说一段武林轶事先:某司业务系统在运行一段时间后越来越慢,越来越慢,越来越慢……..终于有一天慢到超时,惊动了领导。

经历了运维、开发两派“我方机器灯亮正常,必是尔等代码烂”以及“鄙人代码优雅美观,定是阁下机器功力不足”之战,最后双方发现慢在数据库上。
——于是第一次战争结束,大家开始了围绕数据库的第二次战争。
此战历时漫长,基本格调为:
运维:“贵派SQL语句写的烂怪我喽”
VS
开发:“明明是阁下内存给的少兼硬盘空间不足,呵~呵”

在双方堪堪就要表示“战汝娘亲”开启第三次战争之时,领导请来微软DB派高僧做调停。高僧收下N万香火钱,随手敲了几下键盘。说时迟那时快,只听“biu”的一声,系统它,它它它快了!在场诸侠目瞪狗呆!

大师拈花一笑:索引请了解一下。
高僧随人民币飘然而去,但是留下的话是如此深刻。所以本期我们要聊聊索引。索引此物在调优兵器榜中排名非常靠前(当然榜首必须还是“重启一指”),据说能化腐朽为神奇,轻松提高数据库性能,江湖上甚至有“一个索引拯救一个系统”的传言,一大帮DBA靠此物混的风声水起,并常常以此嘲讽码农,说若论起提速,“代码千行,不如索引一行”。
专制垄断是万恶的根源!不要以为索引是你们DB派独有的东西。SQL标准中可没有定义索引,索引只是加速检索的一种数据结构与算法结合物而已。
离了数据库,码农也能玩索引!为了证明此点,我们假设一个场景:
某份“巨硬”公司面试考题如下:
有这么一个Biger的大数组INT [100000000] ArrayData.,此数组为只读,里面存储了1亿个随机数字(不保证唯一哦)。
此数组上存在大量“找出数字K”的操作,问如何优化提速?
第一位少侠是这么回答的:
for (int i = 0; i < ArrayData.length; i++) {
if (ArrayData[i] == K)
System.out.println("使用遍历查找方式,找到:" + K);
}
这位少侠是这样出门的:

另一位少侠就很聪明了:“笨!二分法啊!”
恩,二分法是一个好主意。算法很简单,老夫偷懒直接从网上抄了一段代码(这段代码只为说明算法,没有考虑重复值问题):
int binarySerach(int[] array, int key) {
int left = 0; //初始化左下标位
int right = array.length - 1; //初始化右下标位
while (left <= right) {
int mid = (left + right) / 2; //中间位
if (array[mid] == key) { //Bingo!中间位击中!
return mid;
}
else if (array[mid] < key) { //如果中间位小于查找值,则下次从中间位的右边找
left = mid + 1;
}
else {
right = mid - 1; //如果中间位大于查找值,则下次从中间位的左边找
}
}
return -1; //没找到
}
比起第一位少侠的遍历大法,二分查找的性能简直是鹤立鸡群,卓尔不凡。

但是少侠莫要得意。面试官带着蜜汁微笑问你:“有没有更好的算法?”

我们知道,面试官的笑容=奸诈。所以我们要想想,二分法是否有不足之处?
在这个算法中,如果把排序好的数字看过看作一串珠子,固定好每一个“中间位”,把这串珠子拎起来——喔唷,二叉树。
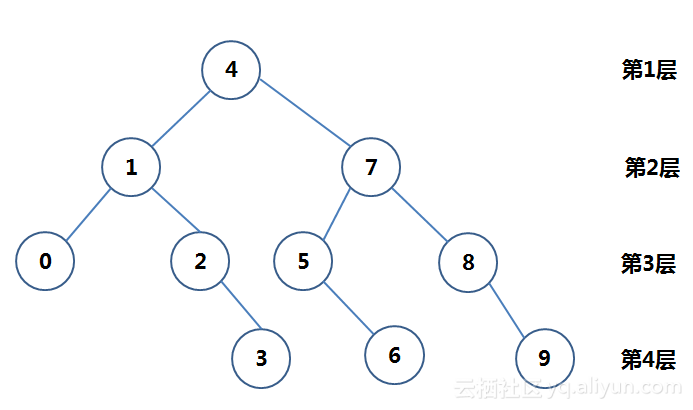
变成二叉树后,一眼就看出问题了——在二叉树中查找数值经过层数是不稳定的。看图中,找1只要到第2层,而找6需要深入到第4层。
有没有更好的办法?有。B+树可以解决二分法性能不稳定的问题,在B+树中,查找任何数经过的层级都是一致的。
啊,少侠们千万不要因为这货叫“B+”而以为它B格很高。本系列讲究的可是“一拳撂倒”。在此咩叔秉承一贯清新脱俗的风格,用一张图揭了B+树的老底。
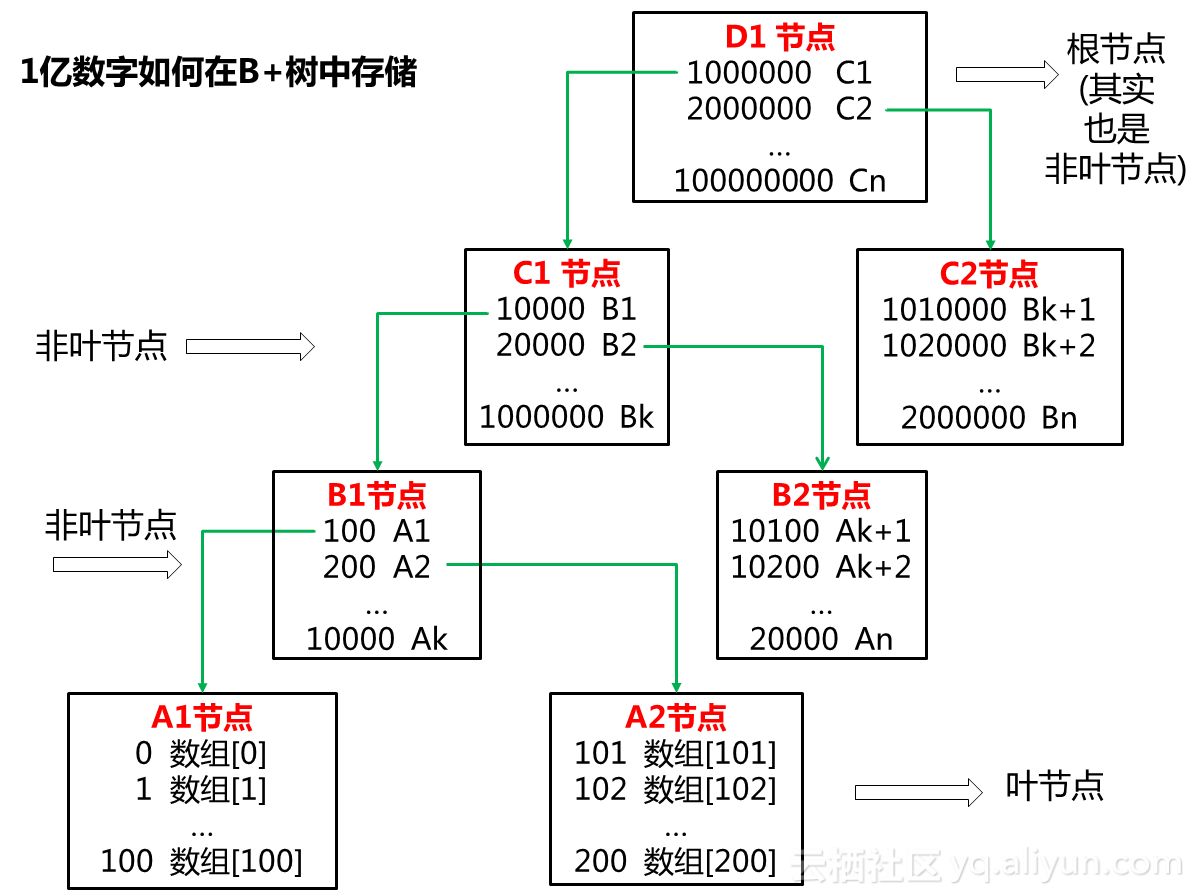
千万不要被这些框框线线给唬住,俗话说“假传千万卷,真传一张纸”,看老夫点出诀窍:
1、B+树中的节点存储的都是一条条的“记录”。
2、B+树中只有两种节点:叶子和非叶子。最下面那层是叶子,上面的都是非叶子。
3、叶子中的“记录”存的是排序过的数据,非叶子存的都是数据范围指向。
嗯,说完,收功。这么简单的东西,相信少侠都明白了,本期结束。

…想不到少侠们如此热情,待老夫爬起来继续……
其实,B+树的精髓很简单,只有叶子层中存放的是真正的数据(当然,是已排序的,记住,排序和归类一直是查找的好搭档)。非叶子层中存放的是一条条的“范围指针”。我们分别说明一下:
首先看看非叶子节点。
本例中我们摘出根节点(记住根节点其实也是一个非叶子结点):
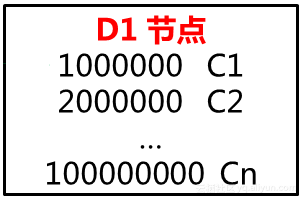
看第一行 1000000 C1
意思就是“如果要寻找<=1000000”的值,请询问C1节点。
再看一下叶子节点:
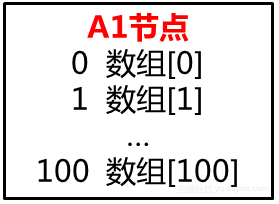
(注意看,这个节点中的数字是已经排序过的哦)
看第一行 0 数组[0] 意思就是 数字0,在原数组位置中是[0]。
这里要说明的是,记下数据的原始位置“数组[0]”可不是B+树的规定。只是因为实际情况:
1、大多数场景下,索引不应该干涉原始数据,它只是原始数据的一份可检索副本。(这个大家都能理解,目录只是内容的归纳,不应该影响内容,对吧)
2、很多时候还需要回归到原始数据中寻找。举个例子:
SELECT 列1 FROM TABLE_1 WHERE 列2=1
从[列2]上的索引可以找到[列2=1]的记录地址,而[列1]数据还需凭地址信息到原始数据中查找。
好,说完节点数据结构,我们看查询算法。现在假设我们要找数字8,整个算法流程是这样的,看图:
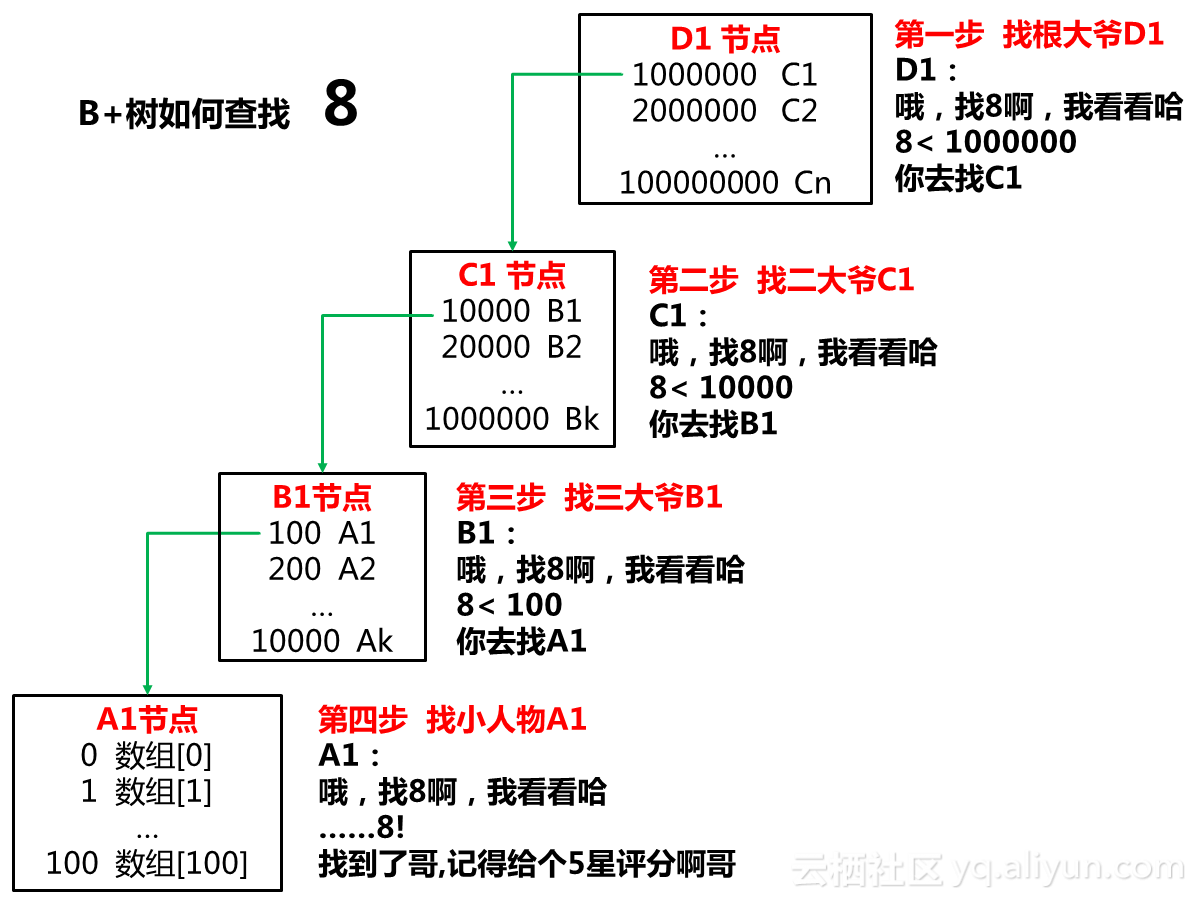
这张图看完,想必作为一名中国人,此时应该会心一笑:呦嗬,不就是一级管一级么,老祖宗留下的玩意儿!好使!
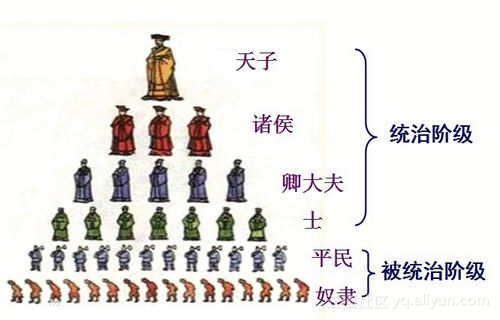
看看,所谓B+树,中国人5个字就说明了:“一级管一级”。所以咩叔一直说,世界上的东西,道理都是通的,别以为阿尔法贝塔就高高在上不食人间烟火。
B+树的基本原理就这么的讲完了。有了基本原理,接下来就是1生2,2生3,3生万物了。好比棍子加个尖就产生了矛,这世上有了一个好东西,就会随之出现各种魔改。B+树自然也有各种加强版,其中最普遍的一种改装就是“叶子节点串链子”:
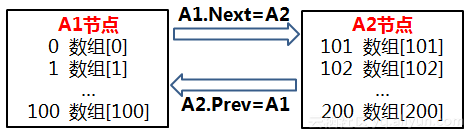
通过把叶子节点串成一个双向链表,可以轻松解决“找出>n的数”问题。
有兴趣的少侠们可以再想想如何魔改。不过这不是本文主要内容,知晓一下就好。咩叔还是强调:任何事物,最重要的是知晓核心理论,理论明白,剩下的都是能发展出来的。
理论讲好。少侠们都是热血方刚的人物,咱们是不是应该挽起袖子撸一把代码了?

万物都是类,咱们这次就写一个Index类。先画个图说明这个类的定义。
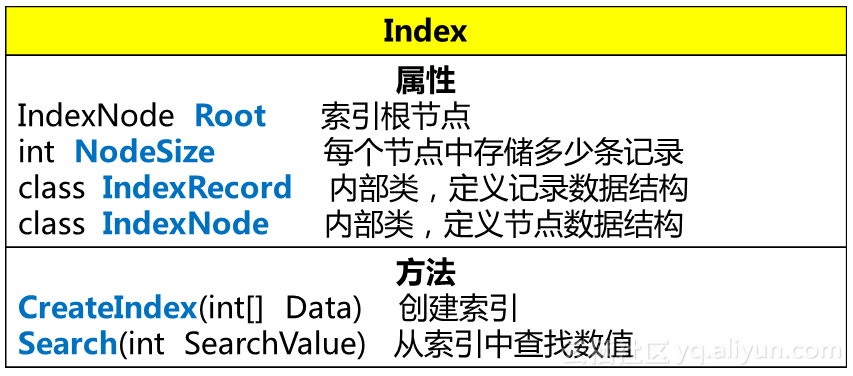
好,接下去上代码。
属性的定义最简单,几行搞定:
private class IndexRecord {
int DataValue;
int DataAddress;
IndexNode SubordinateNode; }
private class IndexNode {
int NodeLevel;
IndexNode LeftBrother;
IndexNode RightBrother;
int MaxDataValue;
ArrayList<IndexRecord> IndexRecords = new ArrayList<>(NodeSize);
}
private IndexNode Root = null;
private final int NodeSize = 100;
Root这个属性很好理解,每个索引都需要一个根节点。NodeSize也很好理解,节点总归要有一个存储大小对吧(大小不同性能会有不同哦,少侠可以做实验验证)。这里重点说明一下IndexRecord、IndexNode两个内部类的定义。
需要说明的是,IndexNode类中,LeftBrother和RightBrother是“叶子节点串链子”魔改中的双向链属性。
接下去讲重点:CreateIndex方法。在这个方法中,主要说明一下如何使用“砌墙法”创建索引。此法是咩叔在工地上搬砖3日后悟出,当初还想着如此清新脱俗接地气的招式,想必能助老夫行走江湖装个那啥。后来看MySQL资料,发现这货建索引也用了类似方法——咦,难道老外也搬过砖?
为缅怀那段搬砖的时光,咩叔这次决定用唱的:
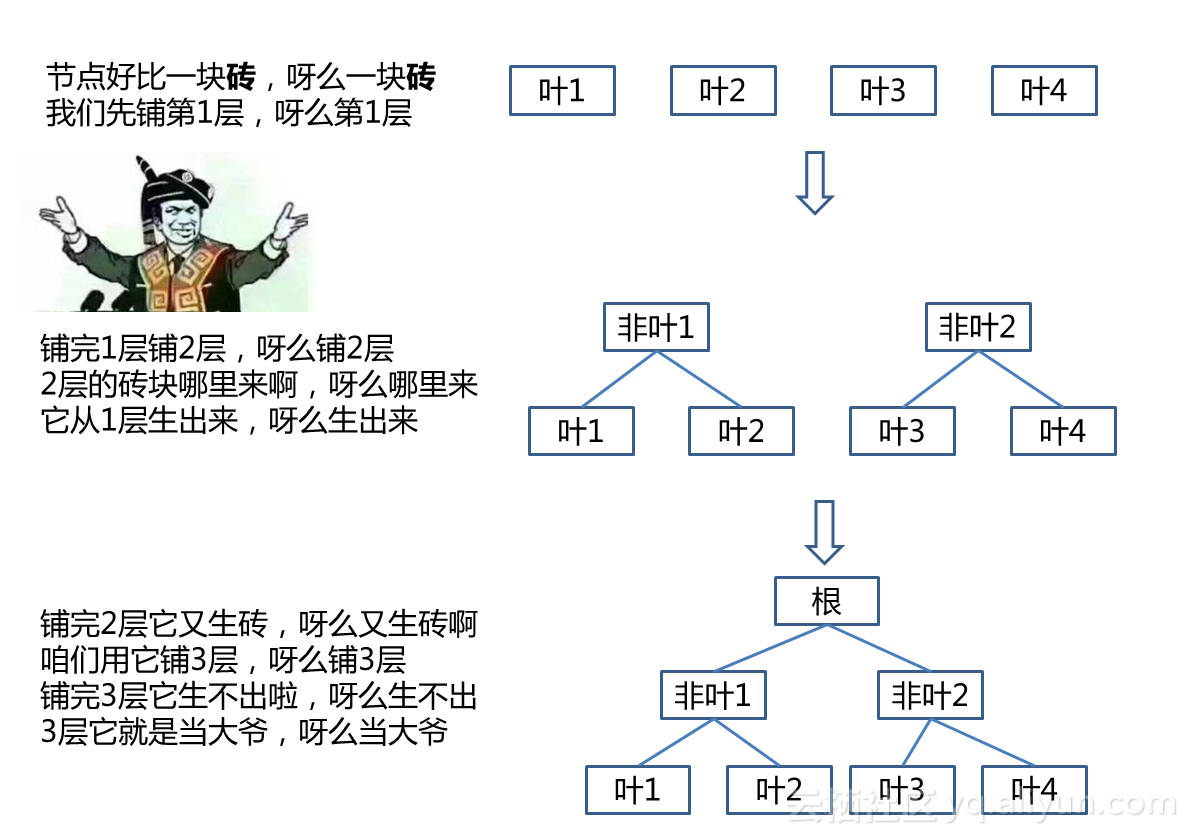
一曲山歌唱罢,少侠明白罢?叶子节点是数据副本,无论如何这层砖是必然存在的。而从下层节点中归纳总结的数据记录就生成了非叶子砖。这么一层砖铺完,再把新生出的记录再做成砖,再铺一层……直到最后一块砖铺完,就能收工回家啦。
CreateIndex方法代码约80行。为避免干扰思路,此处写上伪代码简单描述流程,完整代码附在文章末尾。
Public void CreateIndex(int[] Data)
{
1、Data数组中数据copy到数据副本 IndexRecords中
2、对IndexRecords中记录进行排序
3、使用砌墙法对IndexRecords中记录建立索引
4、设Index类中属性Root = 索引根节点
}
接下去是Search方法,约40行代码,逻辑相对来说简单了,咩叔的注释写的很详细,直接贴上来吧,各位一看便知:
public void Search(int SearchValue) { // 索引查找方法
if (Root == null) {
System.out.println("木有索引,不能搜索");
return;
}
IndexNode SearchNode = Root; // 从索引根节点开始查找
System.out.println("索引搜索开始...");
// 在非叶子节点中做范围定位,找到SearchValue所在的起始叶子Node
while (SearchNode.NodeLevel != 1) { // 在非叶子中定位,直到找到第一个叶子
System.out.println("非叶子页 NodeLevel:" + SearchNode.NodeLevel + " 页中MaxDataValue:" + SearchNode.MaxDataValue
+ " 此页中包含 " + SearchNode.IndexRecords.size() + " 条记录");
if (SearchNode.MaxDataValue < SearchValue) {
System.out.println("查找值大于索引边界,无结果,返回");
break;
}
for (IndexRecord record : SearchNode.IndexRecords) {
if (SearchValue <= record.DataValue) { // 在非叶子节点,DataValue是所管理下级中最大值。设搜索值为8,DataValue为100,则说明搜索值在此条记录范围内
SearchNode = record.SubordinateNode; // 既然搜索值在此条记录范围内,则直接指向下级节点,去下级节点找吧
break; // 搜索范围既然找到了,那就不用惊动别的大爷啦,直接退出
}
}
}
// 然后从定位到的叶子节点一路扫描,找出SearchValue
while (SearchNode != null) {
if (SearchValue > SearchNode.MaxDataValue) {
return; // 如果查询值已经大于节点中记录的最大值,则不用再找了
}
for (IndexRecord record : SearchNode.IndexRecords) {
if (record.DataValue > SearchValue) {
return; // 在叶子记录中找到值大于寻找值,则不用再找了
}
if (record.DataValue == SearchValue) {
System.out.println("叶子页 NodeLevel:" + SearchNode.NodeLevel + " 页中MaxDataValue:"
+ SearchNode.MaxDataValue + " 此页中包含 " + SearchNode.IndexRecords.size() + " 条记录\n" + "找到查询值:"
+ record.DataValue + " 该值在原始数据中的位置:" + record.DataAddress);
}
}
SearchNode = SearchNode.RightBrother; // 你看,这里就用到链表了,顺着链条一路扫下去吧少年!
}
}
至此,Index类编写完成,代码量为160行(事实上还能精简掉很多打印信息代码)。怎么样,简单吧?
我们尝试调用一下
int[] Data = new int[100000000]; //生成测试数据
for (int i = 0; i < Data.length; i++) {
Data[i] = i;
}
Index index = new Index(Data); //生成索引
index.Search(99999998); //找99999998
以下是格式化后的输出内容:

真功夫不能光吆喝,接下去,我们对比一下“遍历查找”与“索引查找”的速度。方法很简单,双方各跑100次,对比消耗时间即可。在咩叔i3CPU破台式机上,遍历查找耗时21672ms,而索引查找耗时24ms。看图比较直观:
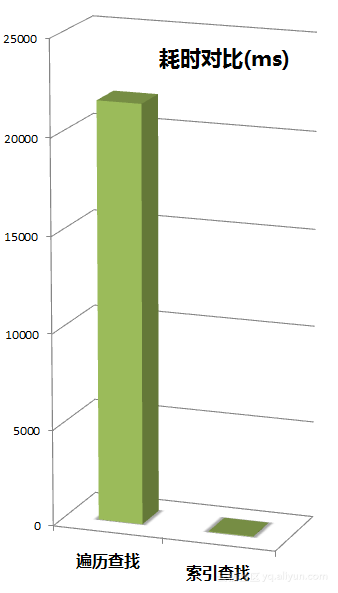
纸上得来终觉浅,绝知此事要躬行。自己动手撸一把码后,是不是觉得之前觉得神秘的事情现在变简单了?
本期简单介绍一下B+树索引的原理,索引算法也并不只有B+树一种(只是因为这货太好使了,所以大多数数据库系统都采用了)。在咩叔心中,所谓索引只是加速检索的一种数据结构与算法结合物而已。 还是那句话:任何事物,最重要的是知晓核心理论,理论明白,剩下的都是能发展出来的。
若是各位少侠在知晓B+树索引原理后深入研究一番,此后DB派的索引大法在各位面前就不过如此了。
最后安利一本内功心法《数据库系统实现》,此书是数据库实现方面内容最为全面的著作之一。相信叔,看完之后必定内力大增。

补充说明:
文章发出,有同学就把代码copy下来直接跑,然后死机了。
注意注意,你的JVM虚拟机一定要调整一下内存,一定要调整内存,一定要调整内存~~~
仔细看入口代码中的注释,-Xms -Xmx参数一定要调整好,这可是一亿的bigger数组啊同学
附上代码:
Index类
public class Index {
private IndexNode Root = null; // 索引根节点
private final int NodeSize = 100; // 一个节点能存储多少行记录
private class IndexRecord { // 索引记录
int DataValue; // 在叶子节点,存储真正的数值,在非叶子节点,则存储所管理下级中最大值
int DataAddress; // 叶子节点专用,存储数值在原始数组中的地址
IndexNode SubordinateNode; // 非叶子节点专用,存储下级节点的地址
}
private class IndexNode { // 索引节点
int NodeLevel; // 节点所在层级。叶节点是最底层,从1开始计数
IndexNode LeftBrother; // 左兄弟节点(只有叶子节点才需要),在本例中没有用到,只是作为演示用
IndexNode RightBrother; // 右兄弟节点(只有叶子节点才需要)
int MaxDataValue; // 本节点中管理的最大数值
ArrayList<IndexRecord> IndexRecords = new ArrayList<>(NodeSize); // 存放索引记录
}
public Index(int[] Data) {
CreateIndex(Data); // 构造时即创造索引
}
public void CreateIndex(int[] Data) { // 建立索引方法
if (Data.length < 1 || NodeSize < 2) { // 如果NodeSize<2,则索引的建立将成为一个死循环
System.out.println("数组中必须有值,NodeSize必须大于1");
return;
}
long startTime, endTime; // 时间计数器
System.out.println("开始创建索引...");
// 从原始数据中copy出一个数据副本
ArrayList<IndexRecord> IndexRecords = new ArrayList<>(Data.length);
startTime = System.currentTimeMillis(); // 记下执行开始时间
for (int i = 0; i < Data.length; i++) {
IndexRecord indexRecord = new IndexRecord();
indexRecord.DataValue = Data[i];
indexRecord.DataAddress = i;
IndexRecords.add(indexRecord);
}
endTime = System.currentTimeMillis(); // 结束时间
System.out.println("数据副本填充完成,耗时: " + (endTime - startTime) + "ms");
// 对副本中数据进行排序
startTime = System.currentTimeMillis(); // 记下执行开始时间
IndexRecords.sort(new Comparator<IndexRecord>() {
@Override
public int compare(IndexRecord R1, IndexRecord R2) {
if (R1.DataValue > R2.DataValue)
return 1;
else
return -1;
}
});
endTime = System.currentTimeMillis(); // 结束时间
System.out.println("排序完成,耗时: " + (endTime - startTime) + "ms");
// 开始砌墙建索引
startTime = System.currentTimeMillis(); // 记下执行开始时间
int NodeLevel = 1; // 初始化“节点层级”计数器
ArrayList<IndexNode> NodeList = new ArrayList<>(); // Node列表,记录下创建的Node,作为下层砖的原料
while (NodeLevel <= 1 || (IndexRecords.size() > 1 && NodeLevel > 1)) {
NodeList = new ArrayList<>(); // 清空
// 计算需要多少个Node来填充数据
int NodeNumber = (IndexRecords.size() / NodeSize) + (IndexRecords.size() % NodeSize != 0 ? 1 : 0);
for (int i = 0; i < NodeNumber; i++) { // 开始生成Node,并往Node中填数据
IndexNode indexNode = new IndexNode();
indexNode.NodeLevel = NodeLevel;
for (int j = 0; j < (IndexRecords.size() - (i * NodeSize) > NodeSize ? NodeSize
: IndexRecords.size() - (i * NodeSize)); j++) {
indexNode.MaxDataValue = IndexRecords.get(i * NodeSize + j).DataValue;
indexNode.IndexRecords.add(IndexRecords.get(i * NodeSize + j));
}
NodeList.add(indexNode); // 往Node列表中添加记录
}
if (NodeLevel == 1) { // 如果是叶子节点,则需要左右兄弟节点以形成双向链表
for (int i = 0; i < NodeNumber; i++) {
NodeList.get(i).LeftBrother = (i == 0 ? null : NodeList.get(i - 1));
NodeList.get(i).RightBrother = (i == NodeNumber - 1 ? null : NodeList.get(i + 1));
}
}
// 这一层的砖砌完了,把Node列表中的数据作为下一层砖的原料
IndexRecords = new ArrayList<>(); // 清空IndexRecords
for (IndexNode node : NodeList) {
IndexRecord Record = new IndexRecord();
Record.DataValue = node.MaxDataValue;
Record.SubordinateNode = node; // 非叶子节点,就需要记录叶子节点的SubordinateNode了
IndexRecords.add(Record);
}
NodeLevel = NodeLevel + 1; // “节点层级”计数器+1
}
if (NodeLevel == 2 && IndexRecords.size() == 1) { // 这是应对“叶子节点”只有1个的情况,此时新砖原料不足,需要手工给它建立一个上级节点
IndexNode RootNode = new IndexNode();
RootNode.MaxDataValue = IndexRecords.get(0).DataValue;
RootNode.IndexRecords.add(IndexRecords.get(0));
RootNode.NodeLevel = 2;
Root = RootNode;
} else {
Root = IndexRecords.get(0).SubordinateNode; // 记录根节点地址
}
endTime = System.currentTimeMillis(); // 结束时间
System.out.println("砌墙完成,耗时: " + (endTime - startTime) + "ms\n索引建立完毕\n");
}
public void Search(int SearchValue) { // 索引查找方法
if (Root == null) {
System.out.println("木有索引,不能搜索");
return;
}
IndexNode SearchNode = Root; // 从索引根节点开始查找
System.out.println("索引搜索开始...");
// 在非叶子节点中做范围定位,找到SearchValue所在的起始叶子Node
while (SearchNode.NodeLevel != 1) { // 在非叶子中定位,直到找到第一个叶子
System.out.println("非叶子页 NodeLevel:" + SearchNode.NodeLevel + " 页中MaxDataValue:" + SearchNode.MaxDataValue
+ " 此页中包含 " + SearchNode.IndexRecords.size() + " 条记录");
if (SearchNode.MaxDataValue < SearchValue) {
System.out.println("查找值大于索引边界,无结果,返回");
break;
}
for (IndexRecord record : SearchNode.IndexRecords) {
if (SearchValue <= record.DataValue) { // 在非叶子节点,DataValue是所管理下级中最大值。设搜索值为8,DataValue为100,则说明搜索值在此条记录范围内
SearchNode = record.SubordinateNode; // 既然搜索值在此条记录范围内,则直接指向下级节点,去下级节点找吧
break; // 搜索范围既然找到了,那就不用惊动别的大爷啦,直接退出
}
}
}
// 然后从定位到的叶子节点一路扫描,找出SearchValue
while (SearchNode != null) {
if (SearchValue > SearchNode.MaxDataValue) {
return; // 如果查询值已经大于节点中记录的最大值,则不用再找了
}
for (IndexRecord record : SearchNode.IndexRecords) {
if (record.DataValue > SearchValue) {
return; // 在叶子记录中找到值大于寻找值,则不用再找了
}
if (record.DataValue == SearchValue) {
System.out.println("叶子页 NodeLevel:" + SearchNode.NodeLevel + " 页中MaxDataValue:"
+ SearchNode.MaxDataValue + " 此页中包含 " + SearchNode.IndexRecords.size() + " 条记录\n" + "找到查询值:"
+ record.DataValue + " 该值在原始数组中的位置:" + record.DataAddress);
}
}
SearchNode = SearchNode.RightBrother; // 你看,这里就用到链表了,顺着链条一路扫下去吧少年!
}
}
}
程序运行入口
public class Run {
static long startTime, endTime; //统计耗时用
static int[] Data = new int[100000000]; // 注意虚拟机内存多填写一点 在我的环境中虚拟机内存参数设置为
// "-Xms8192m -Xmx10240m"
public static void main(String[] args) {
for (int i = 0; i < Data.length; i++) { // 生成测试数据
Data[i] = i;
}
Index index = new Index(Data); // 生成索引
FullScan(99999998, 100); //遍历查找100次呀么100次
IndexSearch(index, 99999998, 100); //索引查找100次呀么100次
}
public static void FullScan(int SearchValue, int Repeat) { // 遍历查找
startTime = System.currentTimeMillis(); // 执行开始时间
for (int r = 0; r < Repeat; r++) {
for (int i = 0; i < Data.length; i++) {
if (Data[i] == SearchValue)
System.out.println("使用遍历查找方式,找到:" + SearchValue);
}
}
endTime = System.currentTimeMillis(); // 结束时间
System.out.println("遍历查找" + Repeat + "次,运行时间: " + (endTime - startTime) + "ms\n");
}
public static void IndexSearch(Index index, int SearchValue, int Repeat) { // 索引查找
startTime = System.currentTimeMillis(); // 执行开始时间
for (int r = 0; r < Repeat; r++) {
index.Search(SearchValue);
}
endTime = System.currentTimeMillis(); // 结束时间
System.out.println("索引查找" + Repeat + "次,运行时间: " + (endTime - startTime) + "ms\n");
}
}
