摘要
- 背景:前列腺癌是男性中第二常见的癌症。发展基于基因的分类方法是迫切的要求。我们的目标是建立基因分型。
- 方法:我们使用了四个前列腺癌数据集。癌症基因组图谱(TCGA)RNA-Seq数据用于训练分类器。基于分类器的三个亚型被测试是否具有临床数据存在显着差异。其他三组按分类器分类并验证。
- 结果:分类器有183个基因。前列腺癌亚型1(PCS1)的特征是高
GSTP1的表达,Gleason评分较低(P <0.001)。 PCS2有更高的Gleason评分,更多的淋巴淋巴结侵袭(P = 0.005)和病理T期(pT期)(P <0.001)。三GEO(基因表达Omnibus)验证数据集具有类似的结果。我们甚至观察到复发时间的重要性不同亚组之(GSE70768中P = 0.005)。 - 结论:我们基于RNA-Seq数据建立了PCS分类器(183个基因),并鉴定了3个的前列腺癌亚型。该亚型与可能具有临床应用潜力的临床数据有关。
关键词:前列腺癌;癌症基因组图谱(TCGA);Gleason得分;前列腺癌亚型分类器(PCS分类器)
介绍
尽管事实上的出现和新的筛查技术使前列腺癌更容易被诊断出来,但是随着发病率不断上升,它一直是美国男性癌症相关死亡的第二个原因(1-3)。超过95%的前列腺癌表现为腺癌。因此,探索前列腺的发展和预后分层癌症是非常重要的,特别是分子分类。
基于前列腺癌的特征,格里森评分是一种有效的评估前列腺癌的方法。传统上,格里森通过将数字加在一起来计算得分,两种最普遍的分化模式。但是,经过修订的评分系统(表S1)已在2016年WHO采用。biochemical recurrence (BCR)和高等级被观察到与预后相关。除了临床指标,一些蛋白质编码基因,如c-myc,Bcl-2和p53也与前列腺癌的预后有关(7,8)。
癌症基因组图谱(TCGA)是一个大型项目。它包含基因组特征
数据,高水平测序数据和相应的临床数据,包括所有常见肿瘤和几种罕见肿瘤的数据。该TCGA研究网络进行的综合分析在某些肿瘤例如胶质瘤和卵巢癌中,提供了一种对它们的诊断和治疗策略的新见解。前列腺腺癌的大型分析有由TCGA研究发表,揭示分子异质性和潜在的原发性前列腺癌的分子缺陷(12)。-
作为计算机科学的一个子领域,机器学习在生物信息学有着处理大数据的优势。到目前为止,它已经在很多案例取得了成功,为发现许多有价值的成果做出了巨大贡献(13,14)。在目前的研究中,我们应用了之前的研究方法对TCGA数据库进行分析,并找出一些有趣的结果,且可以成功的在其他三个数据集验证。
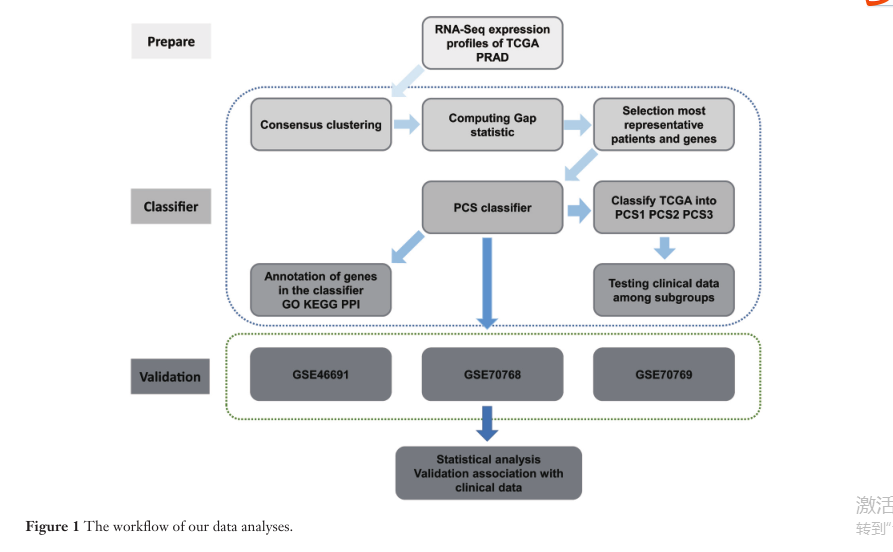 * 文章的流程图 *
* 文章的流程图 *
方法
- 数据准备
我们使用了四种不同系列的前列腺癌数据,本研究中有1258名独立患者(表S2)。TCGA RNAseqV2数据集由497个前列腺组成腺癌样本作为训练数据集。验证数据集包括三个前列腺癌系列,来自GEO(Gene Expression Omnibus):Erho的系列(GSE46691)有545名患者(15名),Lamb's(GSE70768)有125名患者(16名)和罗氏组(GSE70769)91名患者(16名)。 - 训练数据集(TCGA RNAseqV2和Clinical数据)
获得前列腺腺癌3级数据来自TCGA(https://tcga-data.nci.nih.gov/)
TCGA/)。 该数据集包括497名患有前列腺的个体
腺癌。 每个样品的RNA序列是基于Illumina HiSeq 2000 RNA测序进行分析版本2分析(https://wiki.nci.nih.gov/display/TCGA/RNA测序+版本+ 2)。来自TCGA的肿瘤样品是不仅在不同的机构和不同的时代,而且分批处理而不是同时处理会导致系统性的误导性分析
批次效应和趋势效应等噪音。 TCGABatchEffects网站(http://bioinformatics.mdanderson。org / tcgambatch /)用于评估和纠正批次对前列腺腺癌数据的影响。我们下载了经过处理的批次效应校正数据。此外,临床数据通过下载TCGAAssembler。 - 验证数据集(GEO系列)
表达谱以及GSE46691的临床数据,GSE70768和GSE70769通过R下载GEOquery包。对于每个数据集,表达式从探针组到基因和中位数注释了谱以所有样本为中心。我们填写了目标基因表达发生缺失值时为零。对于临床数据,我们集中在Gleason评分,T分期和预后
信息。 - 前列腺癌亚型(PCS)分类器和亚型的识别。
我们构建了一个PCS分类器来识别三种子类型利用算法研究TCGA的RNA-Seq表达谱 - 层次聚类
层次聚类是评估聚类的一种方法。使用R包“ConsensusClusterPlus”,
我们进行了具有凝聚力的层次聚类平均连锁并将这些患者分类为
通过10426最多变异基因的3-12个组。最多变异基因根据标准定义
中位数绝对偏差> 0.5。我们的中位数居中在所有计算和设置之前的所有表达式数组共1000次迭代,0.98次采样率聚类(19)。
计算gap statistic
gap statistic是确定最优分组的标准方法,数据集中的簇数通过比较数据集的变化观察到的和预期的簇内分散(20)。为了确定理想的聚类数,差距统计是对于所选择的顶部变量基因,从k = 1到6计算R群的“集群”(21)。选择患者和机器学习的基因
对于患者样本,我们计算了SilhouetteWildth识别每个中最具代表性的患者集群(22)。具有正轮廓宽度的患者是为以下分类器选择。同样,两个过滤应用步骤选择最具代表性的预测基因。首先,SAM(意义分析)微阵列(microarrays)用于显着鉴别差异
表达基因(FDR <0.01,假发现率)在一个子类型和其他R子包之间
“siggenes”(23)。其次,AUC(接收器下的区域)计算操作特性曲线曲线)估计一个基因分裂一个基因的预测能力其他人的子类型与R包“ROCR”(24)。只要FDR <0.01且AUC> 0.9的患者继续建立
PCS分类器。
- 构建PAM分类器并识别子类型
随着过滤患者和选定的基因,一个强大的分类器是由“PAMR”的R包构建的(微阵列R包的预测分析)基于最近的缩小质心算法(25)。我们成立了一个10次交叉验证,1000次迭代选择质心收缩的最佳阈值。最后,我们选择了分类器提供错误率<2%且数量最少基因,使用内置的PAM分类器,我们分类所有TCGA前列腺腺癌患者分为三个亚型进行后续分析。首先,我们将临床数据与前列腺的三种亚型相匹配腺癌检查是否会有差异Gleason评分,T分期或预后。其次,按顺序为了探索分子异质性,我们选择了一些流行的生物标志物或突变检查他们的表达不同亚型的变异。 - 分类器中基因的注释
为了解PCS基因的生物学意义,我们通过以下方法对基因进行注释。
基因本体论(GO)和京都基因百科全书和基因组(KEGG)途径分析
与生物学相关的基因本体注释 - 通路与KEGG通路富集分析
使用Database for Annotation实现了分类器可视化和集成发现(DAVID,https://david.ncifcrf.gov/)在线工具。 P值<0.001和基因计数> 2被设定为GO的阈值,KEGG的阈值是P值<0.05,基因计数> 2。 - 蛋白质 - 蛋白质相互作用(PPI)网络构建
我们将分类器映射到搜索工具中检索交互Genes数据库(String,http://string.embl.de/)并构建了一个PPI网络提供了预测蛋白质相互作用的信息。所需的最低交互分数设置为0.400。
我们用Cytoscape软件分析了PPI(http://www.cytoscape.org/)。 - 验证三个GEO数据集
来自GEO数据集的GSE70769,GSE70768和GSE46691
被选为验证集。基于PCS分类器在2.2.4节中生成,我们对每个验证数据集进行了分类并分析了给定的亚组和临床数据的关系。一些临床信息在系列中不一致。例如,GSE70768给了主要和次要格里森得分,而GSE46691刚刚给出了格里森的总得分。关于以上问题,我们利用了大部分临床数据和在结果部分中提供了详细信息。
- basal和luminal标记物在PCS亚型中的表达
为了确定PCS子类型是否对应luminal或basal肿瘤,我们分析了已知为管腔标记的基因(EZH2,AR,MKI67,NKX3-1,KLK2 / 3和ERG)或basal(ACTA2,GSTP1,IL6,KRT5和TP63)表达。
我们还进行了基因集富集分析(GSEA)提供PCS集群的一些生物学分析。 - 统计分析
使用样本聚类和分类在上面提到的相应的R包R软件(3.3版本)。临床资料被视为离散变量(时间到事件)和分类变量(格里森评分,病理学T分期(pT期),转移,和预后终点)。我们利用卡方检验检测到它们之间的关系,fisher的精确测试分类变量。 Kaplan-Meier曲线用于描述时间事件数据和对数秩方法用来测试差异。它被认为是重要的当P值<0.05时,统计学上。我们申请了统计软件包SPSS v20(IBM)来管理临床数据。 R软件和Microsoft PowerPoint(v2016)是用于可视化结果。