大家好,我今天想跟大家分享的是Sharding-Sphere的第二个产品Sharding-Proxy。
在上个月亮相的Sharding-Sphere 3.0.0.M1中首次发布了Sharding-Proxy,希望这次分享能够通过几个优化实践,帮助大家管中窥豹,从几个关键细节想象出Sharding-Proxy的全貌。至于更详细的MySQL协议、IO模型、Netty等议题,以后有机会再和大家专题分享。
一、Sharding-Proxy简介
1Sharding-Proxy概览
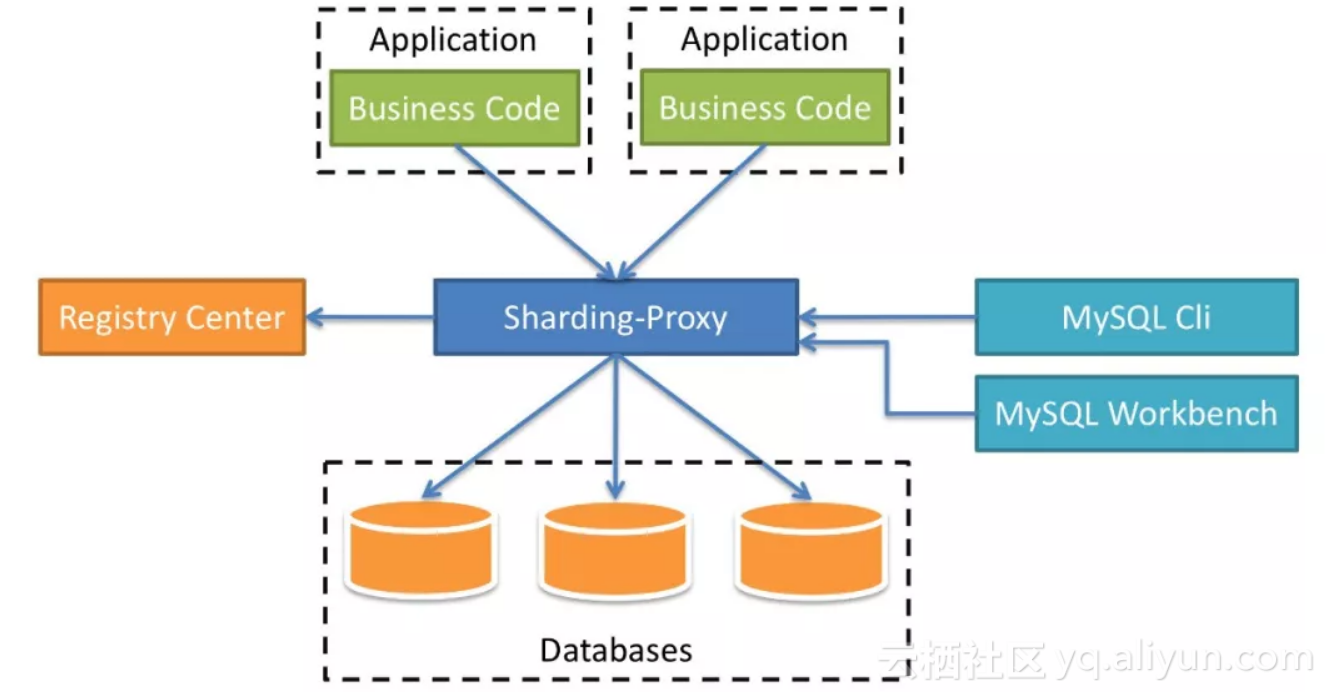
Sharding-Proxy定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端操作数据(如:MySQLCommandClient、MySQLWorkbench等),对DBA更加友好。
![]() 适用于任何兼容MySQL协议的客户端。
适用于任何兼容MySQL协议的客户端。
与其他两个产品(Sharding-JDBC、Sharding-Sidecar)的对比:
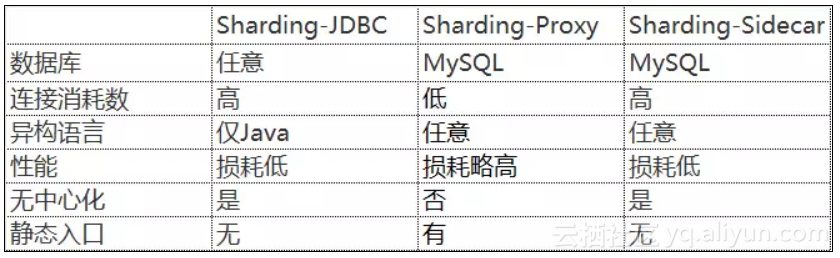
它们既可以独立使用,也可以相互配合,以不同的架构模型、不同的切入点,实现相同的功能目标。而其核心功能,如数据分片、读写分离、柔性事务等,都是同一套实现代码。
举个例子,对于仅使用Java为开发技术栈的场景,Sharding-JDBC对各种Java的ORM框架支持度非常高,开发人员可以非常便利地将数据分片能力引入到现有的系统中,并将其部署至线上环境运行,而DBA就可以通过部署一个Sharding-Proxy实例,对数据进行查询和管理。
2Sharding-Proxy架构
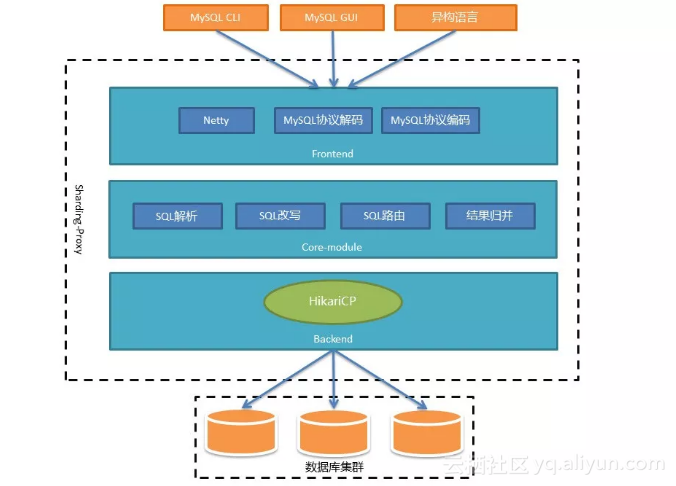
整个架构可以分为前端、后端和核心组件三部分来看:
![]() 后端(Backend)与真实数据库的交互暂时借助基于BIO的Hikari连接池。BIO的方式在数据库集群规模很大,或者一主多从的情况下,性能会有所下降。所以未来我们还会提供NIO的方式连接真实数据库。
后端(Backend)与真实数据库的交互暂时借助基于BIO的Hikari连接池。BIO的方式在数据库集群规模很大,或者一主多从的情况下,性能会有所下降。所以未来我们还会提供NIO的方式连接真实数据库。
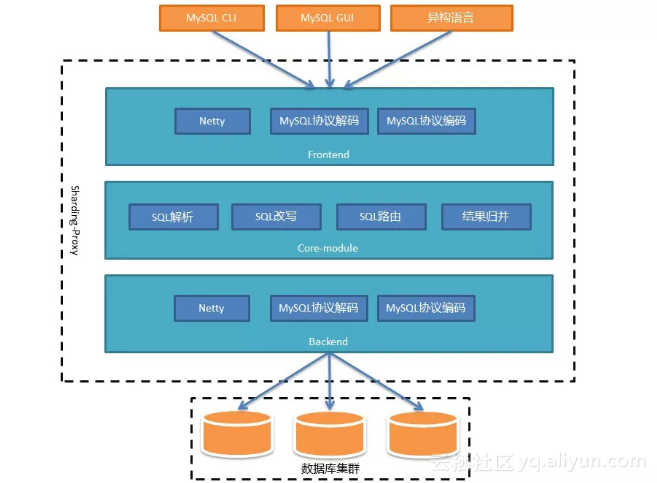
这种方式下Proxy的吞吐量将得到极大提高,能够有效应对大规模数据库集群。
二、Sharding-Proxy功能细节
1PreparedStatement功能实现
我在Sharding-Sphere的第一个任务就是实现Proxy的PreparedStatement功能。据说这是一个高大上的功能,能够预编译SQL提高查询速度和防止SQL注入攻击等。一次服务端预编译,多次查询,降低SQL编译开销,提升了效率,听起来没毛病。然而在做完之后却发现被坑了,SQL执行效率不但没有提高,甚至用肉眼都能看出来比原始的Statement还要慢。
先抛开Proxy不说,我们通过wireshark抓包看看运行PreparedStatement时MySQL协议是如何交互的。
示例代码如下:
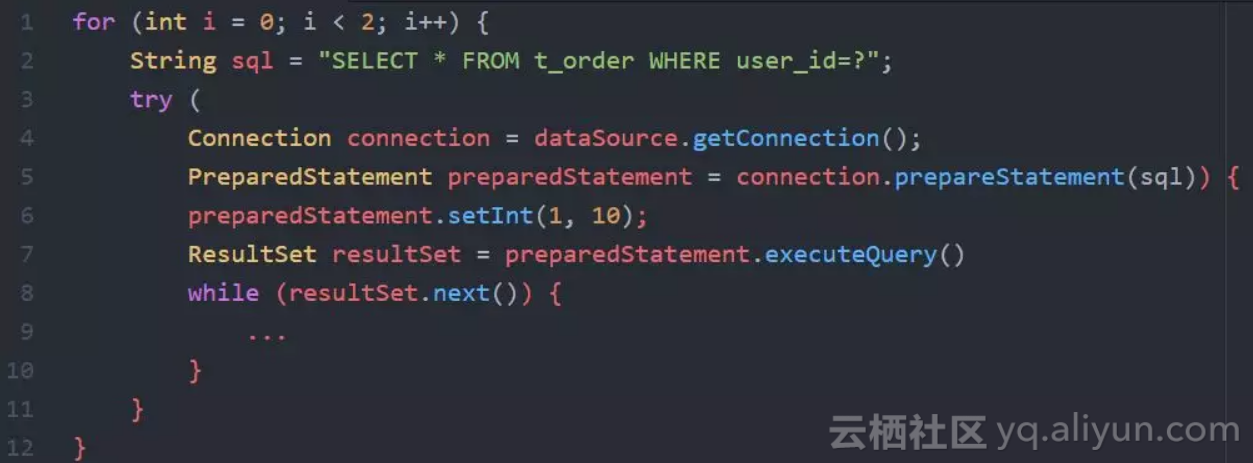
代码很容易理解,使用PreparedStatement执行两次查询操作,每次都把参数user_id设置为10。分析抓到的包,JDBC和MySQL之间的协议消息交互如下:

JDBC向MySQL进行了两次查询(Query),MySQL返回给JDBC两次结果(Response),第一条消息不是我们期望的PreparedStatement,SELECT里面也没有问号,这就说明prepare没有生效,至少对MySQL服务来说没有生效。
对于这个问题,我想大家心里都有数,是因为JDBC的url没有设置参数useServerPrepStmts=true,这个参数的作用是让MySQL服务进行prepare。没有这个参数就是让JDBC进行prepare,MySQL完全感知不到,是没有什么意义的。接下来我们在url中加上这个参数:
jdbc:mysql://127.0.0.1:3306/demo_ds?useServerPrepStmts=true交互过程变成了这样:
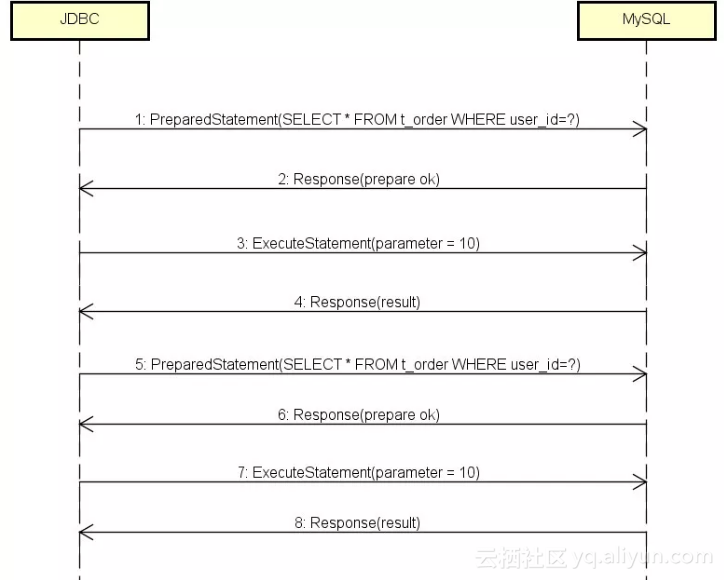
初看这是一个正确的流程,第1条消息是PreparedStatement,SELECT里也带问号了,通知MySQL对SQL进行预编译;第2条消息MySQL告诉JDBC准备成功;第3条消息JDBC把参数设置为10;第4条消息MySQL返回查询结果。然而到了第5条,JDBC怎么又发了一遍PreparedStatement?
预期应该是以后的每条查询都只是通过ExecuteStatement传参数的值,这样才能达到一次预编译多次运行的效果。
如果每次都“预编译”,那就相当于没有预编译,而且相对于普通查询,还多了两次消息传递的开销:Response(prepareok)和ExecuteStatement(parameter=10)。看来性能的问题就是出在这里了。
像这样使用PreparedStatement还不如不用,一定是哪里搞错了,于是我开始阅读JDBC源代码,终于发现了另一个需要设置的参数——cachePrepStmts。我们加上这个参数看看会不会发生奇迹:
jdbc:mysql://127.0.0.1:3306/demo_ds?useServerPrepStmts=true&cachePrepStmts=true果然得到了我们预期的消息流程,而且经过测试,速度也比普通查询快了:

从第5条消息开始,每次查询只传参数值就可以了,终于达到了一次编译多次运行的效果,MySQL的效率得到了提高。而且由于ExecuteStatement只传了参数的值,消息长度上比完整的SQL短了很多,网络IO的效率也得到了提升。
原来cachePrepStmts=true这个参数的意思是告诉JDBC缓存需要prepare的SQL,比如“SELECT*FROMt_orderWHEREuser_id=?”,运行过一次后,下次再运行就跳过PreparedStatement,直接用ExecuteStatement设置参数值。
明白原理后,就知道该怎么优化Proxy了。Proxy采用的是Hikari数据库连接池,在初始化的时候为其设置上面的两个参数:
config.addDataSourceProperty("useServerPrepStmts","true");
config.addDataSourceProperty("cachePrepStmts","true");
这样就保证了Proxy和MySQL服务之间的性能。那么Proxy和Client之间的性能如何保证呢?
Proxy在收到Client的PreparedStatement的时候,并不会把这条消息转发给MySQL,因为SQL里的分片键是问号,Proxy不知道该路由到哪个真实数据库。Proxy收到这条消息后只是缓存了SQL,存储在一个StatementId到SQL的Map里面,等收到ExecuteStatement的时候才真正请求数据库。
这个逻辑在优化前是没问题的,因为每一次查询都是一个新的PreparedStatement流程,ExecuteStatement会把参数类型和参数值告诉客户端。
加上两个参数后,消息内容发生了变化,ExecuteStatement在发送第二次的时候,消息体里只有参数值而没有参数类型,Proxy不知道类型就不能正确的取出值。所以Proxy需要做的优化就是在PreparedStatement开始的时候缓存参数类型。
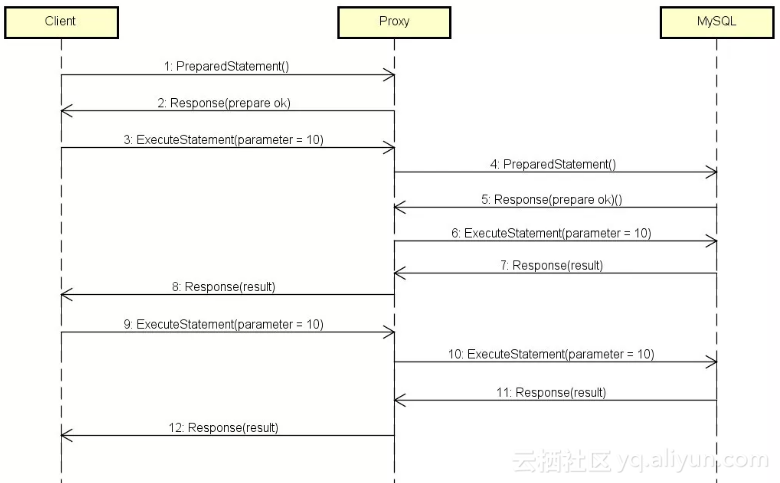
完成以上优化后,Client-Proxy和Proxy-MySQL两侧的消息交互都变成了最后这张图的流程,从第9步开始高效查询。
Hikari连接池配置优化
Proxy在初始化的时候,会为每一个真实数据库配置一个Hikari连接池。根据分片规则,SQL被路由到某些真实库,通过Hikari连接得到执行结果,最后Proxy对结果进行归并返回给客户端。那么,数据库连接池到底该设置多大?对于这个众说纷纭的话题,今天该有一个定论了。
你会惊喜的发现,这个问题不是设置“多大”,反而是应该设置“多小”!如果我说执行一个任务,串行比并行更快,是不是有点反直觉?
即使是单核CPU的计算机也能“同时”支持数百个线程。但我们都应该知道这只不过是操作系统用“时间片”玩的一个小花招。事实上,一个CPU核心同一时刻只能执行一个线程,然后操作系统切换上下文,CPU执行另一个线程,如此往复。
一个CPU进行计算的基本规律是,顺序执行任务A和任务B永远比通过时间片“同时”执行A和B要快。一旦线程的数量超过了CPU核心的数量,再增加线程数就只会更慢,而不是更快。一个对Oracle的测试验证了这个观点。
参考链接:http://www.dailymotion.com/video/x2s8uec
测试者把连接池的大小从2048逐渐降低到96,TPS从16163上升到20702,平响从110ms下降到3ms。
当然,也不是那么简单地让连接数等于CPU数就行了,还要考虑网络IO和磁盘IO的影响。当发生IO时,线程被阻塞,此时操作系统可以将那个空闲的CPU核心用于服务其他线程。所以,由于线程总是在I/O上阻塞,我们可以让线程(连接)数比CPU核心多一些,这样能够在同样的时间内完成更多的工作。到底应该多多少呢?PostgreSQL进行了一个benchmark测试:
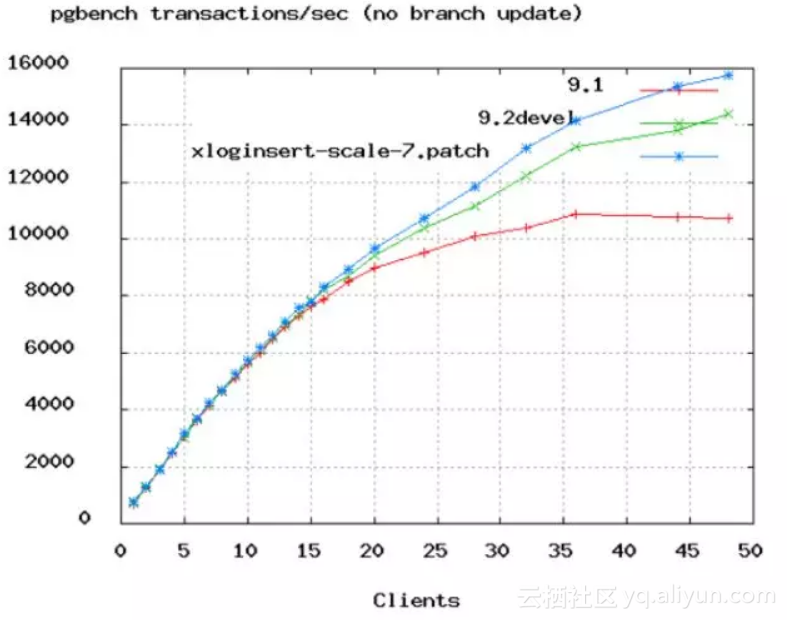
TPS的增长速度从50个连接的时候开始变慢。根据这个结果,PostgreSQL给出了如下公式:
connections=((core_count*2)+effective_spindle_count)连接数=((核心数*2)+磁盘数)。即使是32核的机器,60多个连接也就够用了。所以,小伙伴们在配置Proxy数据源的时候,不要动不动就写上几百个连接,不仅浪费资源,还会拖慢速度。
结果归并优化
目前Proxy访问真实数据库使用的是JDBC,很快Netty+MySQLProtocol异步访问方式也会上线,两者会并存,由用户选择用哪种方法访问。
在Proxy中使用JDBC的ResultSet会对内存造成非常大的压力。Proxy前端对应m个client,后端又对应n个真实数据库,后端把数据传递给前端client的过程中,数据都需要经过Proxy的内存。如果数据在Proxy内存中呆的时间长了,那么内存就可能被打满,造成服务不可用的后果。所以,ResultSet内存效率可以从两个方向优化,一个是减少数据在Proxy中的停留时间,另一个是限流。
我们先看看优化前Proxy的内存表现。使用5个客户端连接Proxy,每个客户端查询出15万条数据。结果如下图1:

(图1)
可以看到,Proxy的内存在一直增长,即时GC也回收不掉的。这是因为ResultSet会阻塞住next(),直到查询回来的所有数据都保存到内存中。这是ResultSet默认提取数据的方式,大量占用内存。
那么,有没有一种方式,让ResultSet收到一条数据就可以立即消费呢?在Connector/J文档中有这样一句话:
If you are working with ResultSets that have a large number of rows or large values and cannot allocate heap space in your JVM for the memory required , you can tell the driver to stream the results back one row at a time.
如果你使用ResultSet遇到查询结果太多,以致堆内存都装不下的情况,你可以指示驱动使用流式结果集,一次返回一条数据。
文档参考链接:
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-implementation-notes.html
激活这个功能只需在创建Statement实例的时候设置一个参数:
stmt.setFetchSize(Integer.MIN_VALUE);
这样就完成了。这样Proxy就可以在查询指令后立即通过next()消费数据了,数据也可以在下次GC的时候被清理掉。当然,Proxy在对结果做归并的时候,也需要优化成即时归并,而不再是把所有数据都取出来再进行归并,Sharding-Core提供即时归并的接口,这里就不详细介绍了。下面看看优化后的效果,如下图2:

(图2)
数据在内存中停留时间缩短,每次GC都回收掉了数据,内存效率大幅提升。看到这里,好像已经大功告成了,然而水还很深,请大家穿上潜水服继续跟我探索。图2是在最理想的情况产生的,即Client从Proxy消费数据的速度,大于等于Proxy从MySQL消费数据的速度。
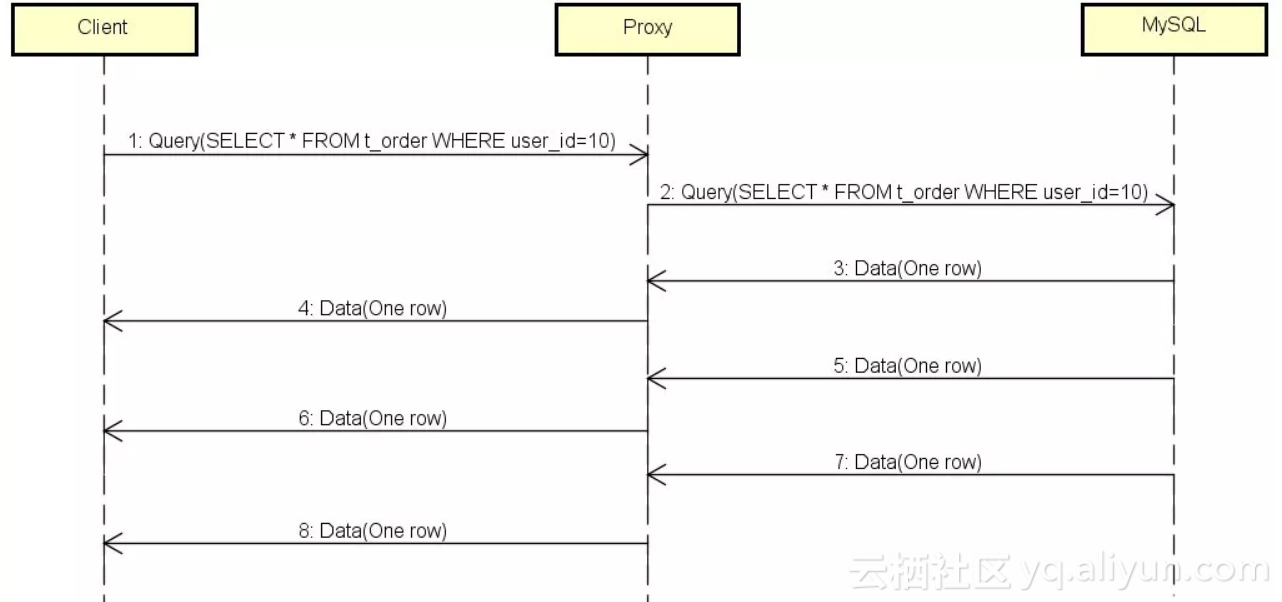
如果Client由于某种原因消费变慢了,或者干脆不消费了,会发生什么呢?通过测试发现,内存使用量直线拉升,比图1更强劲,最后将内存耗尽,Proxy被KO。
下面我们就先搞清楚为什么会发生这种现象,然后介绍对ResultSet的第2个优化:限流。
下图加上了几个主要的缓存:
![]() ChannelOutboundBuffer是Netty写缓存。
ChannelOutboundBuffer是Netty写缓存。
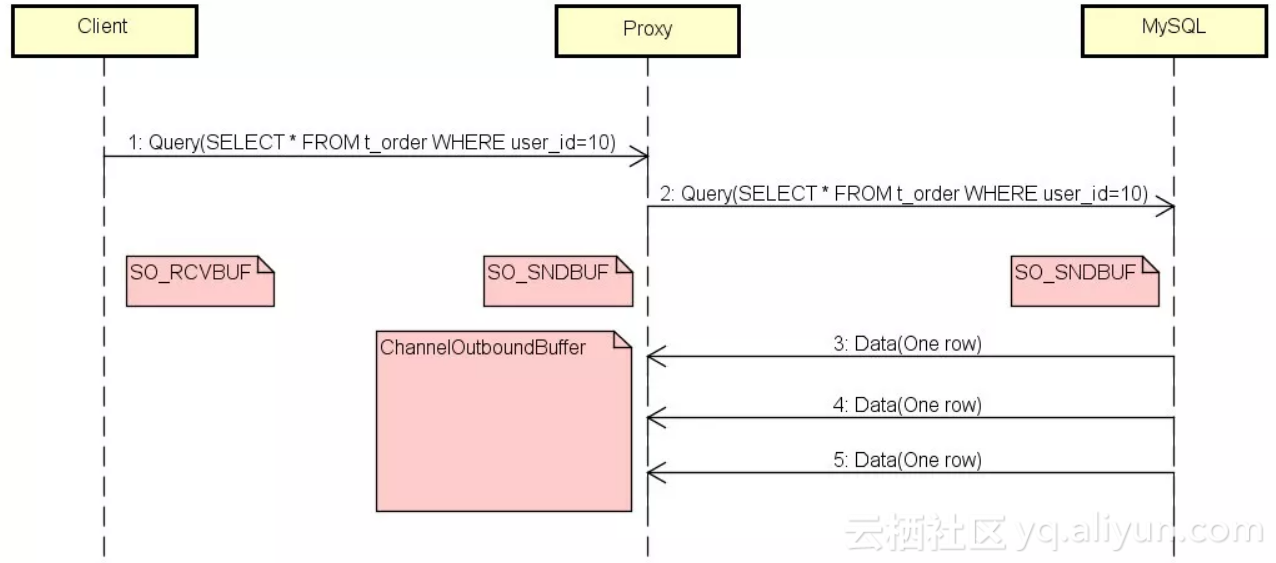
当Client阻塞的时候,它的SO_RCVBUF会被瞬间打满,然后通过滑动窗口机制通知Proxy不要再发送数据了,同时Proxy的SO_SNDBUF也会瞬间被Netty打满。
Proxy的SO_SNDBUF满了之后,Netty的ChannelOutboundBuffer就会像一个无底洞一样,吞掉所有MySQL发来的数据,因为在默认情况下ChannelOutboundBuffer是无界的。
由于有用户(Netty)在消费,所以Proxy的SO_RCVBUF一直有空间,导致MySQL会一直发送数据,而Netty则不停的把数据存到ChannelOutboundBuffer,直到内存耗尽。
搞清原理之后就知道,我们的目标就是当Client阻塞的时候,Proxy不再接收MySQL的数据。
Netty通过水位参数WRITE_BUFFER_WATER_MARK来控制写缓冲区:
所以,在这种情况下,Proxy所消耗的内存只是ChannelOutboundBuffer高水位线的大小。
Proxy的两种模式
在即将发布的Sharding-Sphere3.0.0.M2版本中,Proxy会加入两种代理模式的配置:
简单可以理解为,如果你想消耗更小的内存,就用MEMORY_STRICTLY模式;如果你想消耗更少的连接,就用CONNECTION_STRICTLY模式。
MEMORY_STRICTLY的原理其实就是我们前面介绍的内容,优点已经说过了。它带来的一个副作用是,流式ResultSet需要保持对数据库的连接,必须与所有路由到的真实表成功建立连接后,才能够进行即时归并,进而返回结果给客户端。
假设数据库设置max_user_connections=80,而该库被路由到的表是100个,那么无论如何也不可能同时建立100个连接,也就无法归并返回结果。
CONNECTION_STRICTLY就是为了解决以上问题而存在的。不使用流式ResultSet,内存消耗增加。但该模式不需要保持与数据库的连接,每次取出ResultSet内的全量数据后即可释放连接。
还是刚才的例子max_user_connections=80,而该库被路由到的表是100个。Proxy会先建立80个连接查询数据,另外20个连接请求被缓存在连接池队列中,随着前面查询的完成,这20个请求会陆续成功连接数据库。
如果你对这个配置还感到迷惑,那么记住一句话,只有当max_user_connections小于该库可能被路由到的最大表数量时,才使用CONNECTION_STRICTLY。
三、小结
Sharding-Sphere自2016年开源以来不断精进和发展,被越来越多企业和个人所使用,同时也为我们提供了重要的成功案例。未来,我们将不断优化当前的特性,陆续推出大家关注的柔性事务、数据治理等更多新特性。如果大家有什么想法、意见和建议,也欢迎留言与我们交流,更欢迎加入到Sharding-Sphere的开源项目中:
Q1:Sidecar是干什么的?
A1:Sharding-Sidecar是Sharding-Sphere的第三个产品,目前仍在规划中。定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。
Q2:“问如果你对这个配置还感到迷惑,那么记住一句话,只有当max_user_connections小于该库可能被路由到的最大表数量时,才使用CONNECTION_STRICTLY。”这句话是不是说反了?
A2:CONNECTION_STRICTLY就是为了省连接的。max_user_connections小,所以用CONNECTION_STRICTLY模式。
Q3:stmt.setFetchSize(custom_size);设置的场景使用类似Mybatis之类的框架查询大量数据到内存,一般就是放到一个list中,然后处理。内存还是会占用。
A3:这种情况占的是客户端的内存,不会影响Proxy。
Q4:问出现查询大数据量到内存的场景,是不是只能使用原生JDBC,查一批处理一批,不放内存?
A4:Mybatis是在客户端控制的,不影响Proxy。
https://m.qlchat.com/topic/details?topicId=2000001395952730&minimal=1
原文发布时间为:2018-06-20
本文作者:张永伦








