一、Gecco是什么
Gecco是一款用java语言开发的轻量化的易用的网络爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫,Gecco是面向主题的爬虫。
- 通用爬虫一般关注三个主要的问题:下载、排序、索引。
- 主题爬虫一般关注的是:下载、内容抽取、灵活的业务逻辑处理。
Gecco的目标是提供一个完善的主题爬虫框架,简化下载和内容抽取的开发,利用管道过滤器模式,提供灵活的内容清洗和持久化处理模式,让开发人员把更多的精力投入到与业务主题相关的内容处理上。
主要特征
- 简单易用,使用jquery的selector风格抽取元素
- 支持页面中的异步ajax请求
- 支持页面中的javascript变量抽取
- 利用Redis实现分布式抓取,参考gecco-redis
- 支持下载时UserAgent随机选取
- 支持下载代理服务器随机选取
- 支持结合Spring开发业务逻辑,参考gecco-spring
- 支持htmlunit扩展,参考gecco-htmlunit
- 支持插件扩展机制
二、一分钟你就可以写一个简单爬虫
示例代码
这里用抓取gecco这个项目的首页为例。我们希望得到项目的作者名称,项目名称,项目的star和fork数量,以及项目的介绍。如果你稍有java基础,会写jquery的css selector我相信下面的代码我不需要解释你也能轻松的看明白。
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -7127412585200687225L;
@RequestParameter("user")
private String user;
@RequestParameter("project")
private String project;
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;
@Html
@HtmlField(cssPath=".entry-content")
private String readme;
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//Gecco搜索的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("https://github.com/xtuhcy/gecco")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
.start();
}
}
代码说明
- 接口HtmlBean说明该爬虫是一个解析html页面的爬虫(gecco还支持json格式的解析)
- 注解@Gecco告知该爬虫匹配的url格式(matchUrl)和内容抽取后的bean处理类(pipelines处理类采用管道过滤器模式,可以定义多个处理类)。
- 注解@RequestParameter可以注入url中的请求参数,如@RequestParameter("user")表示匹配url中的{user}
- 注解@HtmlField表示抽取html中的元素,cssPath采用类似jquery的css selector选取元素
- 注解@Text表示获取@HtmlField抽取出来的元素的text内容
- 注解@Html表示获取@HtmlField抽取出来的元素的html内容(如果不指定默认为@Html)
- GeccoEngine表示爬虫引擎,通过create()初始化,通过start()/run()运行。可以配置一些启动参数如:扫描@Gecco注解的包名classpath;开始抓取的url地址star;抓取线程数thread;抓取完一个页面后的间隔时间interval(ms)等
三、软件总体结构
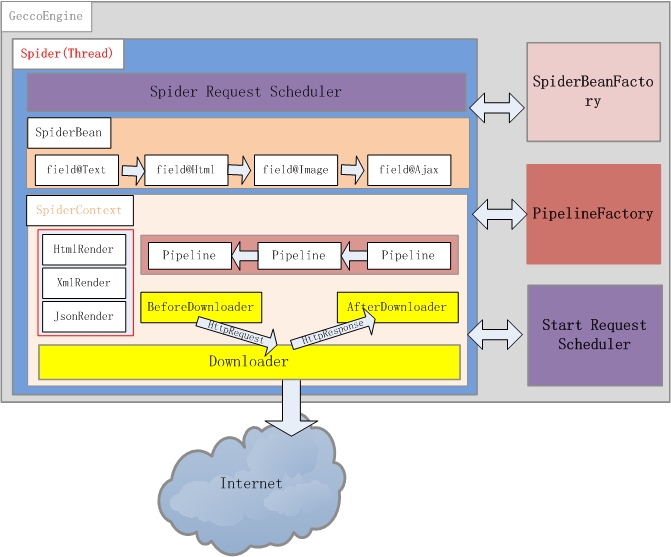
基本构件介绍
GeccoEngine
GeccoEngine是爬虫引擎,每个爬虫引擎最好是一个独立进程,在分布式爬虫场景下,建议每台爬虫服务器(物理机或者虚机)运行一个GeccoEngine。爬虫引擎包括主要Scheduler、Downloader、Spider、SpiderBeanFactory、PipelineFactory5个主要模块。
Scheduler
通常爬虫需要一个有效管理下载地址的角色,Scheduler负责下载地址的管理。gecco对初始地址的管理使用StartScheduler,StartScheduler内部采用一个阻塞的FIFO的队列。初始地址通常会派生出很多其他待抓取的地址,派生出来的其他地址采用SpiderScheduler进行管理,SpiderScheduler内部采用线程安全的非阻塞FIFO队列。这种设计使的gecco对初始地址采用了深度遍历的策略,即一个线程抓取完一个初始地址后才会去抓取另外一个初始地址;对初始地址派生出来的地址,采用广度优先策略。
Downloader
Downloader负责从Scheduler中获取需要下载的请求,gecco默认采用httpclient4.x作为下载引擎。通过实现Downloader接口可以自定义自己的下载引擎。你也可以对每个请求定义BeforeDownload和AfterDownload,实现不同的请求下载的个性需求。
SpiderBeanFactory
Gecco将下载下来的内容渲染为SpiderBean,所有爬虫渲染的JavaBean都统一继承SpiderBean,SpiderBean又分为HtmlBean和JsonBean分别对应html页面的渲染和json数据的渲染。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext。上下文SpiderBeanContext会告知这个SpiderBean采用什么渲染器,采用那个下载器,渲染完成后采用哪些pipeline处理等相关上下文信息。
PipelineFactory
pipeline是SpiderBean渲染完成的后续业务处理单元,PipelineFactory是pipeline的工厂类,负责pipeline实例化。通过扩展PipelineFactory就可以实现和Spring等业务处理框架的整合。
Spider
Gecco框架最核心的类应该是Spider线程,一个爬虫引擎可以同时运行多个Spider线程。Spider描绘了这个框架运行的基本骨架,先从Scheduler获取请求,再通过SpiderBeanFactory匹配SpiderBeanClass,再通过SpiderBeanClass找到SpiderBean的上下文,下载网页并对SpiderBean做渲染,将渲染后的SpiderBean交个pipeline处理。
四、GeccoEngine
Gecco如何运行
Gecco的初始化和启动通过GeccoEngine完成,GeccoEngine主要负责初始化配置、开始请求的配置和启动爬虫运行,最基本的启动方法:
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("https://github.com/xtuhcy/gecco")
.start();
classpath是必填项,指定扫描@Gecco的包路径。start是初始请求地址。start()表示采用非阻塞方式运行爬虫。
GeccoEngine基本配置项
- loop(true):表示是否循环抓取,默认为false
- thread(2):表示开启的爬虫线程数量,默认是1,需要注意的是线程数量要小于或者等于start请求的数量
- interval(2000):表示某个线程在抓取完成一个请求后的间隔时间,单位是毫秒,系统会在左右1秒时间内随机。如果为2000,系统会在1000~3000之间随机选取。
- mobile(false):表示使用移动端还是pc端的UserAgent。默认为false使用pc端的UserAgent。
- debug(true):是否开启debug模式,如果开启debug模式,会在控制台输出jsoup元素抽取的日志。
- pipelineFactory(PipelineFactory):自定义Pipeline工厂类
- scheduler(Scheduler):自定义请求队列管理器
非阻塞启动和阻塞启动
- start():非阻塞启动,GeccoEngine会单独启动线程运行,推荐以该方式运行。线程模型如下:
Main Thread-->GeccoEngine Thread-->Spider Thread
- run():阻塞启动,GeccoEngine在主线程中启动运行,非循环模式GeccoEngine需要等待其他爬虫线程运行完毕后才会退出。线程模型r如下:
Main Thread-->Spider Thread
Gecco如何匹配URL
- 匹配URL的作用
匹配URL是告知Gecco,这种格式的url对应的网页会被渲染成当前的SpiderBean。
- matchUrl如何写
完全匹配:@Gecco(matchUrl="https://github.com/"),完全匹配https://github.com/这个url
模糊匹配:@Gecco(matchUrl="https://github.com/{user}/{project}"),会匹配所有类似格式的url,https://github.com/xtuhcy/gecco、https://github.com/xtuhcy/gecco-spring。模糊匹配的{}可以匹配任意非空白字符串但是不包含斜杠(/
任意匹配:@Gecco,如果你不写matchUrl,任何格式的url都会被匹配,这种方式一般用作通用爬虫,例如:
@Gecco(pipelines="consolePipeline")
public class CommonCrawler implements HtmlBean {
private static final long serialVersionUID = -8870768223740844229L;
@Request
private HttpRequest request;
@HtmlField(cssPath="body")
private String body;
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public static void main(String[] args) {
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("https://www.baidu.com/")
.interval(2000)
.start();
}
}
五、从下载说起
一、下载引擎
爬虫最基本的能力就是发起http请求,下载网页,gecco默认采用httpclient4作为下载引擎。通过实现Downloader接口可以自定义自己的下载引擎,在启动GeccoEngine时需要设置自己的下载引擎。下面的代码不是使用默认的httpclient作为下载引擎,而是使用htmlUnit作为下载引擎。
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline", downloader="htmlUnitDownloder")
二、HttpRequest和HttpResponse
HttpRequest表示下载请求,HttpResponse表示下载响应。爬虫下载网页都会模拟浏览器包装成GET或者POST请求,HttpGetRequest和HttpPostRequest分别对应GET和POST请求。
- gecco的请求支持模拟userAgent,并且支持userAgent的随机轮询,在calsspath的根目录下定义userAgents文件,每行表示一个UserAgent; - gecco支持cookie定义,request.addCookie(),可以模拟用户登录; - gecco支持代理服务器的随机轮询,在classpath的根目录下定义proxys文件,每行表示一个代理服务器的主机和端口,如127.0.0.1:8888;
三、下载地址管理
通常爬虫需要一个有效管理下载地址的角色,Scheduler负责下载地址的管理。gecco对初始地址的管理使用StartScheduler,StartScheduler内部采用一个阻塞的FIFO的队列。初始地址通常会派生出很多其他待抓取的地址,派生出来的其他地址采用SpiderScheduler进行管理,SpiderScheduler内部采用线程安全的非阻塞FIFO队列。这种设计使的gecco对初始地址采用了深度遍历的策略,即一个线程抓取完一个初始地址后才会去抓取另外一个初始地址;对初始地址派生出来的地址,采用广度优先策略,派生地址的获取会在下面详细说明。另外,gecco的分布式抓取也是通过Scheduler来完成了,准确的说是通过实现不同的StartScheduler来将初始地址分配到不同的服务器中来完成的。gecco的分布式抓取默认采用redis来实现,具体可以参考gecco-redis项目。
GeccoEngine.create().scheduler(new RedisStartScheduler("127.0.0.1:6379"))
四、初始地址和派生地址
爬虫通常会从若干个初始地址开始爬取网页,爬取下来的网页可能包含其他需要继续抓取的页面,典型的例子是列表页和详情页。列表页作为初始地址,抓取完成后需要针对每个列表项再抓取对应的详情页。gecco派生地址的方式有两种:一种是通过注解@Href(click=true),click为true时,抽取出来的url会继续抓取,如:
@Href(click=true)
@HtmlField(cssPath=".tm-qx-nrBox a")
private String detailUrl;
还一种是显式的加入SpiderScheduler的方法,如:
SchedulerContext.into(currRequest.subRequest("subUrl");
使用@Request注解可以获得当前HttpRequest对象,使用当前request的subRequest方法生成派生地址的请求,这样在相应的pipeline类中即可控制派生请求的增加。
五、多个初始地址的配置
通过在classpath的根目录下放置配置文件starts.json可以配置多个初始地址,如下:
[
{
"charset": "GBK",
"url": "http://item.jd.com/1455427.html"
},
{
"url": "https://github.com/xtuhcy/gecco"
}
]
六、BeforeDownload和AfterDownload
一些特殊的场景,可能会需要在下载前做下载的预处理和在下载后做特定的处理,之后再传递给pipeline进行处理,这时需要实现BeforeDownload和AfterDownload。如:
@GeccoClass(CruiseDetail.class)
public class CruiseDetailBeforeDownload implements BeforeDownload {
@Override
public void process(HttpRequest request) {
}
}
上面的类针对CruiseDetail这个bean的下载前会做自定义的处理。
@GeccoClass(CruiseRedirect.class)
public class CruiseRedirectAfterDownload implements AfterDownload {
@Override
public void process(HttpRequest request, HttpResponse response) {
}
}
上面这个类会对CruiseRedirect这个bean做下载后的自定义处理。
七、使用httpUnit作为下载引擎
gecco通过扩展downloader实现了对htmlunit的支持。htmlunit是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现。这个没有界面的浏览器,运行速度也是非常迅速的。htmlunit采用的是rhino作为javascript的解析引擎。
-
下载
<dependency> <groupId>com.geccocrawler</groupId> <artifactId>gecco-htmlunit</artifactId> <version>x.x.x</version> </dependency> 优缺点
使用htmlunit确实能省去很多工作,但是htmlunit也存在很多弊端:
1、效率低下,使用htmlunit后,下载器要将所有js一并下载下来,同时要执行所有js代码,下载一个页面有时需要5~10秒。
2、rhino引擎对js的兼容问题,rhino的兼容性还是存在不少问题的,上述demo就有很多js执行错误。如果大家在抓取时不想看到这些error日志输出可以配置log4j:
log4j.logger.com.gargoylesoftware.htmlunit=OFF
3、使用selenium也可以达到类似目的,selenium本身并不解析js,通过调用不同的浏览器驱动达到模拟浏览器的目的。selenium支持chrome、IE、firefox等多个真实浏览器驱动,也支持htmlunit作为驱动,还支持PhantomJS这种js开发的驱动。
六、抽取页面内容
gecco的内容抽取都是直接映射到java bean的属性中,利用注解可以方便的注入页面中的各种信息包括html页面内容、Ajax请求、javascript变量、request信息等
一、Html页面内容抽取
jsoup语法介绍
Selector选择器概述
tagname: 通过标签查找元素,比如:a
ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找 <fb:name> 元素
#id: 通过ID查找元素,比如:#logo
.class: 通过class名称查找元素,比如:.masthead
[attribute]: 利用属性查找元素,比如:[href]
[^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 Dataset属性的元素
[attr=value]: 利用属性值来查找元素,比如:[width=500]
[attr^=value], [attr$=value], [attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/]
[attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如: img[src~=(?i)\.(png|jpe?g)]
*: 这个符号将匹配所有元素
Selector选择器组合使用
el#id: 元素+ID,比如: div#logo
el.class: 元素+class,比如: div.masthead
el[attr]: 元素+class,比如: a[href]
任意组合,比如:a[href].highlight
ancestor child: 查找某个元素下子元素,比如:可以用.body p 查找在"body"元素下的所有 p元素
parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p 查找 p 元素,也可以用body > * 查找body标签下所有直接子元素
siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + div
siblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ p
el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
伪选择器selectors
:lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3) 表示小于三列的元素
:gt(n):查找哪些元素的同级索引值大于n,比如: div p:gt(2)表示哪些div中有包含2个以上的p元素
:eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素
:has(seletor): 查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素
:not(selector): 查找与选择器不匹配的元素,比如: div:not(.logo) 表示不包含 class=logo 元素的所有 div 列表
:contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如: p:contains(jsoup)
:containsOwn(text): 查找直接包含给定文本的元素
:matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login)
:matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素
注意:上述伪选择器索引是从0开始的,也就是说第一个元素索引值为0,第二个元素index为1等
详细使用方式可以参考jsoup首页手册
@HtmlField
html属性定义,表示该属性是通过html查找解析,在html的渲染器下使用
- cssPath:jquery风格的元素选择器,使用jsoup实现。jsoup在分析html方面提供了极大的便利。计划实现xpath风格的元素选择器。
@Href
表示该字段是一个链接类型的元素,jsoup会默认获取元素的href属性值。属性必须是String类型。
- value:默认获取href属性值,可以多选,按顺序查找
- click:表示是否点击打开,继续让爬虫抓取
@Image
表示该字段是一个图片类型的元素,jsoup会默认获取元素的src属性值。属性必须是String类型。
- value:默认获取src属性值,可以多选,按顺序查找
- download:表示是否需要将图片下载到本地
@Attr
获取html元素的attribute。属性支持java基本类型的自动转换。
- value:表示属性名称
@Text
获取元素的text或者owntext。属性支持java基本类型的自动转换。
- own:是否获取owntext,默认为是
@Html
默认类型,可以不写,获取html元素的整个节点内容。属性必须是String类型。
二、页面中的Ajax请求
现在的页面通常都会有很多ajax请求,很多主题爬虫在针对这种请求一般是使用htmlunit等类似的渲染引擎,将页面所有的信息都渲染完毕后交给爬虫处理,gecco可以通过实现自定义的downloader类来实现类似的方式。不过该方式会对整个页面都进行渲染,效率较低,很多时候你可能只需要某一个ajax请求就可以了。gecco实现了模拟ajax请求的定义,如:
@Ajax(url="http://p.3.cn/prices/mgets?skuIds=J_{code}")
private JDPrice price;
上述代码通过ajax方式获得jd商品的价格,{code}表示request中的属性值,使用[...]可以引用已经解析出来的html页面中的属性值。全部代码可以参考源码中的src/test/java/com/geccocrawler/gecco/demo/ajax
三、json格式内容的抽取
有ajax请求涉及到json格式的内容抽取,gecco除了支持html的内容抽取,同时也支持json内容的抽取
@JSONPath
使用fastjson的jsonpath,jsonpath类似是一种对象查询语言,能方便的查询json中个字段的值,详情请查看fastjson-jsonpath
@JSONPath("$.p[0]")
private float price;
四、页面中的javascript变量抽取
gecco支持抽取页面中的javascript全局变量的内容抽取。
@JSVar
- var:表示变量名
- jsonpath:如果变量是json格式的数据,通过定义jsonpath抽取需要的内容,如果不是json格式的数据可以不填
五、request信息的注入
@Request
将httpRequest信息注入到java bean中。
@RequestParameter
将url中定义的变量注入到java bean中。
六、自定义注解
通过实现CustomFieldRender接口可以实现自定义的注解。
@FieldRenderName("jdPricesFieldRender")
public class JdPricesFieldRender implements CustomFieldRender {
/**
*
* @param request HttpRequest
* @param response HttpResponse
* @param beanMap 将Field放入SpiderBean
* @param bean 已经注入后的SpiderBean
* @param field 需要注入的Field
*/
public void render(HttpRequest request, HttpResponse response, BeanMap beanMap, SpiderBean bean, Field field) {
//获取需要注入的内容
...
...
//进内容注入到对应的field中
beanMap.put(field.getName(), prices);
}
}
在SpiderBean中引入自定义的注解
public class ProductList implements HtmlBean {
...
@FieldRenderName("jdPricesFieldRender")
private List<JDPrice> prices;
...
}
七、业务逻辑处理
至此页面内容已经被gecco转换为一个普通的javabean。剩下的工作就是将javabean进一步清洗然后针对特定的业务逻辑进行持久化等处理。
一、实现pipeline接口
gecco采用管道过滤器模式灵活的实现业务逻辑处理,首先实现一个特定的管道过滤器,如:
@PipelineName("consolePipeline")
public class ConsolePipeline implements Pipeline<SpiderBean> {
@Override
public void process(SpiderBean bean) {
System.out.println(JSON.toJSONString(bean));
}
}
然后将定义的pipeline关联到对应的javabean中,如:
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
二、结合spring开发业务逻辑
现在开发java服务器端应用已经基本离不开spring框架了,gecco实现了和spring框架的结合,请下载gecco-spring。
使用注解方式配置Spring
扫描com.geccocrawler.gecco.spring,自动注入springPipelineFactory和consolePipeline
<context:component-scan base-package="com.geccocrawler.gecco.spring" />
使用非注解方式配置Spring
手动增加bean:springPipelineFactory和consolePipeline
<bean id="springPipelineFactory" class="com.geccocrawler.gecco.spring.SpringPipelineFactory"/>
<bean id="consolePipeline" class="com.geccocrawler.gecco.spring.ConsolePipeline"/>
初始化Gecco
加载完成bean后启动Gecco,可以通过继承SpringGeccoEngine类,初始化你的GeccoEngine,需要特别注意的是GeccoEngine需要用非阻塞模式start()运行:
@Service
public class InitGecco extends SpringGeccoEngine {
@Override
public void init() {
GeccoEngine.create()
.pipelineFactory(springPipelineFactory)
.classpath("com.geccocrawler.gecco.spring")
.start("https://github.com/xtuhcy/gecco")
.interval(3000)
.start();
}
}
开发Pipeline
pipeline的开发和之前一样,唯一不同的是不需要@PipelineName("consolePipeline")定义pipeline的名称,而是使用spring的@Service定义,spring的bean名称即为pipeline的名称。可以参考:
@Service("consolePipeline")
public class ConsolePipeline implements Pipeline<SpiderBean> {
@Override
public void process(SpiderBean bean) {
System.out.println(JSON.toJSONString(bean));
}
}
八、爬虫的监控
爬虫为什么要监控
gecco是一个十分简单易用的java开源爬虫框架,同时也一个款拥有很好扩展性的框架,目前已经有:
结合spring的插件gecco-spring
结合htmlunit的插件gecco-htmlunit
结合reids的插件gecco-reids
在开发爬虫时,由于要对很多网站和链接进行抓取,并对抓取下来的网站进行内容的抽取。大量的链接下载和内容抽取如果没有监控,很难发现问题。特别是对于主题爬虫,需要抽取页面的具体内容,如果网站改版务必要能尽快的发现并修正,gecco爬虫框架在完成了基本的框架和必要的插件的实现后,将重点放在了监控的开发上。
对扩展开放,对修改关闭的开闭原则一致是gecco框架的基本设计原则。gecco爬虫的监控模块同样基于该原则,基于jmx协议,使用aop模式。
监控指标
爬虫基本信息
刷新基本信息:exec/com.geccocrawler.gecco:name=gecco/monitor
-
读取基本信息:read/com.geccocrawler.gecco:name=gecco
{ Interval: 5000,//抓取间隔时间ms StartTime: "2016-03-20 20:34:11",//抓取开始时间 ThreadCount: 1,//爬虫线程数量 StarUrlCount: 8//初始url数量 }
下载监控
获取当前正在抓取的所有域名:exec/com.geccocrawler.gecco:name=downloader/hosts
获取某个域名的下载监控信息:exec/com.geccocrawler.gecco:name=downloader/statistics/xx.xx.com
-
读取下载监控信息:read/com.geccocrawler.gecco:name=downloader
Statistics: "{ "exception":8,//该域名抓取异常的数量,主要是超时等异常 "serverError":0,//该域名返回500,404等错误信息的数量 "success":3263//成功抓取数量 }", Host: "xx.xx.com"//域名
内容抽取监控
刷新内容抽取监控信息:exec/com.geccocrawler.gecco:name=render/refresh
-
获取内容抽取监控信息:read/com.geccocrawler.gecco:name=render
Statistics: "{ "xx.xx.com":0,//域名xx.xx.com的网站内容抽取的异常数量 "yy.yy.com":0//域名yy.yy.com的网站内容抽取的异常数量 }"
jmxutils和jolokia
jmxutils
gecco的监控使用了jmxutils这个开源的mbean注解框架。在以前的开发工作中要么就用原生的动态mbean,要么是使用spring的jmx注解框架。原生的动态mbean写起来太繁琐,spring的jmx注解框架使用起来还是很方便的,但是现在spring感觉有些重。jmxutils这个框架很轻量,使用方法可以参考https://github.com/martint/jmxutils。
jolokia
Jolokia是一个利用JSON通过Http实现JMX远程管理的开源项目。具有快速、简单等特点。除了支持基本的JMX操作之外,它还提供一些独特的特性来增强JMX远程管理如:批量请求,细粒度安全策略等。也就是说jmx的mbean可以通过http来访问不需要在启动java时配置那么多参数。只需要新增一个servlet:
<servlet>
<servlet-name>jolokia-agent</servlet-name>
<servlet-class>org.jolokia.http.AgentServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>jolokia-agent</servlet-name>
<url-pattern>/jmx/*</url-pattern>
</servlet-mapping>
这样应用中的mbean就能轻松控制和访问。jolokia还提供了java客户端和js客户端来访问mbean,具体的使用方法和权限控制可以查看jolokia的官方文档https://jolokia.org/reference/html/index.html
九、稳定性测试
最近对开源的java爬虫Gecco做了一个稳定性测试,测试环境:一台爬虫+web应用服务器,一台mongodb服务器。服务器配置很low,两台都是阿里云最低端的主机,1核+512内存。
单线程测试场景
爬虫采用单线程,测试时间3×24小时,测试期间系统无异常,jvm内存稳定。测试结果:
-
基本信息
Interval: 5000, StartTime: "2016-03-22 14:47:40", ThreadCount: 1, StarUrlCount: 8单线程,共有8个初始抓取链接,每个请求抓取完成后休息5秒。
-
爬虫监控数据
taocan.ctrip.com Statistics: "{"exception":134,"serverError":0,"success":11270}" vacations.ctrip.com Statistics: "{"exception":61,"serverError":0,"success":17548}" huodong.ctrip.com Statistics: "{"exception":42,"serverError":0,"success":11814}" www.tuniu.com Statistics: "{"exception":4,"serverError":0,"success":228}" temai.tuniu.com Statistics: "{"exception":78,"serverError":0,"success":3507}" www.lvmama.com Statistics: "{"exception":0,"serverError":415,"success":41}" http://www.lvmama.com/tuangou/sale-623250 DOWNLOAD ERROR :500 http://www.lvmama.com/tuangou/sale-612687 DOWNLOAD ERROR :400 结果
从监控数据可以看到:
ctrip.com相关的数据抓取成功率较高,为99.99%,出现的失败都是exception,也就是类似超时之类的错误。
tuniu.com相关的数据抓取成功率也较高,为99.97%,出现的失败也是exception。
lvmama.com的成功率就十分低了,而且返回都是serverError也就是服务器500或者400错误,查看发日志发现可能对方服务器对ip做了访问限制,在成功抓取10多条后就一直报400或者500错误。
多线程测试场景
爬虫采用3线程,测试时间2×24小时,测试期间系统无异常,jvm内存稳定。测试结果:
-
基本信息
Interval: 5000, StartTime: "2016-03-26 11:16:57", ThreadCount: 3, StarUrlCount: 8
3线程,共有8个初始抓取链接,每个请求抓取完成后休息5秒。
-
爬虫监控数据
taocan.ctrip.com Statistics: "{"exception":58,"serverError":0,"success":19306}" vacations.ctrip.com Statistics: "{"exception":51,"serverError":0,"success":31402}" huodong.ctrip.com Statistics: "{"exception":62,"serverError":0,"success":17807}" www.tuniu.com Statistics: "{"exception":2,"serverError":0,"success":466}" temai.tuniu.com Statistics: "{"exception":118,"serverError":0,"success":5603}" www.lvmama.com Statistics: "{"exception":1,"serverError":410,"success":39}" http://www.lvmama.com/tuangou/deal-580212 DOWNLOAD ERROR :400 结果
从监控数据可以看到和单线程结果基本一致
总结
从测试中可以发现,开源java爬虫Gecco对系统要求很低,体现其轻量化的特点。无论在单线程还是多线程环境下,系统均能稳定运行。对部分网站访问限制的问题,需要通过代理服务器来完成,Gecco是支持代理服务器随机选取的。
十、Gecco爬虫框架的线程和队列模型
简述
爬虫在抓取一个页面后一般有两个任务,一个是解析页面内容,一个是将需要继续抓取的url放入队列继续抓取。因此,当爬取的网页很多的情况下,待抓取url的管理也是爬虫框架需要解决的问题。本文主要说的是gecco爬虫框架的队列和线程模型。
线程和队列模型
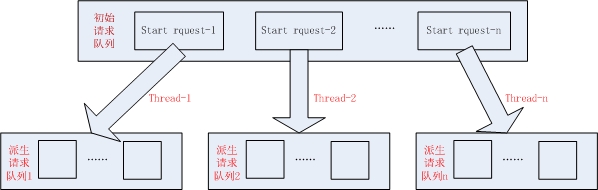
- gecco的队列模型是两级队列模型。分为初始请求队列和派生请求队列。初始请求队列在循环模式下是一个阻塞式的FIFO队列,在非循环模式下是一个非阻塞式的FIFO队列。派生队列是一个非阻塞的剔重的FIFO队列;
- 线程首先去初始请求队列按照FIFO原则获取一个请求,如果线程数量大于初始请求队列的数量,多余的线程就会待定新的初始请求入队,因此建议线程数量不要大于初始请求队列的数量;
- 对于循环模式loop(true),线程在抓取完成后,会将初始请求重新放入队列;
- 多线程只对初始请求队列有效,每个线程会有自己的派生请求队列,因此派生请求队列是在单线程下运行的,爬虫将派生请求放入队列继续抓取,直到没有派生请求;
- 线程在抓取完成派生请求后,会继续向初始请求队列获取初始请求
为什么要用这种模型
- Gecco的线程模型很像浏览器,每一个线程对应一个浏览器的Tab。每个浏览器的Tab一次只能看一个页面,因此就有了初始请求队列多线程,派生请求队列单线程的模型。
- 使用这种队列和线程模型开发人员很好理解,结构简单易懂,效率也能保证。想用多线程提高效率就想办法放入初始请求队列。
如何动态的获取初始请求队列
如果想通过多线程提高爬虫的效率就需要想办法将请求放入初始请求队列。我们可以先通过一个爬虫引擎将待抓取的请求保存起来。另外一个爬虫引擎以第一个爬虫引擎获取的请求作为初始请求开启多线程运行。简单说就是初始请求也是可以抓取出来的,并不一定非要写死。下面是jd采用多线程抓取的一段代码,全部代码已经上传github。
//先获取分类列表,放入AllSortPipeline.sortRequests
HttpGetRequest start = new HttpGetRequest("http://www.jd.com/allSort.aspx");
start.setCharset("GBK");
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo.jd")
.start(start)
.run();
//分类列表下的商品列表采用5线程抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo.jd")
//从上面的GeccoEngine获取初始请求
.start(AllSortPipeline.sortRequests)
.thread(5)
.interval(2000)
.start();