前言
TableStore是阿里云自研首款分布式多模型数据库,属于NoSQL的类别。提到NoSQL数据库,现在对很多应用研发来说都已经不再陌生。当前很多应用系统底层不会再仅仅依赖于关系型数据库,而是会根据不同的业务场景,来选型使用不同类型的数据库,例如缓存型KeyValue数据会存储在Redis,文档型数据会存储在MongoDB,图数据会存储在Neo4J等。
回顾下NoSQL的发展历程,NoSQL诞生于Web 2.0时代,互联网高速发展的一个时代,也带来了一次互联网数据的爆发。传统的关系型数据库很难承载如此海量的数据,需要一种具备高扩展能力的分布式数据库。但基于传统的关系数据模型,去实现高可用和可扩展的分布式数据库是非常有挑战的一件事。互联网上大部分数据的数据模型很简单,没必要一概用关系模型来建模。如果能打破关系模型以一种更简单的数据模型来对数据建模、弱化事务和约束、以高可用和可扩展为目标,以此为目标设计的数据库能更好的满足业务需求,正是基于此种理念推动了NoSQL的发展。

总结下,NoSQL的发展是基于互联网时代对业务的新挑战以及数据库的新需求而推动的,基于此发展起来的NoSQL,有其显著的特征:
-
多数据模型:为满足不同数据的需求,诞生出了很多不同的数据模型,例如KeyValue、Document、Wide Column、Graph以及Time Series等。这是NoSQL数据库发展的一个最显著特征,打破了关系模型的约束,选择一个多元的发展方向。数据模型的选择是更加场景化的,更贴近业务的实际需求,能够做更深层次的优化。
-
高并发、低延迟:NoSQL数据库的发展更多由在线业务的需求推动,其设计目标更多的是面向在线业务提供高并发、低延迟的访问。
-
高可扩展:为应对爆发的数据量增长,可扩展是最核心的设计目标之一,所以底层架构往往在设计之初即考虑分布式架构。
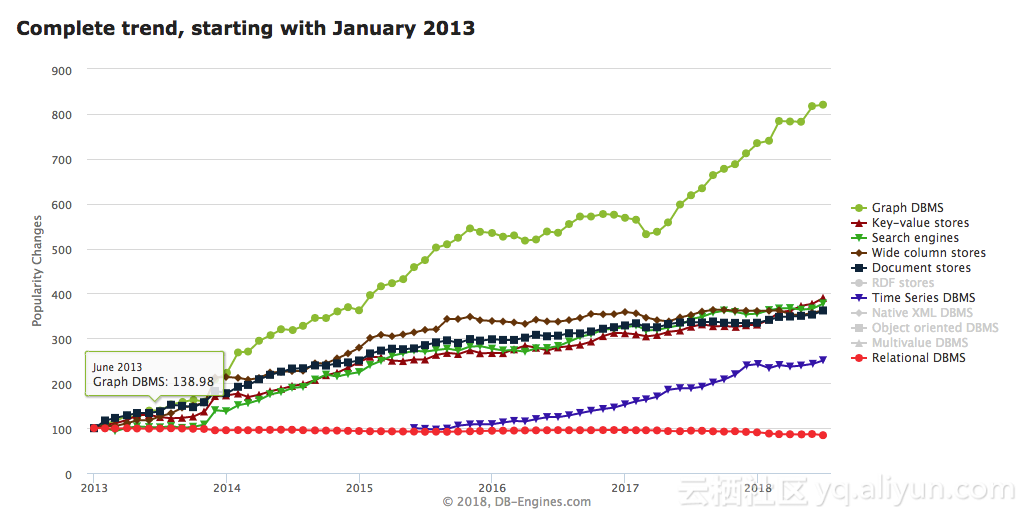
从DBEngines的发展趋势统计上也可以看到,各类NoSQL数据库在近几年都是处于一个蓬勃发展的状态。阿里云TableStore作为一款分布式NoSQL数据库,在数据模型上选择了多模型的架构,同时支持WideColumn和Timeline。
WideColumn模型是由Bigtable提出,后被其他同类型系统广泛应用的一种经典模型,目前世界上的绝大部分半结构化、结构化数据都是存储在该模型系统中。除了WideColumn模型外,我们推出了另一种全新的数据模型:Timeline,Timeline模型是一种用于消息数据的新一代模型,适用于IM、Feeds和物联网设备消息下推等消息系统中消息的存储和同步,目前已经开始被广泛使用。接下来,我们详细了解下这两种模型。
Wide Column模型
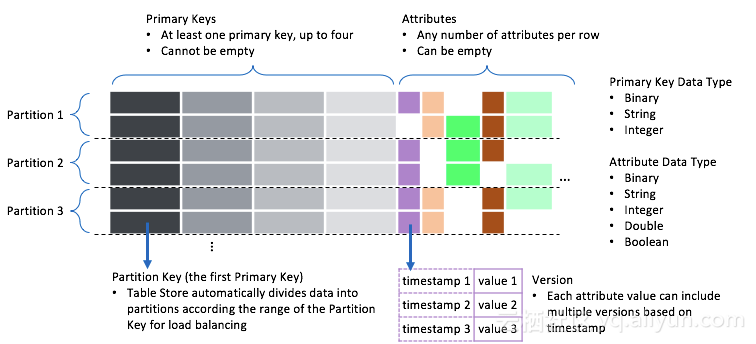
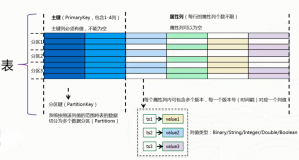
上图是Wide Column模型的一个模型图,为更好的理解这个模型,我们拿关系模型来做一个对比。关系模型可以简单的理解为一个二维的模型,由行列组成,每一行的列固定Schema。所以关系模型的特征是:二维以及固定Schema,这是一个最简单的理解,抛开事务和约束来看的话。Wide Column模型是一个三维的模型,在行与列二维的基础上,增加了一个时间维度。时间维度体现在属性列上,属性列可以拥有多个值,每个值对应一个Timestamp作为版本。并且每一行是Schema Free的,没有强Schema定义。所以Wide Column模型对比关系模型,简单总结就是:三维、Schema Free、简化事务和约束。
再详细看下这个模型的组成,有几个主要部分:
-
主键(Primary Key):每一行都会有主键,主键会由多列(1-4列)构成,主键的定义是固定Schema,主键的作用主要是唯一区分一行数据。
-
分区键(Partition Key):主键的第一列称为分区键,分区键用于对表进行范围分区,每个分区会分布式的调度到不同的机器上进行服务。在同一个分区键内,我们提供跨行事务。
-
属性列(Attribute Column):一行中除开主键列外,其余都是属性列。属性列会对应多个值,不同值对应不同的版本,一行可存储不限个数个属性列。
-
版本(Version):每一个值对应不同的版本,版本的值是一个时间戳,用于定义数据的生命周期。
-
数据类型(Data Type):TableStore支持多种数据类型,包含String、Binary、Double、Integer和Boolean。
-
生命周期(Time To Live):每个表可定义数据生命周期,例如生命周期配置为一个月,则该表数据中在一个月之前写入的数据就会被自动清理。数据的写入时间由版本来决定,版本一般由服务端在数据写入时根据服务器时间来定,也可由应用自己指定。
-
最大版本数(MaxVersion):每个表可定义每一列最多保存的版本数,用于控制一列的版本的个数,老版本的超过个数上限的数据会被自动清理。
Wide Column模型的特色,总结来说就是:三维结构(行、列和时间)、宽行、多版本数据以及生命周期管理。同时Wide Column模型在数据操作层面,提供两类数据访问API,Data API和Stream API。
Data API
关于Data API的详细文档请参考
这里,Data API是标准的数据API,提供数据的在线读写,包括:
-
PutRow:新插入一行,如果存在相同行,则覆盖。
-
UpdateRow:更新一行,可增加、删除一行中的属性列,或者更新已经存在的属性列的值。如果该行不存在,则新插入一行。
-
DeleteRow:删除一行。
-
BatchWriteRow:批量更新多张表的多行数据,可组合PutRow、UpdateRow和DeleteRow。
-
GetRow:读取一行数据。
-
GetRange:范围扫描数据,可正序扫描或者逆序扫描。
-
BatchGetRow:批量查询多张表的多行数据。
Stream API
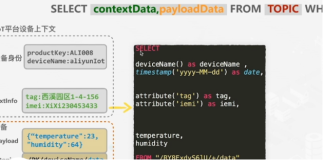
在关系模型数据库中是没有对数据库内增量数据定义标准API的,但是在传统关系数据库的很多应用场景中,增量数据(binlog)的用途是不可忽视的。这个在阿里内部场景中,有很广泛的应用,并且提供了DRC这类中间件将这部分数据的能力完全挖掘了出来。将增量数据的能力挖掘出来后,我们可以在技术架构上做很多事:
-
异构数据源复制:MySQL数据增量同步到NoSQL,做一个冷数据存储。
-
对接流计算:可实时对MySQL内数据做统计,做一些大屏类应用。
-
对接搜索系统:可将搜索系统扩展为MySQL的二级索引,增强MySQL内数据的检索能力。
但即使关系数据库的增量数据如此有用,业界也没有规范的API定义来获取这部分增量数据。TableStore是早早发觉了这部分数据存在的价值,提供了标准化的API来将这部分数据的能力开放出来,这就是我们的Stream API(
文档)。
Stream API大致包括:
-
ListStream:获取表的Stream,范围Stream的ID。
-
DescribeStream:获取Stream的详细信息,拉取Stream内Shard列表,以及Shard结构树。
-
GetShardIterator:获取Shard当前增量数据的Iterator。
-
GetStreamRecord:根据Shard Iterator获取Shard内的增量数据。
TableStore Stream的实现会比MySQL Binlog复杂很多,因为TableStore本身是一个分布式的架构,Stream也是一个分布式的增量数据消费框架。Stream的数据消费必须保序获取,Stream的Shard与TableStore内部的表的分区一一对应,表的分区会存在分裂和合并,为保证在分区分裂和合并后老Shard和新增Shard的数据消费仍然能保序,我们设计了一套比较精密的机制。对于TableStore Stream的设计,不在这里赘述,我们之后会发布更详细的设计文档。
当前由于Stream内部架构的复杂,将这部分复杂度也引入到了Stream数据消费侧,在用户使用Stream API时并不是那么简单。在今年我们也规划了一个全新的数据消费通道服务,来简化Stream数据的消费,提供更简单易用的API,尽情期待。
Timeline模型
Timeline模型是我们针对消息数据场景所新创的一个数据模型,它的特色在于能够满足消息数据场景对消息保序、海量消息存储、实时同步的特殊需求。
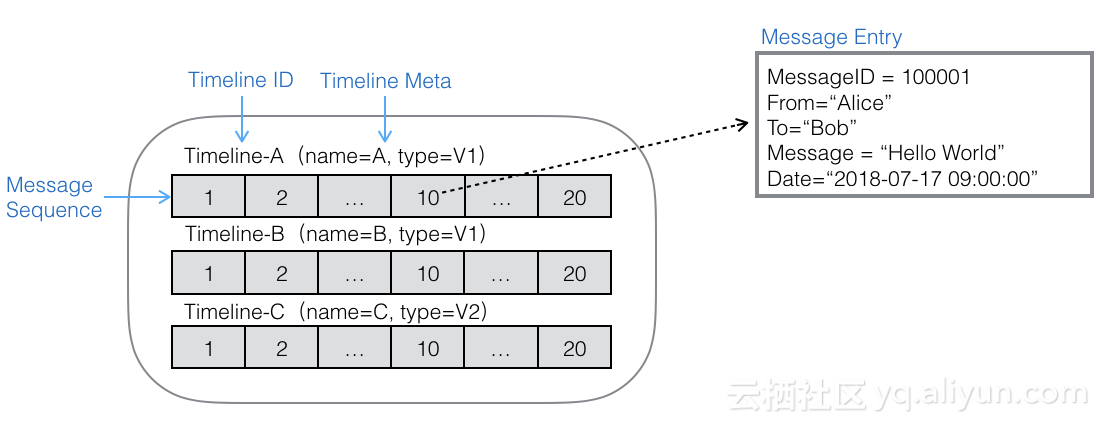
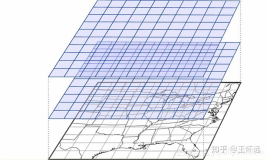
如上图是Timeline的模型图,将一张大表内的数据抽象为多个Timeline,一个大表能够承载的Timeline个数无上限。
Timeline的构成主要包括:
-
Timeline ID:唯一标识Timeline的ID。
-
Timeline Meta:Timeline的元数据,元数据内可包含任意键值对属性。
-
Message Sequence:消息队列,承载该Timeline下的所有消息。消息在队列里有序保存,并且根据写入顺序分配自增的ID。一个消息队列可承载的消息个数无上限,在消息队列内部可根据消息ID随机定位某条消息,并提供正序或者反序扫描。
-
Message Entry:消息体,包含消息的具体内容,可以包含任意键值对。
Timeline的模型逻辑上与消息队列有一些相似之处,Timeline类似于消息队列中的Topic。不同之处在于,TableStore Timeline更侧重Topic的规模。在即时通讯场景,每个用户的收件箱和寄件箱都是一个Topic,在物联网消息场景,每个设备对应一个Topic,Topic的量级会达到千万甚至亿级别。TableStore Timeline基于底层的分布式引擎,单表能支持理论无上限的Timeline(Topic),简化队列的Pub/Sub模型,支持消息保序、随机定位以及正反序扫描,更贴近即时通讯(IM)、Feeds流以及物联网消息系统等海量消息数据场景的需求。
关于Timeline模型的起源,可以看下这篇文章 - 《
现代IM系统中消息推送和存储架构的实现》,具体的应用可以参考下这篇文章 - 《
TableStore Timeline:轻松构建千万级IM和Feed流系统》。
Timeline是在去年新推出的一个数据模型,我们还在不断的打磨。基于这个模型,我们已经帮助钉钉、菜鸟智能客服、淘票票小聚场、智能设备管理等业务构建即时通讯、Feeds流、物联网等领域的消息系统,欢迎使用。
最后,欢迎加入我们的内部钉钉群(群号:11789671)进行交流。