早些时候,有个客户14块盘的磁盘阵列出现故障,需要恢复的数据是oracle数据库,客户在寻求数据恢复技术支持,要求我提供详细的数据恢复方案,以下是提供给客户的详细数据恢复解决方案,本方案包含Raid数据恢复和oracle数据库的恢复验证。
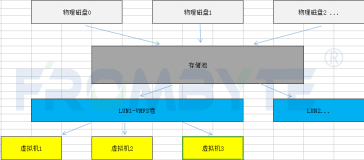
一、对磁盘阵列的恢复方案
磁盘阵列常见故障表现为:
A、阵列信息丢失,导致磁盘阵列在操作系统环境中查看不到;
B、阵列中多个硬盘掉线,导致阵列瘫痪;
C、人为的重新配置raid信息或Rebuild或者初始化等;
D、阵列中某块盘掉线一段时间后,又重新上线参与盘阵工作,导致整个阵列数据部分数据正常,另一部分数据不正常。
Raid数据恢复步骤是:
1、 第一步是做镜像:对每个硬盘做个镜像文件,存储到另外的空间上,对原始数据盘只读一次。如果盘阵的硬盘数量很多,单个硬盘容量很大的话,则需要很大的存储空间来存放这些镜像文件。这一步需要搭建的硬件环境是:准备一个空间足够大的可用的磁盘阵列,用来存放故障阵列的所有硬盘的镜像文件。硬盘镜像文件就是把整个硬盘通过硬件或者软件环境复制出跟硬盘完全一样的文件,在以后的恢复过程中,只用这个镜像文件去分析和重组数据,这样就保证整个恢复过程安全性,原始硬盘数据不会有二次损坏。
2、 第二步是分析底层数据:因为每个硬盘已经有了镜像文件,对镜像文件的分析等同于对原始数据的分析。在这一步分析中,我们可以确定出组成盘阵的硬盘数量,硬盘在磁盘阵列中的顺序,RAID配置中的块大小,数据走向等。如果有数据不新鲜的硬盘,我们也可以分析出来,在以后的重组中去掉这块盘就可以了。底层数据分析在WINDOWS系列的文件系统相对容易,但是在UNIX系列的文件系统难度就加大,目前我们在LINUX、AIX、SOLARIS、HP-UX、SCO UNIX、FREEBSD等都有成功的案例。
3、 第三步是重组数据:通过第二步地分析,得出一系列磁盘阵列参数—-硬盘数量、硬盘顺序、块大小、数据走向等,然后用D-Recovery For RAID软件对所有硬盘进行数据重新组合,写到另外的空间中。在这个过程中,我们需要准备的硬件环境是:准备一个空间足够大的可用的磁盘阵列,用于把重新组合出来的数据存放在这个空间上。
4、 第四步是恢复最终数据:数据重新组合出来以后,我们这一步要做的工作是把客户最终想要的数据恢复出来。如果是WINDOWS文件系统,这一步很容易完成;如果是UNIX文件系统,我们就要把组合出来的数据盘阵挂接到相应的UNIX环境下,然后在这个环境中找出客户想要的数据,把数据导到另外可用的空间上,以备客户验证数据。当然,也可以用D-Recovery For RAID软件直接把数据导出,存放到新的存储上。
5、 第五步是验证数据的正确性:客户数据在第四步已经COPY出来了,有些数据是直接看不出是否正确的,就像ORACLE数据库一样,恢复出来的是好多个文件,单个文件是没办法验证的。这就需要搭建一个ORACLE环境,把恢复出来的数据还原到ORACLE环境中,才能验证其正确性。其它数据库文件也是需要在相应的环境中验证的。
磁盘阵列最典型的故障恢复:
阵列信息完好,磁盘分区也能访问正常,但是数据就是打不开或者部分数据正常,部分数据不正常。特别是对oracle数据库来说,必须全部的库文件正常,数据库才正常。
举个案例说明:有个客户给我们拿来3块盘做数据恢复,客户的对故障现象是这样描述的:这3块盘是配成raid5,服务器在一个月前1号盘亮黄灯,当时没有在意,后来在前天机房停电,服务器也关闭了,当服务器再起来的时候,启动一切正常,1号盘也正常,不亮黄灯。但是系统起来以后,发现oracle数据库启动不正常。别的文件在一个月前放到服务器上的大都正常,就是这个月的文件大都不正常。
经过我们的分析,发现1号盘原来亮黄灯以后就不参与到RAID5里头工作了,2号盘和3号盘在缺1号盘的情况下继续工作一个多月。从底层数据分析知道,1号盘数据不新鲜,当机器重启以后,RAID卡没有报错,1号盘又参与RAID5数据组合,这样不新鲜的数据盘参与数据组合,自然导致部分可用部分不可用。我们缺1号盘,用D-Recovery For RAID从2号盘和3号盘重组出客户的数据,验证ORACLE数据库也全部通过。
如果是由于磁盘阵列故障导致的数据库不正常,整个恢复过程所花费的时间根据磁盘阵列的硬盘数量和硬盘大小来决定,一般不会超过一个星期。
二、对ORACLE数据库的恢复方案
ORALCE数据库相关文件恢复完成以后,我们还没办法直接判断恢复出来的数据库内容是否正确,需要把ORACLE数据库实例还原到ORACLE环境下才能验证。这就需要搭建好ORACLE环境,然后把恢复出来的ORACLE数据库实例在该环境下启动数据库,如果启动正常,那么数据恢复就顺利完成,如果数据库启动异常,则根据报错信息进行下一步分析。
ORALCE出错原因非常多,可以根据ORACLE错误代码来进行分析和解决。
比如错误代码为:ORA-01650:unable to extend rollback segment NAME by NUM intablespace NAME
产生原因:上述ORACLE错误为回滚段表空间不足引起的,这也是ORACLE数据管理员最常见的ORACLE错误信息。当用户在做一个非常庞大的数据操作导致现有回滚段的不足,使可分配用的回滚段表空间已满,无法再进行分配,就会出现上述的错误。
解决方式:使用“ALTER TABLESPACE tablespace_name ADD DATAFILE filename SIZE size_of_file”命令向指定的数据增加表空间,根据具体的情况可以增加一个或多个表空间。
声明:作者达思数据恢复技术专家覃廷良,本文首发http://www.bnuol.com,在donews.com,51cto,techweb,新浪,百度等数据恢复技术博客上转发.欢迎转发,转发请保留作者及出处。