一、算法测试
// openmptest的测试程序
#include "stdafx.h"
void Test(int n){
for (int i=0;i<10000;i++)
{
int j=0;
j = j+1;
}
printf("%d",n);
}
int _tmain(int argc, _TCHAR* argv[])
{
for (int i=0;i<10;i++)
{
Test(i);
}
getchar();
return 0;
}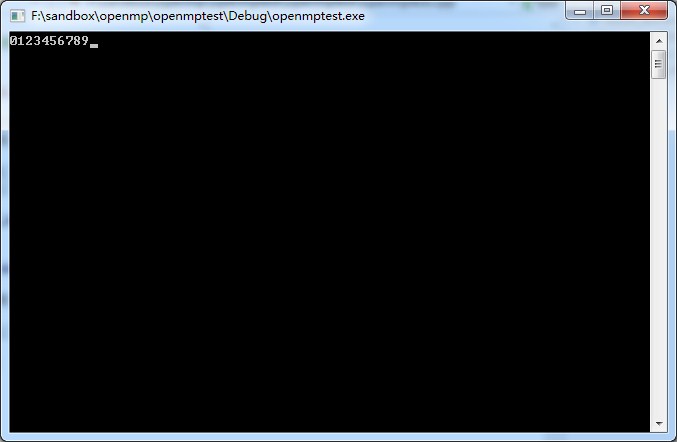
而开启openmp
// openmptest的测试程序
#include "stdafx.h"
void Test(int n){
for (int i=0;i<10000;i++)
{
int j=0;
j = j+1;
}
printf("%d",n);
}
int _tmain(int argc, _TCHAR* argv[])
{
for (int i=0;i<10;i++)
{
Test(i);
}
getchar();
return 0;
}
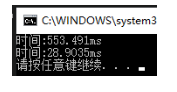
结果
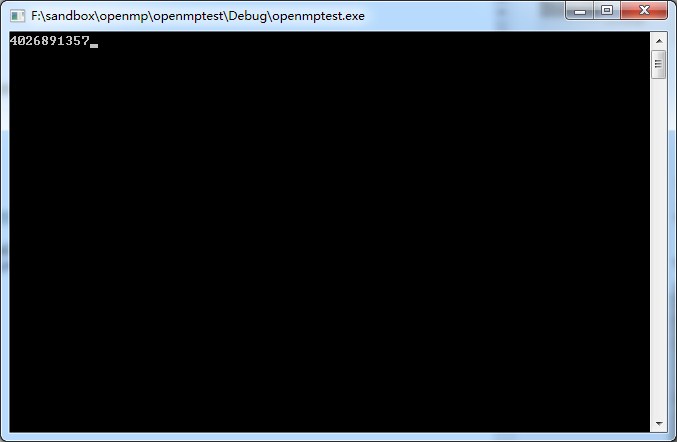
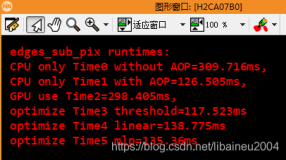
可以发现明显运算的顺序变化了,就是因为有并行的存在。
二、批量处理多张图片
编写较为复杂的opencv 程序
// openmptest的测试程序
#include "stdafx.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include "GoCvHelper.h"
using namespace std;
using namespace cv;
using namespace GO;
Mat Test(Mat src){
Mat draw;
Mat gray;
cvtColor(src,gray,COLOR_BGR2GRAY);
threshold(gray,gray,100,255,THRESH_OTSU);
connection2(gray,draw);
return draw;
}
int _tmain(int argc, _TCHAR* argv[])
{
//时间记录
const int64 start = getTickCount();
vector<Mat> vectorMats;
//文件目录
char cbuf[100] = "F:/图片资源/纹理库brodatz/brodatzjpg";
//获取所有文件
getFiles(cbuf,vectorMats);
//循环处理
// #pragma omp parallel for
for (int i=0;i<vectorMats.size();i++)
{
Mat dst = Test(vectorMats[i]);
}
//时间
double duration = (cv::getTickCount() - start)/getTickFrequency();
printf("共消耗时间%f",duration);
waitKey();
return 0;
}
使用openmp的时间
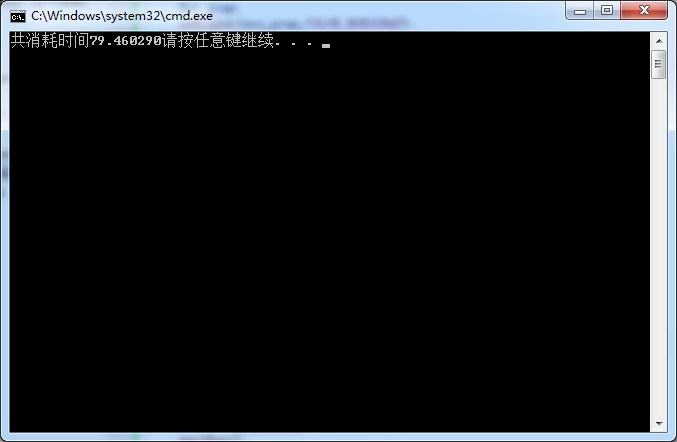
不用mp的是这么长时间
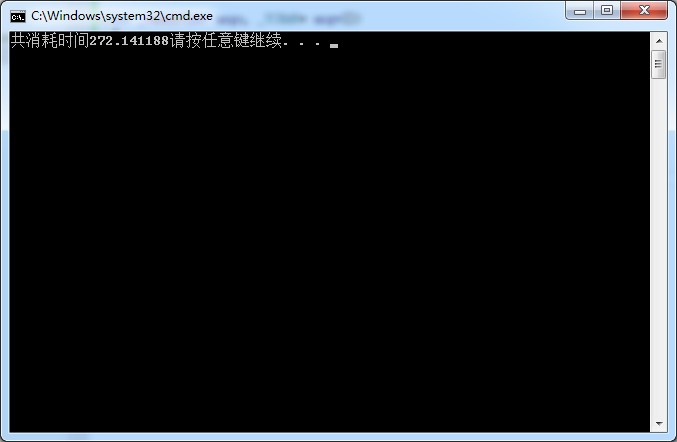
三、处理视频类流数据
进一步对openmp进行研究,发现它对于流数据也有很好支持:
#pragma omp parallel sections
{
#pragma omp section
{
GetHessianLambdas(camframe,5,lambda1_Sigma5,lambda2_Sigma5);
}
#pragma omp section
{
GetHessianLambdas(camframe,7,lambda1_Sigma7,lambda2_Sigma7);
}
}
就直接可已将运算速度至少增加一倍。
四、多平台支持。
而且对于QT的支持也非常直接,直接采用
QMAKE_CXXFLAGS += -fopenmp
LIBS += -fopenmp
加入配置文件,连代码都不需要修改,非常方便。
附件列表
目前方向:图像拼接融合、图像识别 联系方式:jsxyhelu@foxmail.com