分布式缓存Redis之Pipeline(管道)
写在前面
本学习教程所有示例代码见GitHub:https://github.com/selfconzrr/Redis_Learning
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现。 由于网络开销延迟,就算redis server端有很强的处理能力,也会由于收到的client消息少,而造成吞吐量小。当client 使用pipelining 发送命令时,redis server必须将部分请求放到队列中(使用内存),执行完毕后一次性发送结果;如果发送的命令很多的话,建议对返回的结果加标签,当然这也会增加使用的内存;
Pipeline在某些场景下非常有用,比如有多个command需要被“及时的”提交,而且他们对相应结果没有互相依赖,对结果响应也无需立即获得,那么pipeline就可以充当这种“批处理”的工具;而且在一定程度上,可以较大的提升性能,性能提升的原因主要是TCP连接中减少了“交互往返”的时间。
不过在编码时请注意,pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到pipeline关闭;如果你的pipeline的指令集很庞大,为了不干扰链接中的其他操作,你可以为pipeline操作新建Client链接,让pipeline和其他正常操作分离在2个client中。不过pipeline事实上所能容忍的操作个数,和socket-output缓冲区大小/返回结果的数据尺寸都有很大的关系;同时也意味着每个redis-server同时所能支撑的pipeline链接的个数,也是有限的,这将受限于server的物理内存或网络接口的缓冲能力。
(一)简介
Redis使用的是客户端-服务器(CS)模型和请求/响应协议的TCP服务器。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis客户端与Redis服务器之间使用TCP协议进行连接,一个客户端可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常会阻塞并等待redis服务器处理,redis处理完请求命令后会将结果通过响应报文返回给client,因此当执行多条命令的时候都需要等待上一条命令执行完毕才能执行。比如:
其执行过程如下图所示:
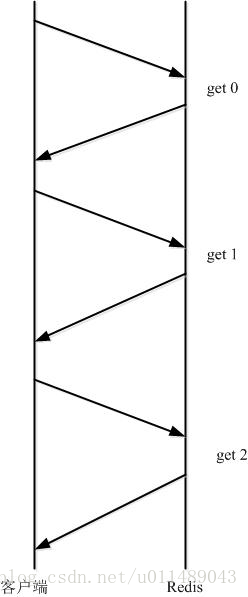
由于通信会有网络延迟,假如client和server之间的包传输时间需要0.125秒。那么上面的三个命令6个报文至少需要0.75秒才能完成。这样即使redis每秒能处理100个命令,而我们的client也只能一秒钟发出四个命令。这显然没有充分利用 redis的处理能力。
而管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline通过减少客户端与redis的通信次数来实现降低往返延时时间,而且Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。 Pipeline 的默认的同步的个数为53个,也就是说arges中累加到53条数据时会把数据提交。其过程如下图所示:client可以将三个命令放到一个tcp报文一起发送,server则可以将三条命令的处理结果放到一个tcp报文返回。
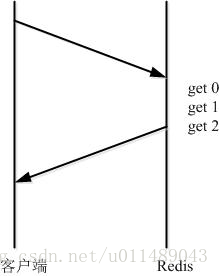
需要注意到是用 pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。
(二)比较普通模式与PipeLine模式
测试环境:
Windows:Eclipse + jedis2.9.0 + jdk 1.7
Ubuntu:部署在虚拟机上的服务器 Redis 3.0.7
/*
* 测试普通模式与PipeLine模式的效率:
* 测试方法:向redis中插入10000组数据
*/
public static void testPipeLineAndNormal(Jedis jedis)
throws InterruptedException {
Logger logger = Logger.getLogger("javasoft");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
jedis.set(String.valueOf(i), String.valueOf(i));
}
long end = System.currentTimeMillis();
logger.info("the jedis total time is:" + (end - start));
Pipeline pipe = jedis.pipelined();// 先创建一个pipeline的链接对象
long start_pipe = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
pipe.set(String.valueOf(i), String.valueOf(i));
}
pipe.sync();// 获取所有的response
long end_pipe = System.currentTimeMillis();
logger.info("the pipe total time is:" + (end_pipe - start_pipe));
BlockingQueue<String> logQueue = new LinkedBlockingQueue<String>();
long begin = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
logQueue.put("i=" + i);
}
long stop = System.currentTimeMillis();
logger.info("the BlockingQueue total time is:" + (stop - begin));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

从上述代码以及结果中可以明显的看到PipeLine在“批量处理”时的优势。
(三)适用场景
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进redis了,那这种场景就不适合。
还有的系统,可能是批量的将数据写入redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入redis,可能失败了2条无所谓,后期有补偿机制就行了,比如短信群发这种场景,如果一下群发10000条,按照第一种模式去实现,那这个请求过来,要很久才能给客户端响应,这个延迟就太长了,如果客户端请求设置了超时时间5秒,那肯定就抛出异常了,而且本身群发短信要求实时性也没那么高,这时候用pipeline最好了。
(四)管道(Pipelining) VS 脚本(Scripting)
大量 pipeline 应用场景可通过 Redis 脚本(Redis 版本 >= 2.6)得到更高效的处理,后者在服务器端执行大量工作。脚本的一大优势是可通过最小的延迟读写数据,让读、计算、写等操作变得非常快(pipeline 在这种情况下不能使用,因为客户端在写命令前需要读命令返回的结果)。
应用程序有时可能在 pipeline 中发送 EVAL 或 EVALSHA 命令。Redis 通过 SCRIPT LOAD 命令(保证 EVALSHA 成功被调用)明确支持这种情况。
(五)源码分析
关于Pipeline的源码分析 请看后续文章分析。
