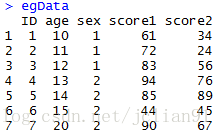
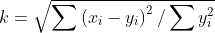本文的示例数据框集(egData)如下:
值标签:
if(FALSE){值标签,levels代表变量实际值,labels代表标签值}
egData$sex <- factor(egData$sex, levels = c(1,2),labels = c("male", "female"))
简单的数据处理函数:
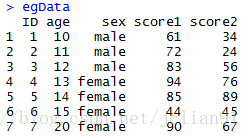
if(FALSE){显示对象中元素/成分的数量}
length(egData)
if(FALSE){显示对象的维度}
dim(egData)
if(FALSE){显示对象的结构}
str(egData)
if(FALSE){显示对象的类或类型}
class(egData)
if(FALSE){显示对象的模式}
mode(egData)
if(FALSE){显示对象中各成分的名称}
names(egData)
if(FALSE){列出对象的开始部分,一般前6行}
head(egData)
if(FALSE){列出对象的结束部分,一般最后6行}
tail(egData)
if(FALSE){编辑对象}
edit(egData)
if(FALSE){编辑对象,并保存}
egData <- edit(egData)
if(FALSE){编辑对象}
fix(egData)
if(FALSE){将对象并入一个向量}
x <- c(c(1,2,3), c(4,5,6))
if(FALSE){按列合并对象}
x <- rbind(c(1,2,3), c(4,5,6))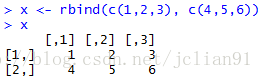
if(FALSE){按行合并对象}
x <- cbind(c(1,2,3), c(4,5,6))
if(FALSE){添加新变量}
egData$score3 <- c(55,78,90,NA,80,NA,67)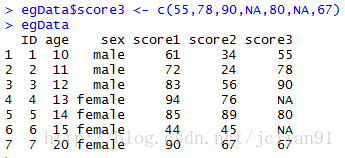
if(FALSE){算术运算符}
egData$total <- egData$score1+egData$score2+egData$score3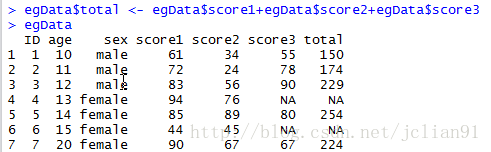
if(FALSE){逻辑运算符,对变量进行重编码}
egData$age[egData$age > 18] <- "Adult"
egData$age[egData$age >= 12 & egData$age <= 18] <- "Youth"
egData$age[egData$age < 12] <- "Kid"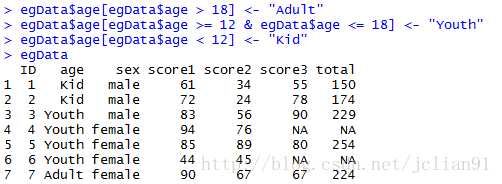
if(FALSE){变量重命名,方法1,交互式修改}
fix(egData)
if(FALSE){变量重命名,方法2,调用reshape包的rename方法}
install.packages("reshape")
library(reshape)
egData <- rename(egData, c(age="ageType"))
if(FALSE){变量重命名,方法3,利用names方法}
names(egData)[2] <- "ageType"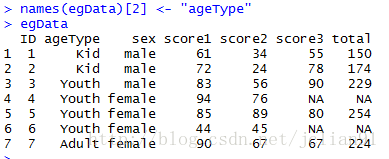
if(FALSE){缺失值}
if(FALSE){判断缺失值}
is.na(egData$total)
if(FALSE){排除缺失值}
sum(egData$total, na.rm = TRUE)
if(FALSE){删除缺失值}
x <- na.omit(egData)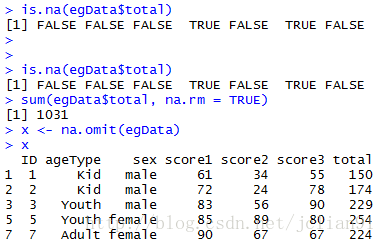
if(FALSE){日期函数}
if(FALSE){当天的日期}
Sys.Date()
if(FALSE){当前的日期和时间}
date()
if(FALSE){指定日期格式}
format(Sys.Date(), format='%B %d %Y')
if(FALSE){时间间隔}
difftime(Sys.Date(), as.Date('2016-12-03'), units = 'days')
if(FALSE){转化为日期格式}
egData$DATE <- as.Date(c('2016-01-01', '2016-02-01', '2016-03-01', '2016-04-01', '2016-05-01', '2016-06-01', '2016-07-01'))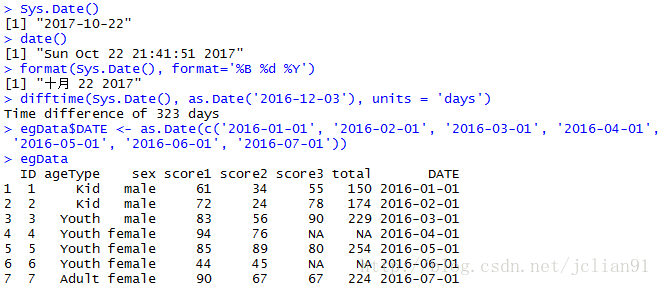
if(FALSE){类型判断函数:is.numeric(),is.character(),is.vector(),is.matrix(),is.data.frame(),is.factor(),is.logical()...
类型转化函数:as.numeric(),as.character(),as.vector(),as.matrix(),as.data.frame(),as.factor(),as.logical()...
}
is.numeric(c(1,2,3))
is.vector(c(1,2,3))
is.numeric(as.character(1))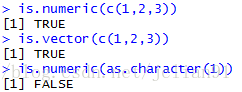
if(FALSE){数据排序,默认为升序,变量前面加-即为降序}
egData <- egData[order(egData$total, -egData$score1),]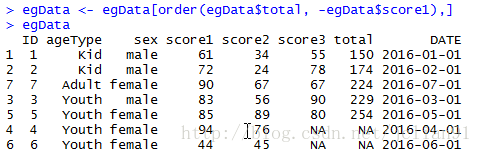
if(FALSE){数据集的合并}
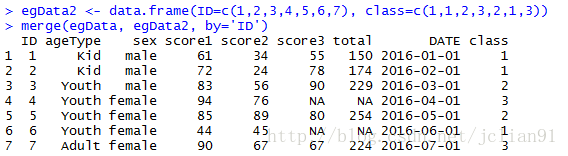
if(FALSE){横向合并数据框(数据集),merge()需要有共同变量,cbind()则不需要,已在上面代码展示过}
egData2 <- data.frame(ID=c(1,2,3,4,5,6,7), class=c(1,1,2,3,2,1,3))
x <- merge(egData, egData2, by='ID')
if(FALSE){纵向合并数据框(数据集),顺序不必一样,也可用于添加行,已在上面代码展示过}
if(FALSE){选入变量}
newdata1 <- egData[c("ID","sex","age")]
newdata2 <- egData[,c(1:5)]
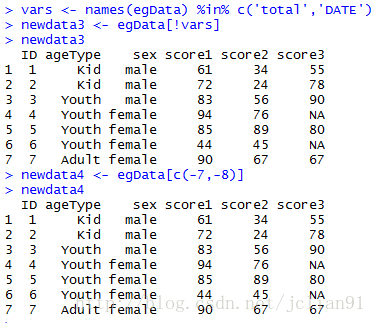
if(FALSE){删除变量}
vars <- names(egData) %in% c('total','DATE')
newdata3 <- egData[!vars]
newdata4 <- egData[c(-7,-8)]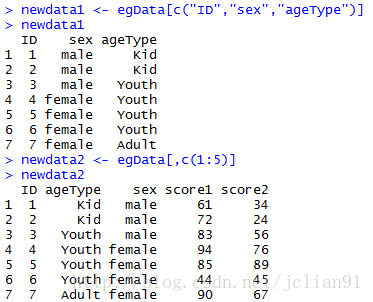
if(FALSE){选入行或列}
mydata1 <- egData[which(egData$score1 > 60 & egData$score2 < 80),]
mydata2 <- mydata1[,1:3]
if(FALSE){选入行或列,利用subset()函数}
mydata3 <- subset(egData, score1 > 60 & score2 < 80, select = c(1:3))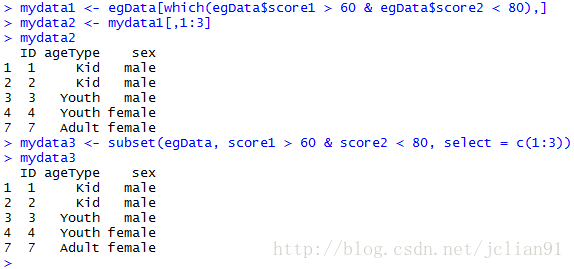
if(FALSE){随机抽样,sample()函数}
mysample <- egData[sample(1:nrow(egData), 3 , replace = FALSE),]
if(FALSE){利用SQL语句操作数据框,sqldf包}
library(sqldf)
mydata <- sqldf("SELECT ID, sex, ageType FROM egData WHERE score1 > 60
AND score2 < 80", row.names = TRUE)
print(mydata)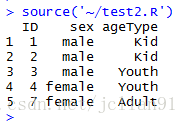
if(FALSE){数学函数}
if(FALSE){绝对值}
abs(-4)
if(FALSE){平方根}
sqrt(25)
if(FALSE){不小于x的最小整数,ceiling(x)}
ceiling(3.475)
if(FALSE){不大于x的最大整数,floor(x)}
floor(3.475)
if(FALSE){向0方向截取x中的整数部分,trunc(x)}
trunc(5.99)
if(FALSE){将x舍入为指定位数的小数,round(x)}
round(3.475, digits = 2)
if(FALSE){将x舍入为指定的有效数字位数,signif(x)}
signif(3.475, digits = 2)
if(FALSE){正弦sin(x),余弦cos(x),正切tan(x)}
cos(2)
if(FALSE){反正弦asin(x),反余弦acos(x),反正切atan(x)}
acos(-0.4161468)
if(FALSE){双曲正弦sinh(x),双曲余弦cosh(x),双曲正切tanh(x)}
sinh(2)
if(FALSE){反双曲正弦asinh(x),反双曲余弦acosh(x),反双曲正切atanh(x)}
asinh(3.62686)
if(FALSE){对x取以n为底的对数,log(x, base = n)}
log(8, base = 2)
if(FALSE){自然对数,log(x),常用对数,log10(x)}
log(10)
log10(10)
if(FALSE){指数函数,exp(x)}
exp(2.302585)
if(FALSE){将上述数学函数作用于数值向量、矩阵、数据框时,它们会独立地作用于每个值}
sqrt(c(4,9,16))
if(FALSE){统计函数}
if(FALSE){在考虑以下统计函数时,应考虑它们的可选参数,如na.rm等,可使用help()查看具体的函数使用}
z <- mean(c(1,2,3,4,5), trim = 0.5, na.rm = TRUE)
if(FALSE){平均数,mean(x)}
mean(c(1,2,3,4))
if(FALSE){中位数,median(x)}
median(c(1,2,3,4))
if(FALSE){标准差,sd(x)}
sd(c(1,2,3,4))
if(FALSE){方差,var(x)}
var(c(1,2,3,4))
if(FALSE){绝对中位差,mad(x)}
mad(c(1,2,3,4))
if(FALSE){绝对中位差,quantile(x,probs)}
quantile(c(1,2,3,4),c(0.25,0.5,0.75))
if(FALSE){值域,range(x)}
range(c(1,2,3,4))
if(FALSE){求和,sum(x)}
sum(c(1,2,3,4))
if(FALSE){滞后差分,diff(x,lag=n),lag用以指定滞后几项,默认的lag值为1}
diff(c(1,2,3,4))
if(FALSE){最小值}
min(c(1,2,3,4))
if(FALSE){最大值}
max(c(1,2,3,4))
if(FALSE){为数据对象x按列进行中心化(center = TRUE)或标准化(center = TRUE, scale = TRUE)}
scaledata <- scale(egData[,4:6], center = TRUE, scale = TRUE)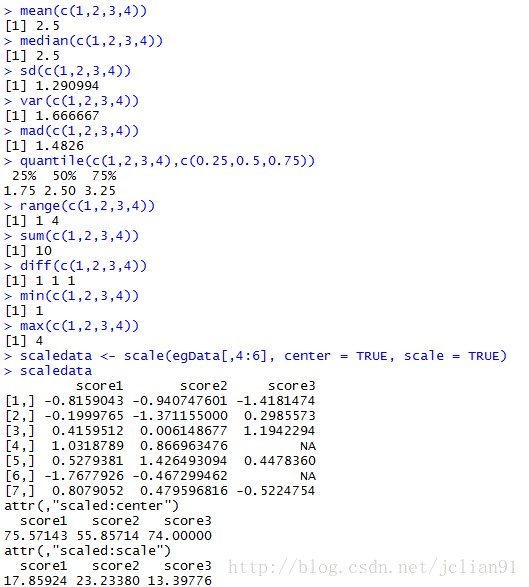
if(FALSE){概率函数}
if(FALSE){使用方法:[dqpr]distribution_abbreviation(),其中d为密度函数,p为分布函数,q为分位数函数,r为生成随机数,distribution_abbreviation()为概率分布缩写,详见下表}
if(FALSE){绘制标准正态曲线}
x <- pretty(c(-3,3),100)
y <- dnorm(x)
plot(x,y,type="l",xlab="NormalDevite",ylab="Density",yaxs="i")
if(FALSE){位于z=1.96左侧的标准正态曲线下方面积}
pnorm(1.96)
if(FALSE){均值为500,标准差为1000的正态分布的0.9分位点值}
qnorm(0.9, mean = 500, sd = 1000)
if(FALSE){生成50个均值为50,标准差为10的正态随机数}
rnorm(50, mean = 50, sd = 10)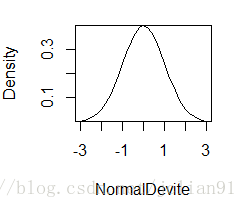
概率分布缩写表
| 分布名称 | 缩写 | 分布名称 | 缩写 |
|---|---|---|---|
| Beta分布 | beta | Logistic分布 | logis |
| 二项分布 | binom | 多项分布 | multinom |
| 柯西分布 | cauchy | 负二项分布 | nbinom |
| (非中心)卡方分布 | chisq | 正态分布 | norm |
| 指数分布 | exp | 泊松分布 | pois |
| F分布 | f | Wilcoxon符号秩分布 | signrank |
| Gamma分布 | gamma | t分布 | t |
| 几何分布 | geom | 均匀分布 | unif |
| 超几何分布 | hyper | Weibull分布 | weibull |
| 对数正态分布 | lnorm | Wilcoxon秩和分布 | wilcox |
if(FALSE){为生成随机数指定种子,便于结果重现}
set.seed(5)
runif(5)
set.seed(1234)
runif(5)
if(FALSE){利用MASS包的mvrnorm(n, mean, sigma)函数生成多元正态分布数据,其中n为样本大小,mean为均值向量,sigma为方差-协方差矩阵(或相关矩阵)}
library(MASS)
options(digits = 3)
set.seed(1234)
mean <- c(230.7, 146.7, 3.6)
sigma <- matrix(c(15360.8, 6712.2, -47.1, 6721.2, 4700.9, -16.5, -47.1, -16.5, 0.3), nrow = 3, ncol = 3)
mydata <- mvrnorm(500, mean, sigma)
mydata<- as.data.frame(mydata)
names(mydata) <- c('y','x1','x2')
dim(mydata)
> head(mydata, n = 8)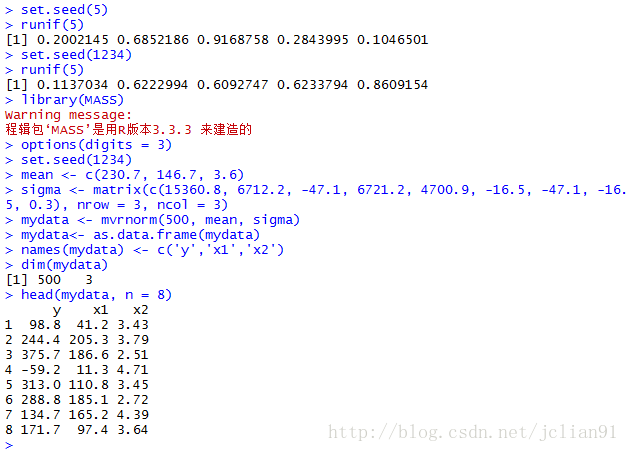
if(FALSE){字符处理函数}
if(FALSE){计算x中的字符数量,nchar(x)}
nchar(c('where','is','my','code'))
if(FALSE){提取或替换一个字符向量中的子串,substr(x, start, stop)}
x <- "abcdef"
substr(x,2,4)
substr(x,2,4) <- '2222'
if(FALSE){在x中搜索某种模式。grep(pattern, x, ignore.case = FALSE, fixed = FALSE),ignore.case表示是否忽略大小写。若fixed = FALSE,则pattern为一个正则表达式。若fixed = TRUE, 在pattern为一个文本字符串。返回值为匹配的下标}
grep("A", c("B","a","A","c"), ignore.case=FALSE, fixed=TRUE)
grep("^A", c("Bat","act","cow","AM"), ignore.case=FALSE, fixed=FALSE)
if(FALSE){在x中搜索pattern,并以文本replacement将其替换。若fixed =FALSE,则pattern为一个正则表达式。若fixed = TRUE, 在pattern为一个文本字符串。}
sub("\\s","...","Hello China!", fixed = FALSE)
if(FALSE){在split处分割字符向量x中的元素。strsplit(x, split, fixed=FALSE)若fixed =FALSE,则pattern为一个正则表达式。若fixed = TRUE, 在pattern为一个文本字符串。}
strsplit('I LIVE IN SHANGHAI!', ' ', fixed=TRUE)
if(FALSE){连接字符串,分隔符为sep。paste(...,sep=...)}
paste("x", 1:5, sep="")
paste("x", 1:5, sep="L")
paste("C","Window","Files",sep="/")
if(FALSE){全部转化为大写}
toupper("China")
if(FALSE){全部转化为小写}
tolower("China")
if(FALSE){其他实用函数}
if(FALSE){生成序列,seq(from, to, by),by为步长,默认为1}
seq(1,10)
seq(1,10,2)
if(FALSE){将x重复n次}
rep(1:3,2)
if(FALSE){将连续性变量分割为n个水平因子的变量,cut(x,n),使用选项ordered_result=TRUE可以创建有序性因子。}
cut(c(1,3,5,4,6),2)
cut(c(1,3,5,4,6),2,ordered_result = TRUE)
if(FALSE){pretty(x,n),通过选取n+1个等间距的取整值,将连续性变量分割为n个区间,绘图中常用}
pretty(c(-3,3),30)
if(FALSE){cat(...,file="myfile",append=FALSE),连接...中的对象,并将其输出到屏幕上或文件中}
firstname <- c("Jane")
cat("Hello", firstname, "!")
数据整合与重构
if(FALSE){t(x),矩阵或数据框的转置}
cars <- mtcars[1:5,1:4]
t(cars)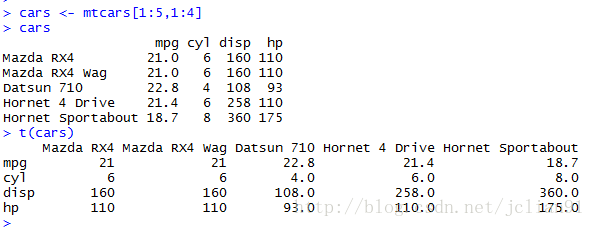
if(FALSE){aggregate(x, by, FUN),整合数据,x为待折叠的对象,by是一个变量名组成的列表,FUN为用来计算描述性统计量的标量函数}
aggregate(mtcars, by=list(mtcars$gear), FUN=mean, na.rm=TRUE)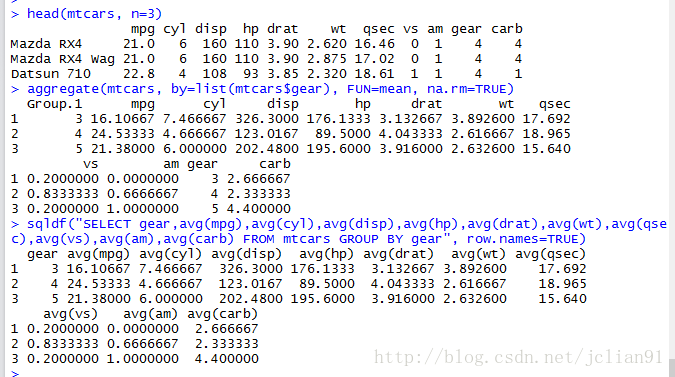
if(FALSE){使用reshape包进行数据融合和重铸}
if(FLASE){melt(),数据融合:每个测量变量独占一行,行中带有要唯一确定这个测量变量所需的标识符变量。}
md <- melt(mydata, id <- (c("id","time")))
if(FLASE){cast(md,formula,FUN),重铸:读取已融合的数据,并使用公式formula和函数FUN将其重塑。其中,formula的公式为:\n
rowvar1+rowvar2+... ~ colvar1+colvar2+...
'~'前定义了划掉的变量,以确定各行的内容,"~"后定义了划掉的列变量。
}
cast(md, id~variable, mean)
cast(md, time~variable, mean)
if(FALSE){简化代码:attach(),detach(),transform(),within(),with()函数的使用}
if(FALSE){attach(),detach()的使用,以原始egData为对象,添加两列total和mean,分别表示score1,score2的总和和平均值}
attach(egData)
egData$total <- score1+score2
egData$mean <- (score1+score2)/2
detach(egData)
if(FALSE){transform(),实现同上的功能}
egData <- transform(egData, total=score1+score2, mean=(score1+score2)/2)
if(FALSE){within()与with(),两者类似,不同的是是否允许修改数据框。实现同上的功能}
egData <- within(egData,{
total=score1+score2
mean=(score1+score2)/2})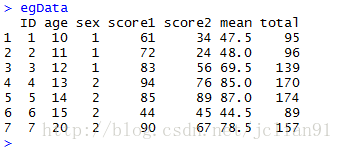
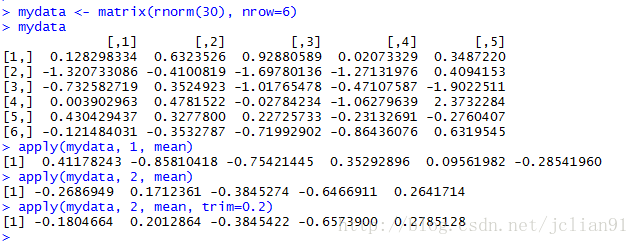
if(FALSE){apply()函数,调用格式:
apply(x, MARGIN, FUN, ...)
其中,x为数据对象,MARGIN为维度的下标,FUN为指定函数,而...则包括了任何想传递给FUN的参数。在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列。
}
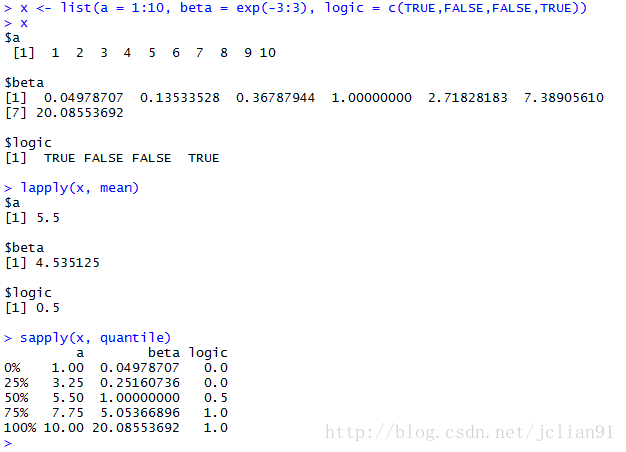
if(FALSE){lapply(),sapply()函数,应用到列表(list)上。调用格式如下:
lapply(X, FUN, ...)
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)}
x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
lapply(x, mean)
sapply(x, quantile)
names <- c("Jim Green","Alice Bell","Kent Brown")
split <- strsplit(names, " ")
sapply(split,"[",1)
sapply(split,"[",2)