部署步骤:
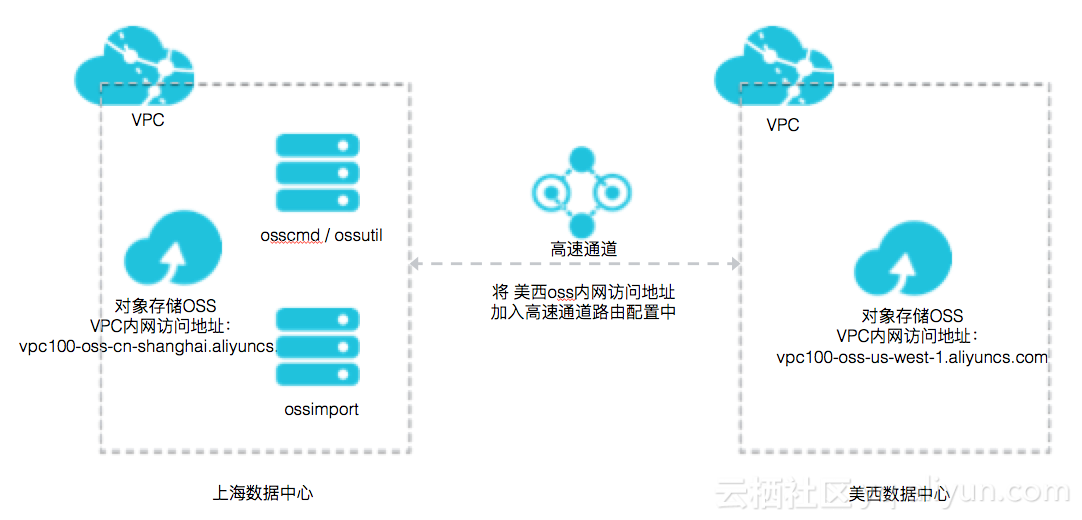
1、在上海region部署VPC1,VPC下部署ECS作为代理机器
2、在ECS上部署 ossimport,或者osscmd/ossutil
3、开通上海至美西的高速通道,将美西的OSS VPC内网访问地址 加入到高速通道的路由配置中
4、配置ossimport ,详细步骤参照:https://help.aliyun.com/document_detail/32201.html?spm=5176.doc44075.6.1037.T83MB2 ,其中目标端oss endpoint 填写OSS VPC内网访问endpoint,参见 https://help.aliyun.com/document_detail/31837.html
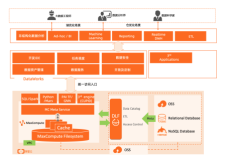
架构图:
注意事项:
1、ossimport适合大量多个文件传输,如果仅为单个文件同步,单线程无法将高速通道带宽打满
2、同步无法做到非常实时,可实现增量同步,目前工具中增量同步最小间隔为 900秒,文件大小限制为 1T
3、若是单个文件同步,可采用osscmd/ossutil下载至ECS中,再传输到美西OSS上
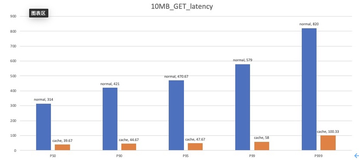
4、测试中采用10M 高速通道,可将带宽打满,同步速度完全取决于高速通道带宽