本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
阶隐式矩阵分解
前不久我发布了一个Python版本的隐式交替最小二乘矩阵分解算法(代码),虽然其速度不慢;但是本着精益求精的精神,本文将围绕Conjugate Gradient(共轭梯度)方法来探讨更快的算法。
在隐式反馈数据集协作过滤(Collaborative Filtering for Implicit Feedback Datasets)中描述的算法由于极强的扩展性,因此十分流行。不但Spark mllib中的隐式推荐模块使用此算法,甚至Facebook在他们的职位推荐项目中使用该算法进行超过10亿人的职位推荐。
在我上一篇关于矩阵分解的文章(链接)中,我试图说明这个算法如何推广一个来自last.fm的音乐剧的数据集。最酷的结果是,这个算法得知,标签为“Arcade Fire”和“Arcade Fire”的乐队事实上非常相似(因为它只是不同的同一乐队的拼写) - 即使数据集中没有用户同时听到两者的结果:
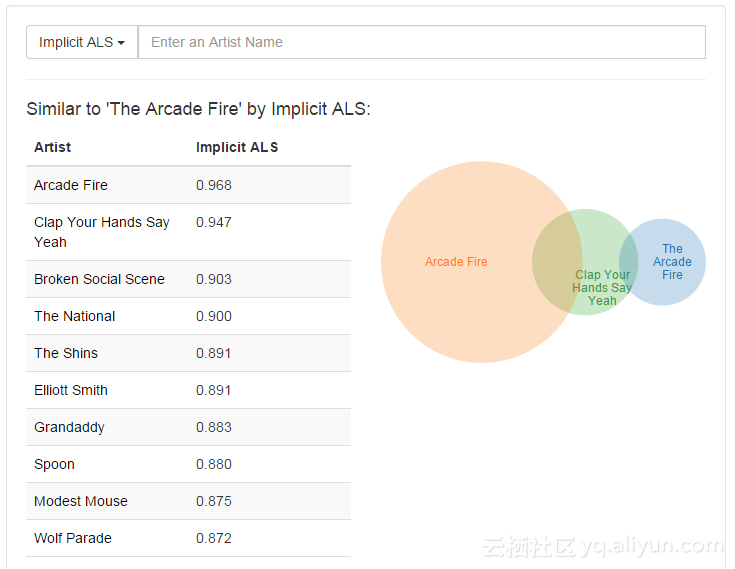
该算法通过求解项目因子Y直接计算用户因子Xu:
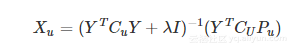
其中Cu是用户喜好置信度的向量,Pu是用户是否倾听了艺术家的二元偏好。项目因子以相同的方式构造,并且算法在计算项目因子和用户因子之间迭代,直到其收敛。
其中,处理YTCuY+λI项是造成运算慢的原因。当用N个因子计算时 - 构建该矩阵相对于非零项的复杂度是O(N2),解这个方程也是O(N3),并且必须每个用户都要进行相同的处理。矩阵的稀疏性或因子的数量决定了运算时间的长短。
使用Conjugate Gradient(共轭梯度)方法加快速度
隐式反馈共轭梯度法应用协作过滤论文(链接)显示了如何通过将每个非零项的复杂度减少为O(N)并将每个用户的复杂度减少为O(N2)来实现数量级的速度跃升。
共轭梯度法是以迭代方法来求解线性方程组。由于我们已有一个性能很好的二次损失函数,而梯度是一个线性函数 - 当梯度为零时我们只需要解决这个函数就能达到最小化目的。这里我会结合非线性共轭梯度方法示例(链接)来说明线性共轭梯度是如何工作的。下面的红色路径是所采用的搜索方向,黄色箭头是每次迭代的梯度:
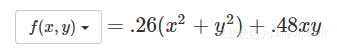
共轭梯度法可以在任何二次迭代中最小化任何二维二次函数 – 不论起始点在哪(点击选择一个新点)。与非线性共轭梯度方法不同,它也不必为了找到适当的步长而进行线路搜索,因为可以直接计算确切的最佳步长。
在将共轭梯度法应用于矩阵分解问题中,思想是避免恰好在每次迭代上求解Xu=(YTCuY+λI)-1YtCuPu。该计算十分耗时,并会在下一个交替的最小二乘迭代中被覆盖。我们这里会尝试根据前述的共轭梯度步骤来寻求解决方法。
这里很酷的是,我们甚至不需要在这种情况下建立YTCuY+λI矩阵,更不用说解决它了。所有需要的是将该矩阵乘以当前搜索方向 -这里不使用原始论文中的技巧实现每个用户矩阵处理,公式为:YTCuY = YTY + YT(CU-I)Y以及预计算所有用户的YTY矩阵。
在Python中对这个算法的完整实现是:
def alternating_least_squares_cg(Cui, factors, regularization=0.01, iterations=15):
users, items = Cui.shape
# 初始化随机因子
X = np.random.rand(users, factors) * 0.01
Y = np.random.rand(items, factors) * 0.01
Cui, Ciu = Cui.tocsr(), Cui.T.tocsr()
for iteration in range(iterations):
least_squares_cg(Cui, X, Y, regularization)
least_squares_cg(Ciu, Y, X, regularization)
return X, Y
def least_squares_cg(Cui, X, Y, regularization, cg_steps=3):
users, factors = X.shape
YtY = Y.T.dot(Y) + regularization * np.eye(factors)
for u in range(users):
# 从前次迭代开始
x = X[u]
# 计算 r = YtCuPu - (YtCuY.dot(Xu), 不用计算YtCuY
r = -YtY.dot(x)
for i, confidence in nonzeros(Cui, u):
r += (confidence - (confidence - 1) * Y[i].dot(x)) * Y[i]
p = r.copy()
rsold = r.dot(r)
for it in range(cg_steps):
# 计算Ap = YtCuYp 而不是 YtCuY
Ap = YtY.dot(p)
for i, confidence in nonzeros(Cui, u):
Ap += (confidence - 1) * Y[i].dot(p) * Y[i]
# 标准CG更新
alpha = rsold / p.dot(Ap)
x += alpha * p
r -= alpha * Ap
rsnew = r.dot(r)
p = r + (rsnew / rsold) * p
rsold = rsnew
X[u] = x
为了使该算法执行更快,我还添加了一个使用OpenMP并行计算的Cython实现(链接),并使用直接BLAS调用,以下的基线数据都是基于该组合的。
测量代码的速度和精度
共轭梯度方法的速度确令人感到兴奋。为了测试准确性,我只是计算每次迭代的训练损失,并与我使用Cholesky求解器在每次迭代得到确切解决方案的原始实现进行比较。因为我们只是在同一损失函数上比较优化方法,训练损失足以证明每个方法实际上是收敛的。在具有100个因子的last.fm数据集上运行此操作的结果是:
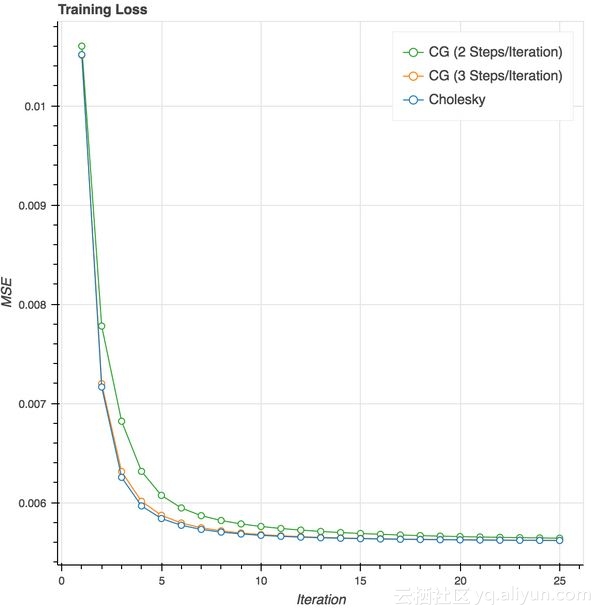
论文中建议在每次迭代使用2个共轭梯度步长,但我发现使用3时与论文的结果更接近。事实上,在10次迭代之后,损失基本上与Cholesky求解器相同。
在我的笔记本电脑上,每次迭代时间的基准测试显示,随着因子数量的增长,速度有了大幅提升:
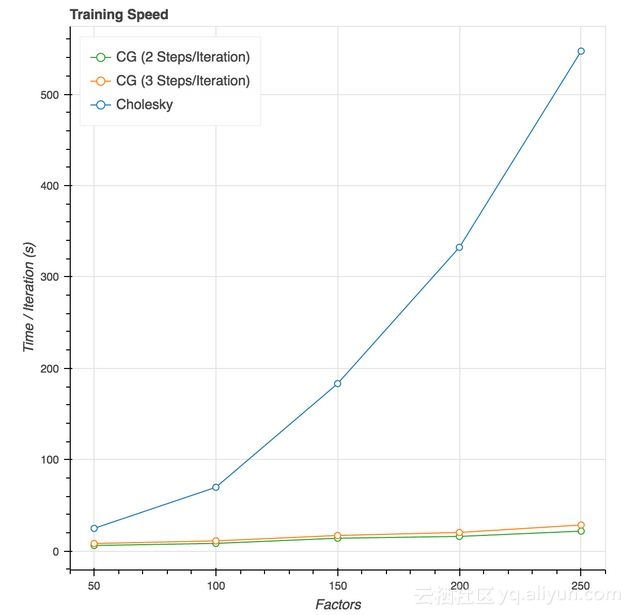
每次迭代使用3个共轭梯度步长,这个代码的速度是50因子数时的3倍,是250因子时速度的19倍。事半功多倍的结果令人兴奋不已。
我已更新该方法到我的隐式建议库中(链接),以及测试脚本基准(链接)。在我的javascript数值优化库中也添加了线性共轭梯度示例(链接)。
文章原标题《Faster Implicit Matrix Factorization》,作者:Ben Frederickson,译者:伍昆
文章为简译,更为详细的内容,请查看原文
