最近朋友圈刷疯了的几件事:
圣诞节骗我艾特微信官方戴红帽
老的跟树皮似的骗我晒18岁皂片
明明开挂却骗我自己玩的跳一跳
网易云听歌报告告诉我最爱tfboy
支付宝关键词鄙视我太穷丢它脸
个人特别喜欢听网易云音乐的推荐歌单(个人比较懒),但一个高播放量的歌单里的歌曲,不一定都喜欢,所以我爬取了9万多首歌曲,定制化了自己的网易云音乐歌单,
数据情况
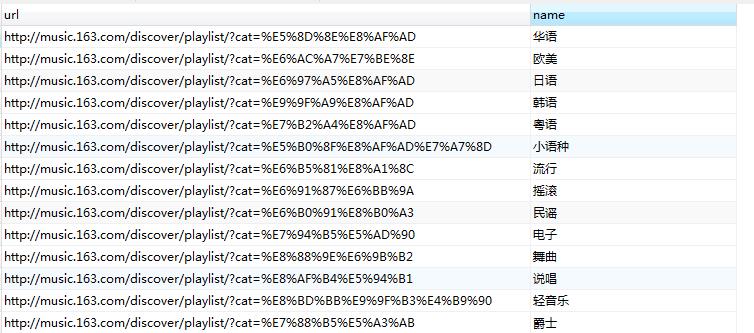
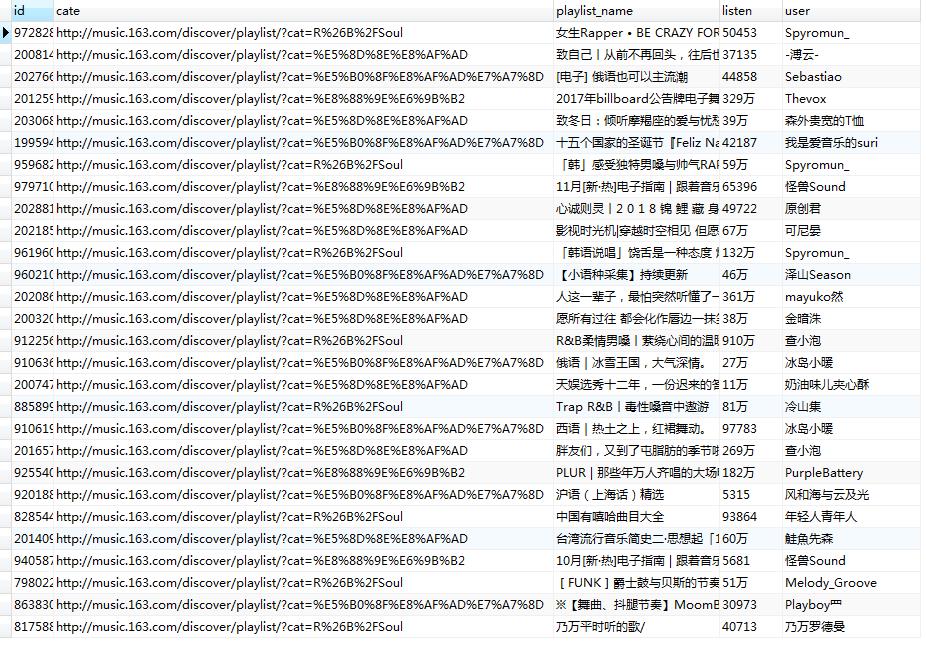
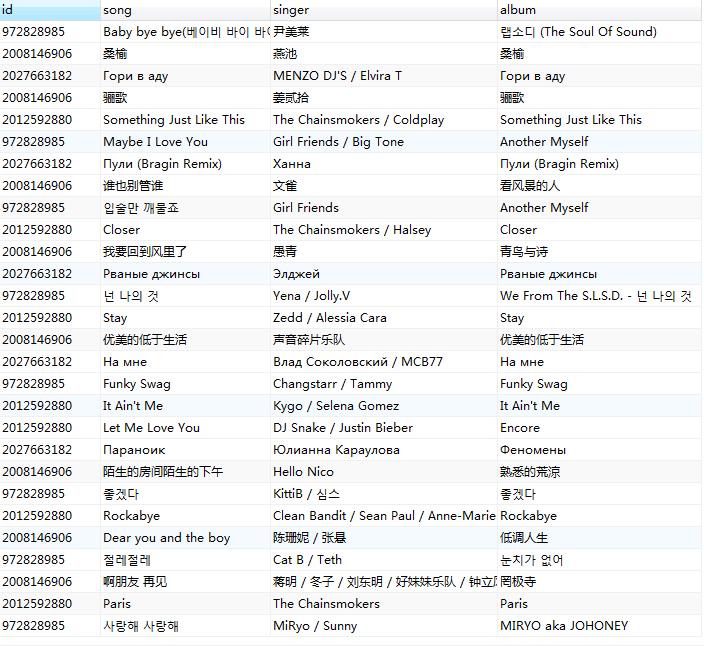
本文爬取了部分歌单,及歌单中的歌曲,如图所示。
数据分析
-
歌单类别
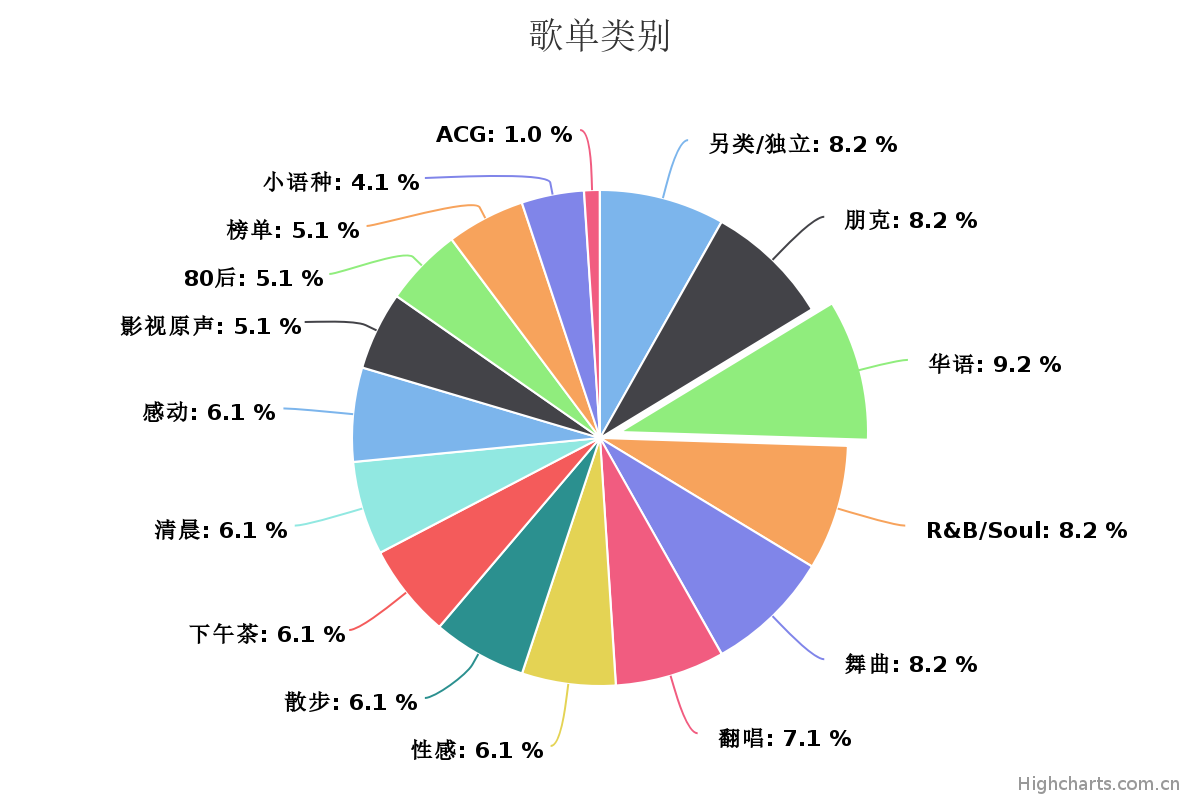
总共爬取了673个歌单,由于爬虫中断了,并没有爬取所有的类别,但爬取的歌单类别中,分布还是比较均匀的。
-
最火歌单
通过对播放量的预处理(有的是以万为单位),这里全部统一为万为单位。
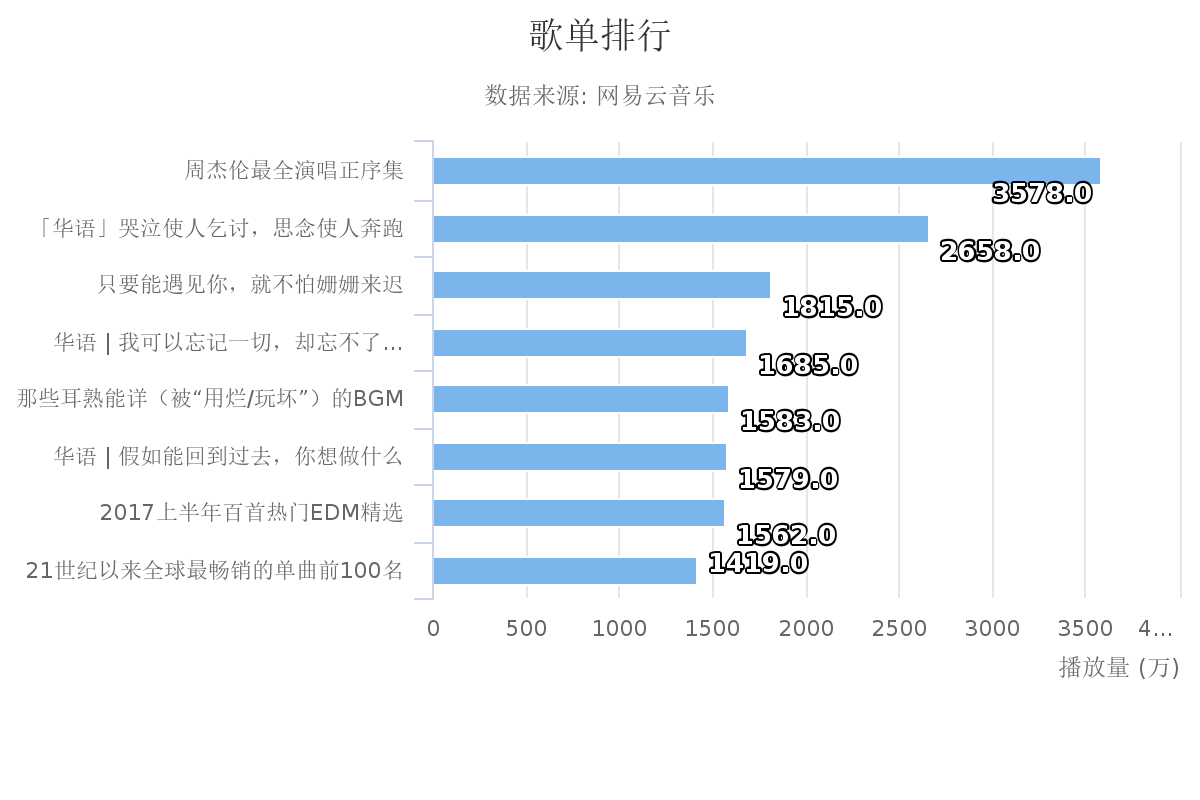
周杰伦果然是一代人的回忆,通过排行也可以看出,对于大部分用户来说,华语的播放量还是最多的。
-
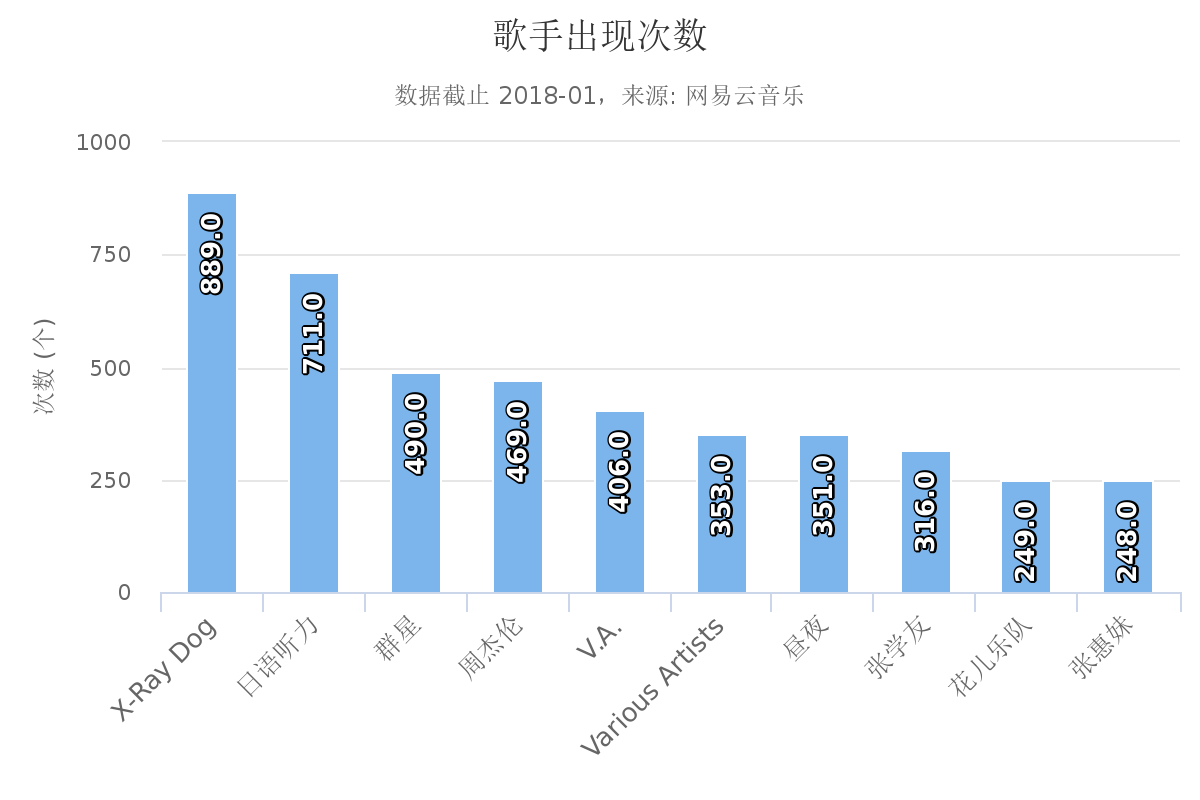
歌手出现次数
歌单推荐
还是前面的问题,通过播放量,只能推荐已有的歌单,但有时候歌单里的歌不是所有的都喜欢听。说下自己的思路,有些歌出现许多次,这样我就给这个歌扩大播放量,这样排序,得到了华语歌曲的歌单。
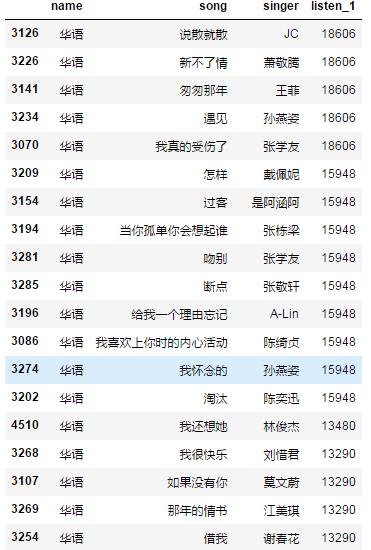
部分数据