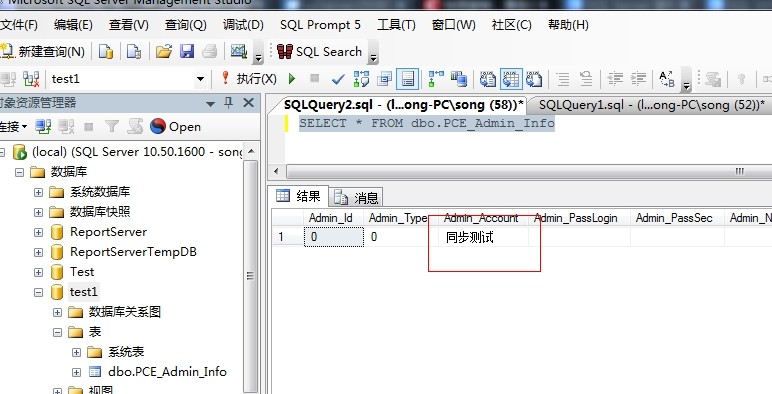
3、查看效果
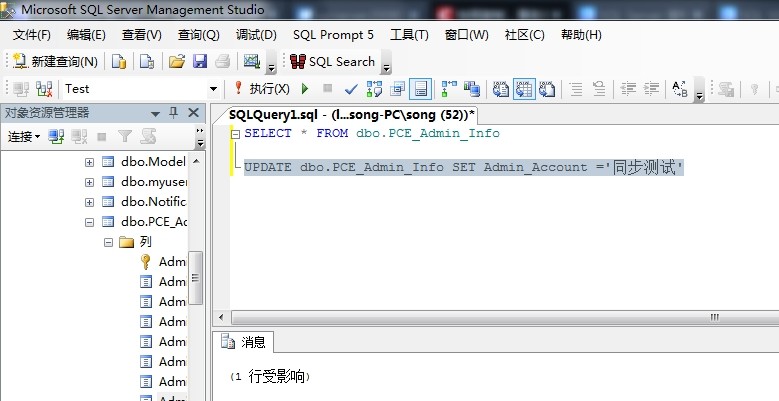
同步上面步骤,把 A服务器的 test 库 的 pce_admin_info 表同步到 B服务器的 test1 ,在第一次执行订阅后自动创建了表,之后会根据计划设置同步的更新表pce_admin_info

四、注意事项
1、无论是发布复制还是订阅服务 一定要在sql server安装的服务器本机操作,不能是远程连接操作
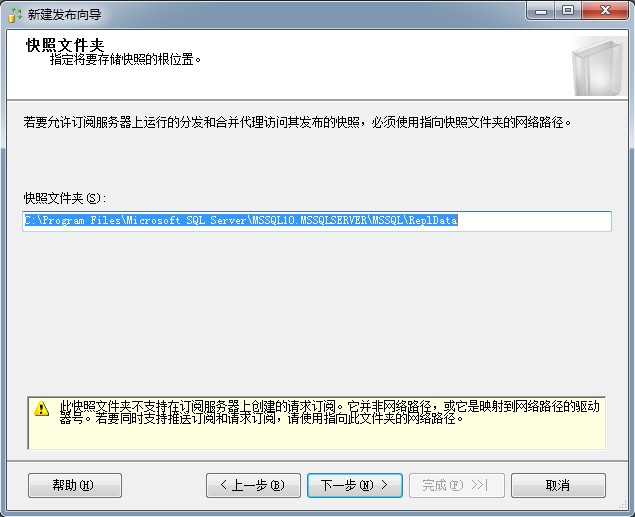
2、将这个文件夹共享出来,然户用共享文件夹的UNC路径作为快照文件夹路径。这个文件夹要赋予SQL Server Service和Agent Service读写权限。
3、sql server 另外一种镜像实现数据副本,镜像是只能主服务器读写,从服务器是不支持读写的,而复制是可以从服务器读 主服务器写。所以我们实现读写分离往往是通过数据库的复制来实现。
4、UNC 可以做的网络驱动映射或者FTP连接
5、再发布服务器设置订阅的时候 系统会提示使用计算机名,而在不同的网络内计算机名不可以直接访问,这个时候需要设置别名,别名要注意64 client 和32client都要加
五、补充
同步复制的时候订阅服务器会生成相应的表的删除,修改,添加的存储过来来执行数据
 -->
-->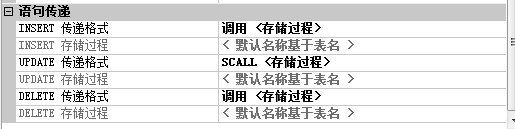
左边的存储过程由右边的调用存储过程控制,选项可以选择其他的就不会生成存储过程
当我们业务需要 需要对存储过程进行修改,我们修改存储过程后,如果改变了源数据的结构,这个时候存储过程又会初始化,如果我们想让存储过程保持不变可以做以下修改
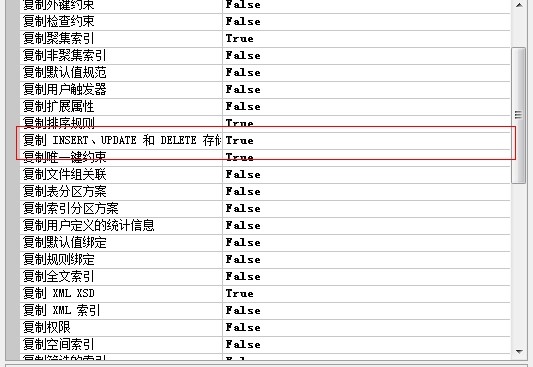
上面右图的true 改为false 就 ok

