陈以鎏(离青) 阿里巴巴资深研发工程师:大家下午好,这个主题是云时代下的性能优越和运维的实践之路。首先做一个自我介绍,我花名是离青。
刚才为大家介绍了百川的整体的业务情况,提到“百川”时有两个关键词,商业和技术,技术是百川移动云的部分,我们希望能够承担起为移动开发者赋能的伟大使命。
在基础构建部分,我们有消息推送,多媒体和应用推广,在运维支撑部分有应用反馈。还有热修复,同时移动安全、视频服务、应用分析、舆情分析,我们在后续会有一系列的动作。
今天会围绕应用监控和服务监控来展开。
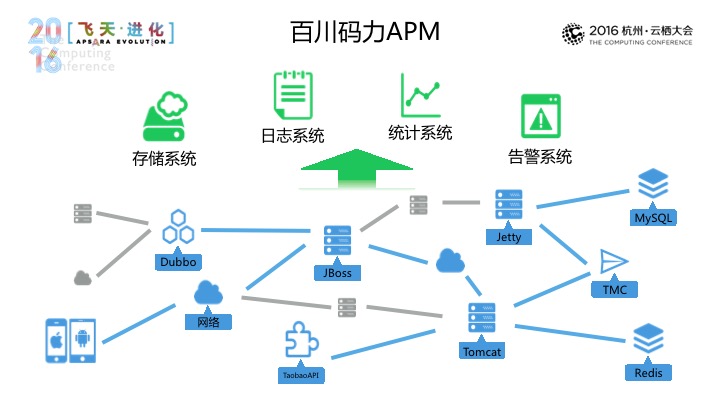
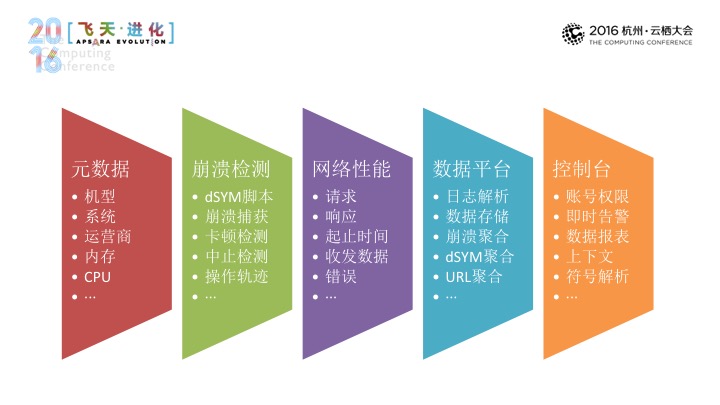
那应用监控和服务监控构成了百川码力APM,希望提供一站式的端到端应用监控,在应用监控部分能够采集IOS、安卓等数据,在服务这部分,从一些容器进行监控,同时支持到MYSQL和REDIS,最后是淘宝消息服务TMC、分布式开放框架DUBBO,以及API,上到日志系统,之后我们的统计系统会进行计算和处理,来帮助开发者去长期对应用和服务做出智能前。同时高级的系统可以根据用户设定的规则在问题发生时可以发出一些告警,帮助开发者及时解决一些问题。
接下来由我为大家介绍一下在百川码力APM。
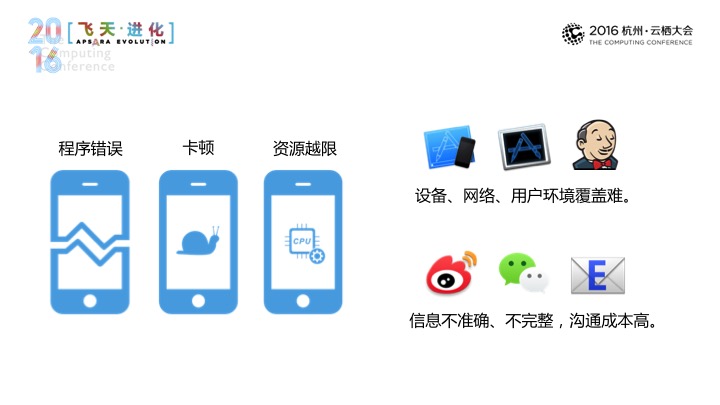
在应用开发时,程序错误、卡顿、资源越限,导致系统朋友,这是我们面临最严重的,也是我们首先要去解决的问题,在这里,传统领域手段,我们可以借助自动化的支持,可以发现一部分的应用问题,这些手段往往难以覆盖到用户的真实的复杂场景,这一切都正常,但在崩溃的情况下会时有发生,如果希望去收集正式用户的反馈,我们往往会去使用设备媒体或邮件反馈的渠道,后面的框是一个邮件标,如果我们使用这些渠道能够收集到一部分用户反馈,这些问题往往不能给到我们所需要的去解决问题所需要的这部分信息,为了尽可能去收集用户的真实使用场景中产生的这样一些崩溃信息,那码力APM是引入了崩溃信息暂行的工具,帮助开发者能够解决应用中存在的问题。
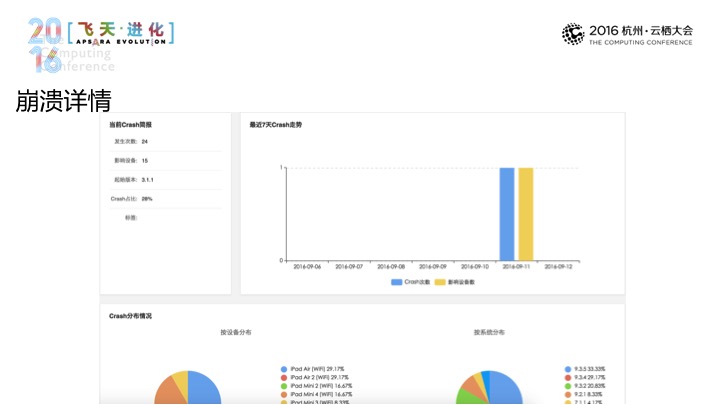
在码力APM控制台中会进行呈现,这里呈现的是趋势分析,我们将应用崩溃向一个次数汇集成时间曲线,希望能让用户去了解应用崩溃的整体趋势。可以帮助开发者了解崩溃对于用户产生的影响,而上方的这个可以在不同的本本和不同的时间里做出崩溃趋势的比对。
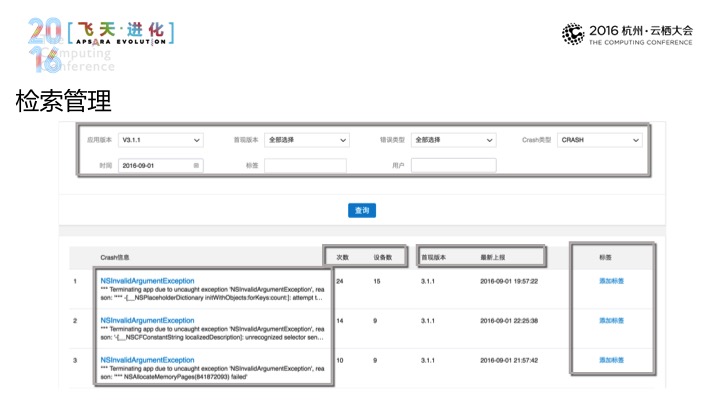
在崩溃的检索里面里进行检索管理,基于标签和用户的精确删除,在删除的结果当中,我们这边会对统一调用进行聚合,我们会避免说崩溃链太长,这里设备数,所以帮你作出分析,标签的部分可以对单条的崩溃作出简单的归类或管理这样一些努力。点击单条,在崩溃长期页面里会成立崩溃统计方面的信息,这里给到崩溃的趋势,基于设备和趋势的情况。
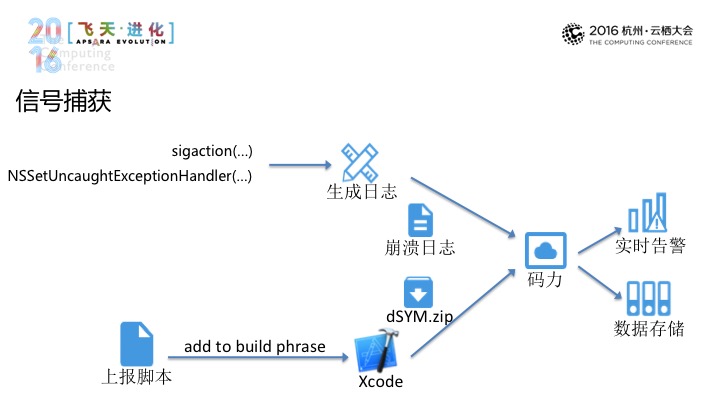
在下方是符号堆栈,我们还提供到了像是用户、网络、渠道这样一些信息来帮助我们进一步去确定崩溃的这样一个现场。那么具体来说的话,我们是怎样从客户端上采集这些信息的,苹果的IOS APPLICATION CROSH REPORTS列举出来了,进行信号捕获的方式进行采集, Resource可以通过CPU和内存检测,EXC GUARD可以通过中止检测,HEX VALUE,可以通过卡顿、中止检测来进行识别,这个议程主线程的卡顿来进行出发,其他是中止检测来进行识别。
接下来我逐一为大家介绍一下所使用的检测方式。
第一种方式信号捕获,我们通过sigaction,可以通过程序运行时的状态对于生成日志,还有卫星捕获的方式,可以通过nssetUncaughtExceptionhandler,再根据崩溃日志的调用站统一调用崩溃,再到系统集中,与此同时,高级系统可以根据崩溃次数等信息来发出及时的告警。那上报之后,这里提供了文件自动上报的流程,还可以提供上报脚本,在编译时就可以上报到服务端。这里第二次数据聚合,我们会将它进行聚合之后再到数据库,这一次聚合过程可以减少DSYM的文件,与此同时,我们还提供了崩溃日志的解析的服务。这样的话,我们可以更好地利用云计算的能力去服务更多的开发者。
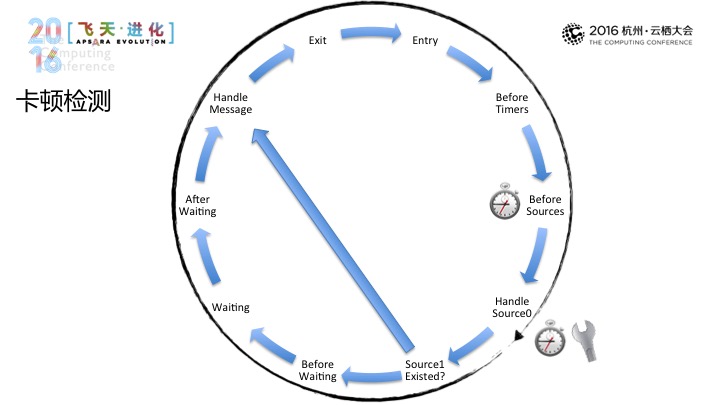
第二种检测的方式是卡顿检测。卡顿检测的方式是依赖监控主线程的变更,在这里我们视作为在操作上跑圈的“运动员”,我们会每隔一段时间的间隔去判断是否跑过了一圈,如果在时间间隔之内没有跑过一圈的话,说明在Handle Message(音)等过程当中消耗了过多的时间,这个时候就视为主线程发生卡顿。
与此同时,我们在这个地方会根据运行的不同时段,如运用到后台阶段、控程的阶段调整值。
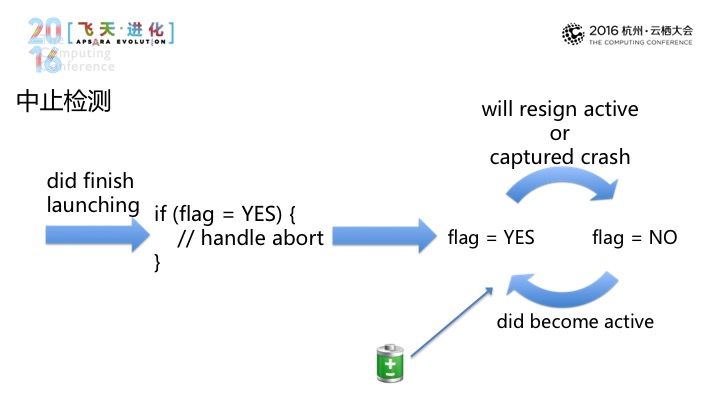
第三部分是中止检测,中止检测不同于前两种,通过检测来发现问题的存在,那在中止检测中具体是这样做的,如果flag存在的话,就进行应用的非正常因素来上报。这里有一个特殊的案例,就是我们的设备有可能因为电量耗尽而非正常退出,这里的话,我们会去检测电池电量,电池电量很低的话,我们会清楚掉,这样可以避免检测的误报。
第二块,在应用开发过程当中,有请求错误、流量杀手、网络劫持,这是需要我们去面临另外一个棘手的问题,能够发现简单的网络问题,这难以去识别到国内这么复杂的网络环境。与此同时,他们所采集的的网络信息,我们很难去帮他们导出进行一个长期的比对。如果使用手工的方式进入的话,一方面自己去面对各种各样的系统的网络接口,另一方面,我们应用的网络代码做变更时需要去对应更新我们的埋点代码,去监控应用在真实网络当中的性能。百川码力推出了无痕埋点,我们希望开发者去长期监控自己的网络性能,去优化自己的产品体验。
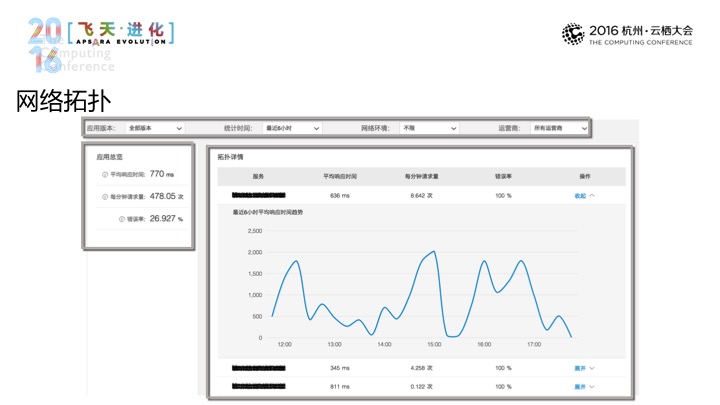
那网络的数据一样的,上报了之后可以在百川码力控制来做呈现,这里我们可以给到一个总览的信息,可以给到平均响应时间,请求的次数和错误率的信息。在右边的拓扑的部分,以HOS(音)作为区分,会显示出每一个HOS(音)的时间,点击展开了之后,会有这样一个趋势图。
上方的部分是在不同的版本、不同的时段,不同的某个环境之间去做网络性能方面的比对。
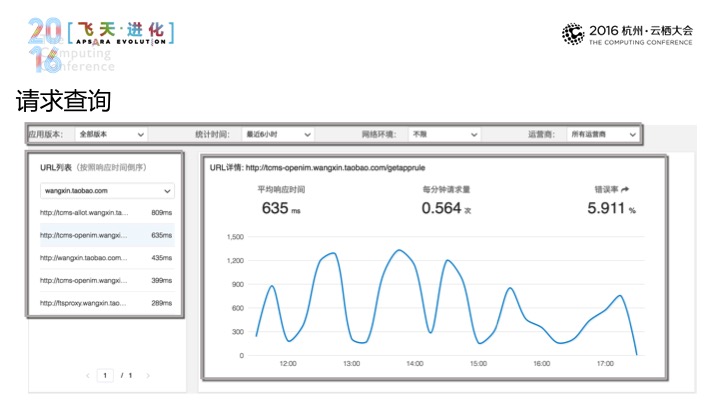
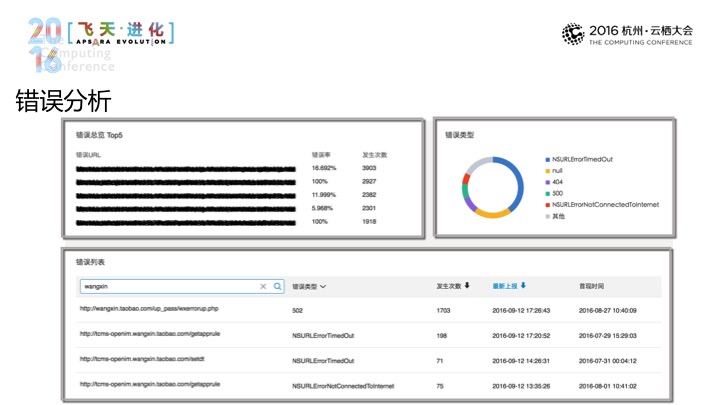
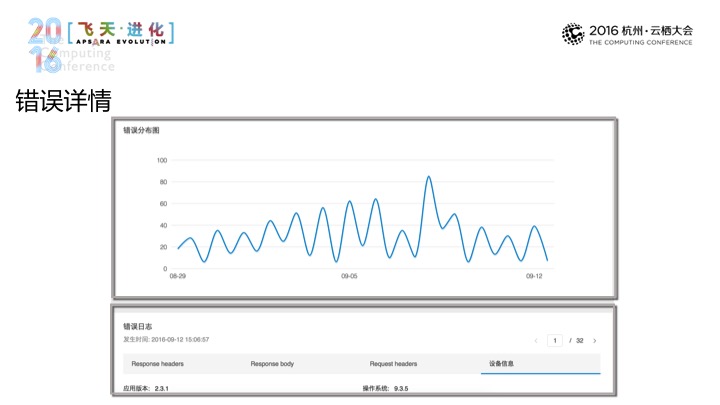
那进入到请求查询页面当中依然可以进入到筛选当中,时段、运营商和网络环境去作出一个初步的数据筛选。我们优化了很大的URL,那在这个选择当中,我们还是可以通过HST(音)做出更精确的筛选。之后在右边显示出URL单个的详情,还有请求时间、次数和错误等信息,包括趋势图,那点击这边错误率的部分是可以进入到错误分析页面,在错误分析页面,我们会列出我们出错次数最多的URL,会有错误的分布。在上面的列表中,我可以根据URL和错误位置进行筛选,可以根据发生的次数进行排序。那点击了之后可以进入到错误详情页面,错误的详情页面除了给到错误的分布之外,可以有用户发生错误的日志,日志当中会有设备信息来帮助我们去定位用户发生错误的这样一个场景。
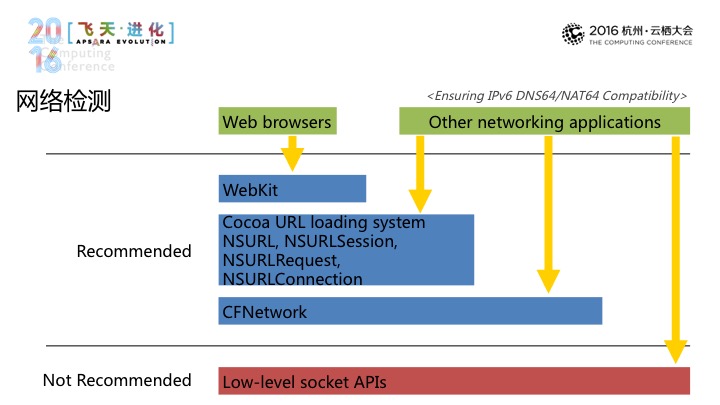
具体来说我们是怎样实现网络性能检测的,ensuring IPv6 dns64/dat64 Compatibitity给出的一个建议。
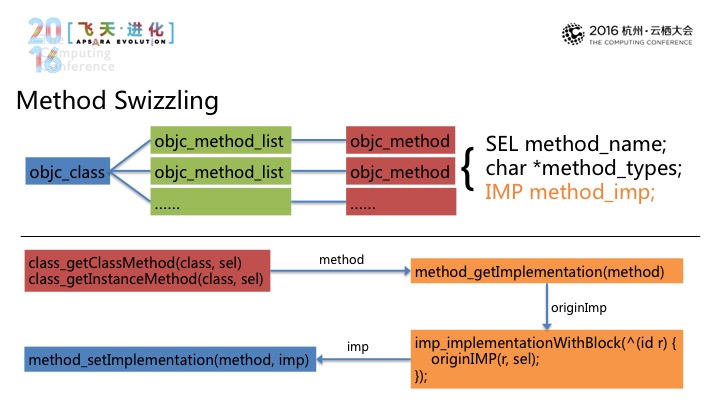
第一种是Method Swizzling,指向Objc Class,两种会指向mbjc m为ethod,后面包括lel、char、imp(音),再通过mehtod、origin imp、imp,我们就可以在原始的行为前后再来替换进行实现。
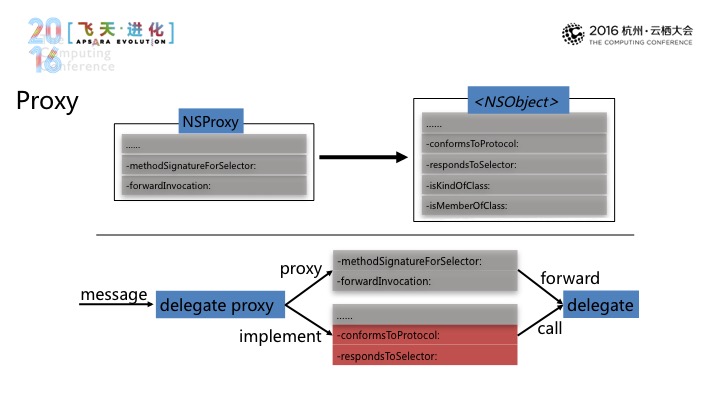
第二种方式是Proxy,包括NSProxy,和NSObject。
在我们的实践中,我们是使用NSProxy,在收到一条消息时,如果这个消息不是我们的目标协议方面,也就是我们不实现这个方法的话,将它专发给delegate,这边需要特殊注意的是,由于系统的多数的这种协议方法,多数是可选的,因此在这边需要来额外声明。
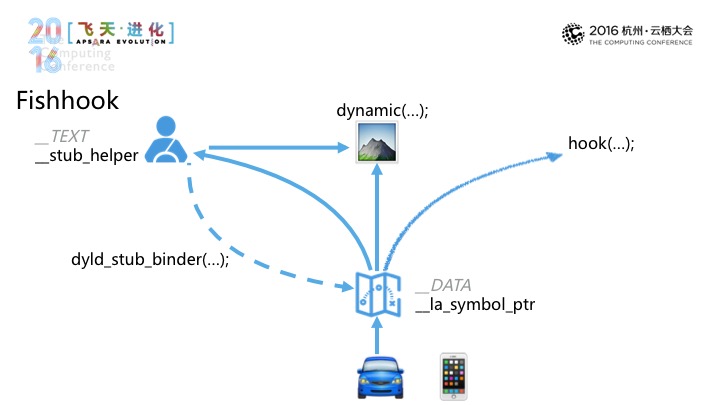
另外是Fishhbook,我们以一个驾车的例子来说明。一个新手司机驾车从家里开到一个目的地,老司机告诉他你怎样走比较OK,之后的话,虽然第一次走会绕一点路,但之后再去的话,对应到程序运行的时候的话,我们程序运行时,我们的程序的目标调用的函数的话是dynamic,在初始的时候,dynamic不会包含到具体的时间、地址,因此在首次调用时,TEXT stub helper,再通过dyld stub binder,之后调用再不用麻烦,就直接通过dynamic、la symbol ptr,如果要修改的话,有函数指向的话,我们就可以进行Hook。这个事情需要大家看一下facebook相关的一篇文章。
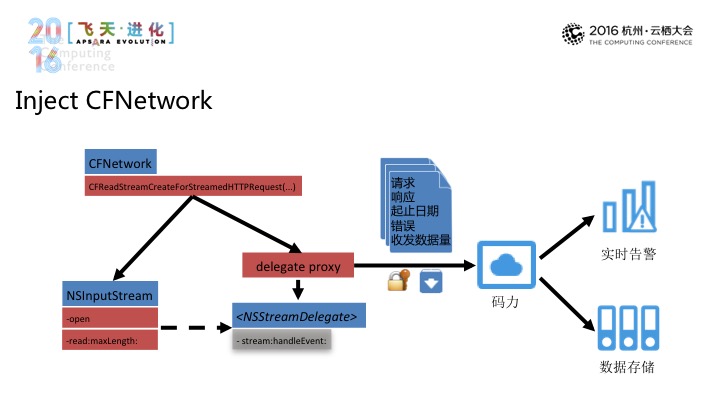
下面Inject Cfnetwork,我们使用nsinpusttream,替换掉open和read:maxlength的方法,之后是stream:handleEvent(音),再通过请求、响应、起止日期、错误、收发数据量,再到码力,进行实时告警和数据存储。让用户不需从零开始去进行开发,数据平台和控制平台就可以享受到可视化的根据,我们是欢迎大家去来使用产品的。接下来我们会冰撤同学来介绍一下服务的部分。
熊奇(冰撤)阿里巴巴技术专家:刚才已经讲了很多APP端的管理相关的内容,我简单自我介绍一下,我花名叫冰撤,目前是围绕着如何降低开发者成本的工具。
今天所说的优化,对某一个应用程序进行一个活动,我们今天并不会说参数怎么更加合理,今天将信息优化和运维放在一起讲,是因为这两者从本质上来说是同样一件事情,就是成本的关注是一个持续的工作,信息优化是可以利用UPM(音)的工具去持续地被关注、被改进的,到运维的体系里,今天更多的是从产品来讲讲这件事情是怎么去做更加全面、更加高效的。
之前我也请教了更多公司的运维大佬,其中有一位告诉我,这是一个非常有名的系列,他说对于用户或者对于开放来讲觉得很用,这是第一,总之不是太爽,这当然是一个玩笑。那怎样做好?
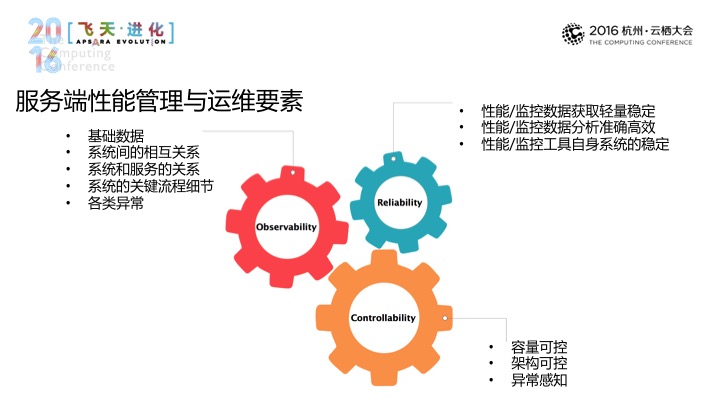
服务端的性能管理这件事情总结下来是三点:可见、可靠、可控。无论是什么样的工具、什么样的系统,想要把这件事情做好的话基本跑不开这三点。我讲一下。
如何可见?比如一个应用的访问情况,或是系统跟它产生关系的一系列的系统,或不同的系列决策,它们之间的相互关系做到可见,最典型的是现在流行的架构,这些架构带来的复杂性更需要我们看清楚这些不同决策之间的相互关系,以上是从广度上来说的。
深度上来说,系统里的所有关键内容是要做到可见的,典型的是一个下单的流程,这个下单的流程过程当中是不是有一个接口错了,或是某一个环节耗时?还有一个系统里的各种异常也需要清晰、体系化地能够体现出来。
可靠的是我们用的工具或系统是从这个角度而言的,数据采集是不是比较高效,分析数据的话,数据分析是不是足够实,再一个是可靠性问题,关键时刻会不会掉链子。
可控是最根本的要素,只有做到了可控才能说在宏观上面采用一些效应,才能最大化地去控制成本。所以这个其实也是做运维的一个比较核心的事情,可控其实是典型的容量的可控,随着时间的推移,一个系统或一套系统,其容量变化是不是合理,是不是有趣,是不是比现在做得更好?比如一个集群,典型的是一个业务系统,随着业务的发展,架构有没有孵化,有没有乱掉,有没有引入一些不该有的依赖。还有系统里的各种异动,无论大小都能够第一时间感受到,这是可控上的典型的体现。
今天我们看来,很多同行对于应用型管理的要素有一个认知上的误区,就觉得说这是做可视化的,我有很多功能,然后通过简单地点一点鼠标就能够满足很多工作。其实这个严格意义上来说,只是第一步,就技术而言,无论角色是开发还是运维,我们做运维或者是做应用性管理,我们本质上而言我还是在于怎么去控制成本,我们当然有很多开源工具或商业化工具,你仔细研究发现之后更多的是解决了可见或可视化的问题,在可靠和可控上还需要下很多功夫,这其实是需要一些长期的持续的投入和时间上的积累。
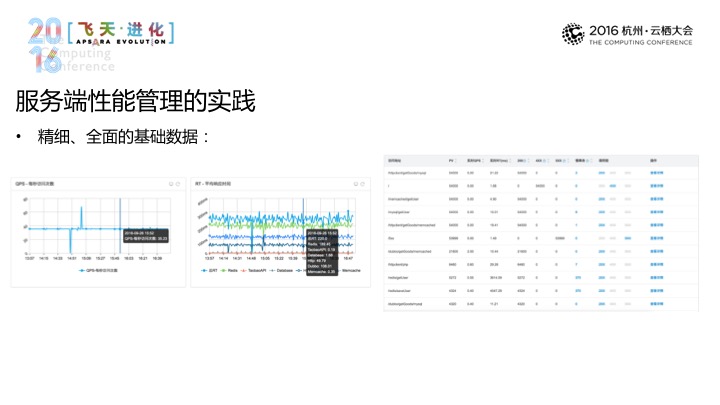
说到实践,码力APM在服务端的实践,给大家看一下,如基础数据怎么看,基础数据,第一是讲全面,第二是讲精细,比如APP一部分的数据。该有的多有,这是全面。精细体现为,比如这里这一张图,这里还分门别类的,比如是关键依赖的,精细再一个体现,我这一个系统所有的入口,无论是URL,还是RTC接口,它的错误率是否也能够分门别类地看到,这也是一个精细的体现。还有一点是上面没有体现出来的就是基线,针对于历史的运营情况,我现在的这些量,这些数据有没有差很多,这个其实也是一个非常有价值的数据,这个也是在做容量可控的体系。
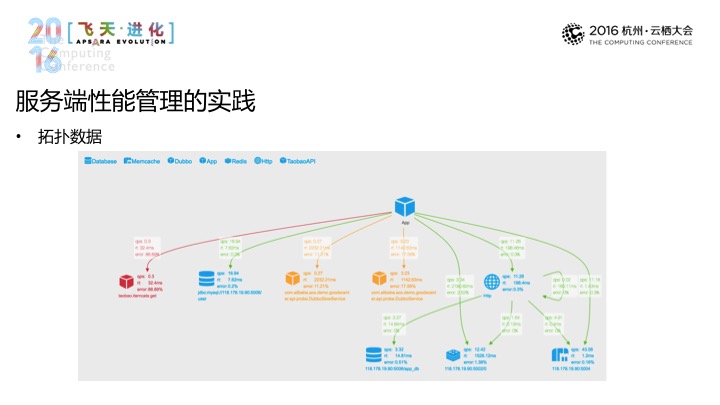
那基础数据之外,我刚才其实说过,我们需要对应用和系统架构做一个持续的关注,去做架构上的可控。那往常的做法就是想做一些架构上的把控的话,最常见的是做人为梳理,在半年或一年的时候。现在系统已经怎么变成这样的,不行,要重构或改造这样的,这样的剧情大家应该非常熟悉。那我们认为对于架构的关注可以变成一个常态化的工作,就像这张图所呈现的一个,它体现的三个事情,第一能够实时地反映出来这个应用和应用的上下文关系,有了这个数据之后,架构师不用再去架构数据,通过验证看出来下游是哪些,就像这张图体现的一样,能够看出来,比如有数据库,有好一个DUBBLE接口,还有HTTP接口(音),再一个是能够实时反映出来流量转化上的东西,一个进来,然后继续往下游,进入某一个环节,到底是翻倍了,还是减慢了。还有一个是实时反映依赖的健康情况,就像这个图一样最左边,我现在依赖的服务在报错了,有了这个数据之后,可以干的事情非常多。
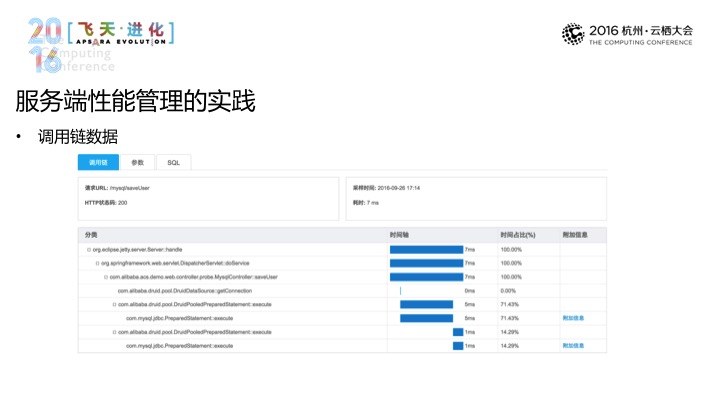
落到细节层面,对于细节层面的关键链路都已经做了代码级的工作,最典型的是一个请求是什么,耗时,有哪些搜索语句,包括具体的代码层面的耗时,报错,都能够一眼就能够看到。
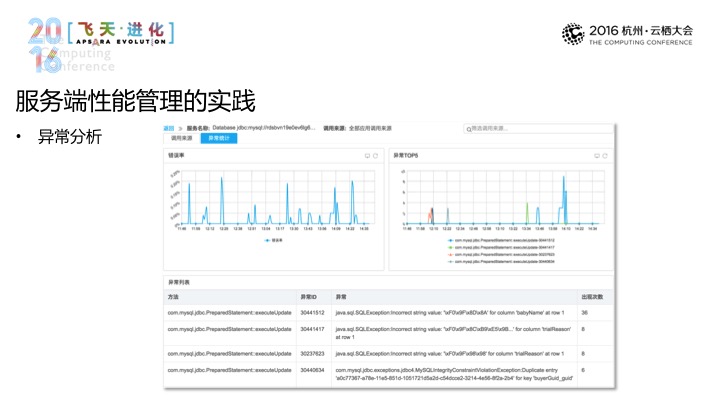
再有一块是异常,这个其实有很多同类型的产品或者是工具所忽视或没有系统化去做的,当然,这个异常有很多出口,从什么维度上去看什么好,这是一个问题。通常的做法是看看这个系统有什么用,或访问码等,再结合日志进行分析,这是一种方式。我们采取的方式是依赖这个维度去切入的,为什么要在这个维度上去做,通常来说,最容易出问题的,这往往是经常排查的,往往是出在应用依赖上的,应用出问题了,或依赖的数据库出问题了。那我们对于应用的依赖做一个系统化的异常层面的关注,就相当于将异常的关注刚好卡在了一个层次上,就像这个图所呈现的一样,它呈现的是一个数据库的依赖,包含了这个应用访问的数据库的什么时间发生了什么错误,然后出现的次数、出现的错误有哪些,然后相应的这些错误的具体详细是什么样的,等等,这些都有。基本上你有了这个层面的数据之后一个应用过去发生和正在发生的一切问题都一目了然了。
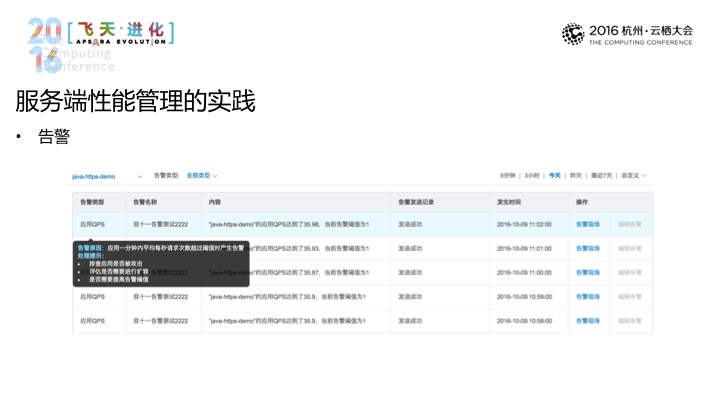
那有了这些数据之后还要解决感知的问题,最重要的是通过告警,通过两个,一个是你得足够灵活,无论是刚才的基础数据还是异常数据,都要能够做到有足够灵活的条件,通过不同的通道,然后让相应的人感知到,这第一。
第二点,对所有的这些告警都要做到可靠。你要能够清楚地知道当时发生了什么。就是这样。
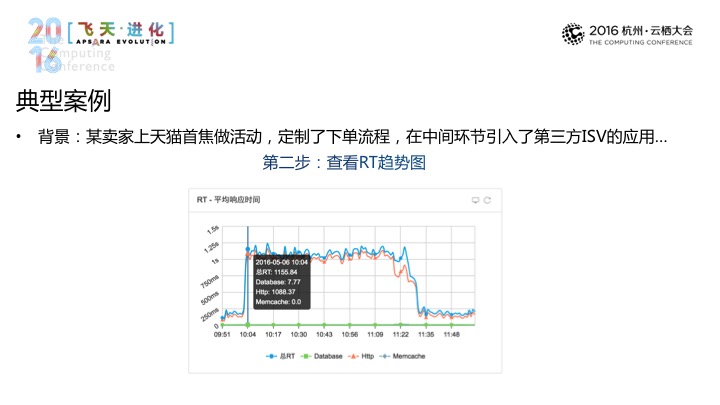
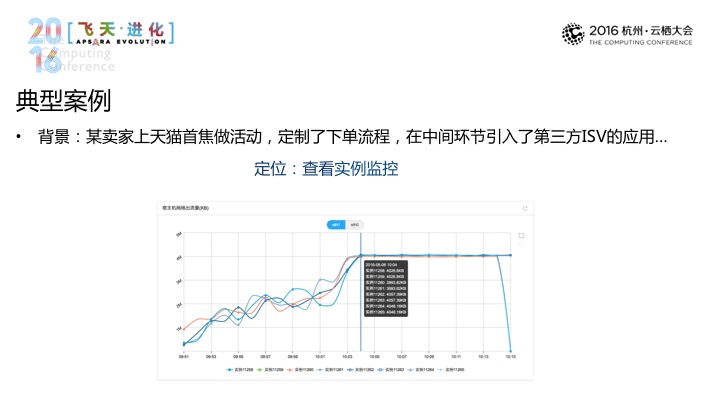
所以到这里呢基本上我们在服务端的产品最关键的点,大家可以看一个具体的例子,这个例子的背景这样的有一天一个天猫上的大卖家在天猫首页上做一个活动,这个活动里面引用了一个第三方的应用,通过这个第三方的应用将下单流程进行了定制,是这样一个事情。活动没多久,就收到了一条告警就说这个应用的响应时间特别高,第二部分,它去看看具体的应用场景到底怎么样,因为我们已经将它内部关键的服务的详情都拎出来了,接着第三步是可以在应用整体层面看看调用到底在干什么事情。第一个是他发现在做图片上传的事情,这个图里面的HTTP(音)的目标地址都是多媒体服务的接口,然后他发现再一个是这些调用的KPS(音)并不是很高。另外是两种选择,一种是看看服务,这个服务本身有什么问题,再一个是它可以去看看手里的其他数据,错误率基本为零,所以这些图片的接口,其实概率是比较小的,所以进一步去看看其他数据,如带宽,它到了这里会发现,所有的带宽,对于天猫商业带来的商量是没有什么概念的,所以说,它这个应用,从他收到短信到之后的解决,前后不过5分钟的时间,它有这样一个闭环的管理工具或运维工具,这是一个非常重要的事情。
这里要稍微听下来去讲讲原理性的东西,刚才所有的这些产品的实践的功能,背后都需要有一些技术上的支撑,比如说数据采集相关的,甚至是数据呈现相关的,这些数据关系怎么讲一讲数据采集方面的内容,因为这个是与应用直接打交道的部分。
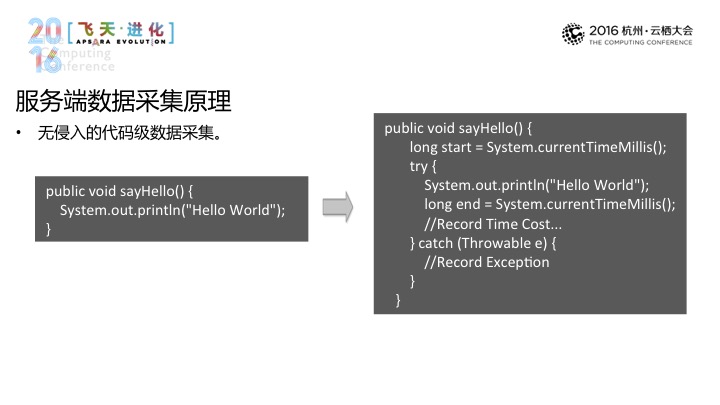
刚才也说过代码,还有一个潜台词是无侵入,为何要无侵入?对于业务代码,其中掺杂了很多,这对于一个做维护应用的同学来讲肯定是不一样看到的,背后是帮助用户,对于一个最简单的,我需要在前后将这些逻辑加上,将这些异常给加上等。
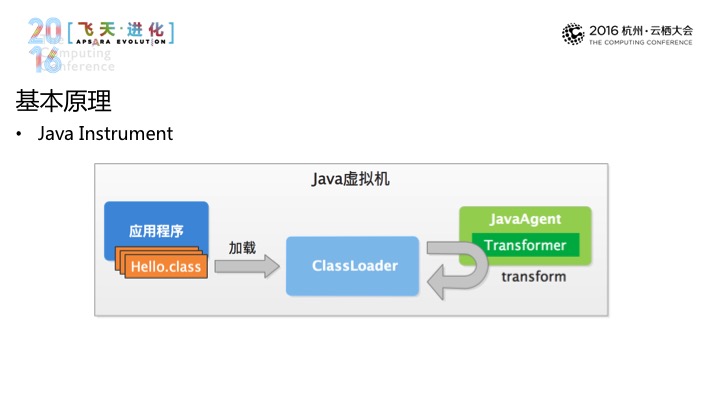
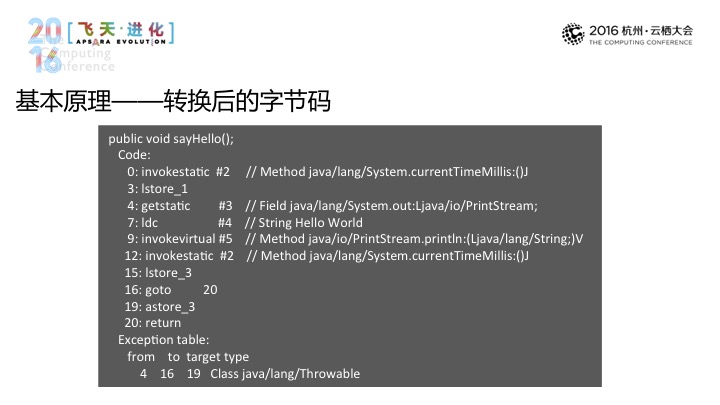
进一步看,举一个Java的例子,它其中可以输出很多运行期的数据和功能,在这之上它提供了一个叫Instrument的包,它提供给我们的一项能力是在加载的时候,具体到图上而言,做修改的事情是通过一个Transformer而实现的,可以将原始的码拿过来交给Transformer,Transformer再对其进行改变。
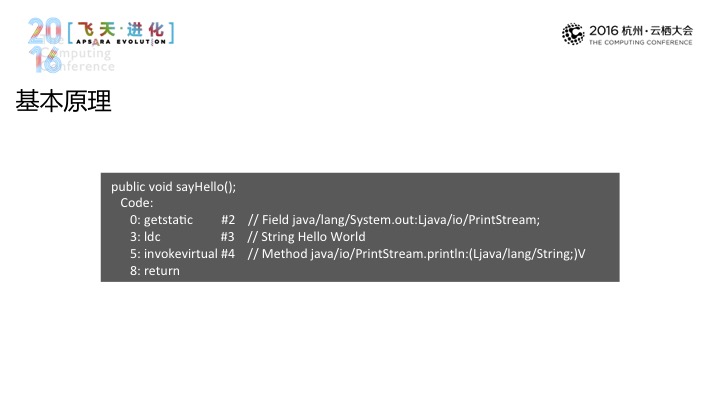
这是基本原理。
经过转换之后,这个还是最简单的一种场景,真实的实现当中还是会解析一下目标调用的结果等,要做这些事情,这是一个基本的原理,相信它有比较高昂的代价,对于感兴趣的组件都要去做改造,从WEB容器到框架等一系列的组件都要做相应的适配和相应的开发,所有的数据采集的实现都会不一样,更不要说一些不同的容器或是框架也好,它都有不同版本的问题。所以说,总体来说,这样一种方式的成本其实是不低的。
最后说一下用户最为感兴趣的是对性能的影响,毕竟已经嵌入到它的应用里面去了,有三点,第一对流程的影响,第二是对于真实的数据链路的耗时影响有多少,总体而言,对于数据采集要有一个收集全异步,在什么环节采集数据,采用异步化的方式,第二点,做了数据上的工作,对于采集下来的数据需要做一个质量上的控制,如过去15秒或30秒。再有一点,也是最重要的一点,是如何去保证对原程序的影响最小,因为刚才大家看过前后的比较的话,就会发现修改过后的码,CPU会有更多的负担,很多关键的数据要通过反射的方式来进行的,所以程度上而言的话,数据的获取就已经落在了反射上,典型的方式有这一些,对于耗时影响不是特别敏感的,但又需要每次重新取数字的场景化,需要通过反射对象的内容。再一个,发生变化的场景,比如说一个数据库或调用地址,对于这样的一个场景可以将反射调用的结果缓存下来,要求更高一点的,要通过更麻烦的,加桩接口的方式,通过它来实现自定义的接口,这个接口只有我自己,就可以将内部的一些数据直接透出来,在进行数据采集时直接通过自定义的接口来达到,这是一种方式。
这个就是关于数据采集方面的一些性能保证方面的内容。