def main(args: Array[String]) { val sparkConf = new SparkConf().setMaster("local").setAppName("cocapp").set("spark.kryo.registrator", classOf[HBaseConfiguration].getName) .set("spark.executor.memory", "4g") val sc: SparkContext = new SparkContext(sparkConf) val sqlContext = new HiveContext(sc) val mySQLUrl = "jdbc:mysql://localhost:3306/yangsy?user=root&password=yangsiyi" val rows = sqlContext.jdbc(mySQLUrl, "person") val tableName = "spark" val columnFamily = "cf" //rows.first().getString(1) val configuration = HBaseConfiguration.create(); configuration.set(TableInputFormat.INPUT_TABLE, "test"); val admin = new HBaseAdmin(configuration) val hBaseRDD = sc.newAPIHadoopRDD(configuration, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result]) hBaseRDD.count()

def toHbase(rows: DataFrame,tableName : String,columnFamily: String) { val configuration = HBaseConfiguration.create(); val admin = new HBaseAdmin(configuration) if (admin.tableExists(tableName)) { print("table Exists") admin.disableTable(tableName); admin.deleteTable(tableName); } configuration.addResource("hbase-site.xml") val tableDesc = new HTableDescriptor(tableName) tableDesc.addFamily(new HColumnDescriptor(columnFamily)) admin.createTable(tableDesc) rows.foreachPartition { row => val table = new HTable(configuration, tableName) row.foreach { a => val put = new Put(Bytes.toBytes("row1")) put.add(Bytes.toBytes(columnFamily), Bytes.toBytes("coulumn1"), Bytes.toBytes(a.getString(0))) table.put(put) println("insert into success") } }
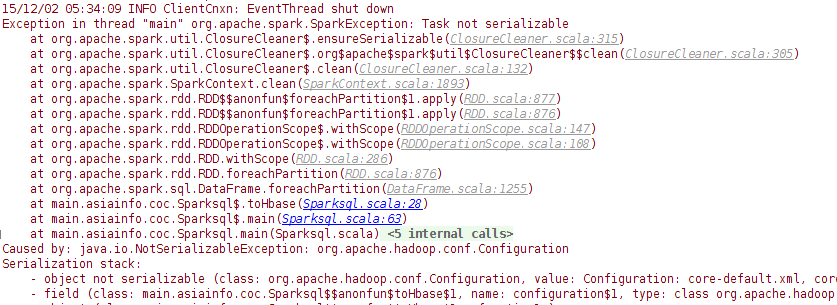
然而并没有什么乱用,发现一个问题,就是说,在RDD取值与写入HBASE的时候,引入外部变量无法序列化。。。。。。网上很多说法是说extends Serializable ,可是尝试无效。Count()是可以获取到,但是如果我要在configuration中set列,然后进行查询就会报错了。暂时各种办法尝试无果,还在想办法,也不明原因。