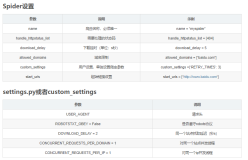
为Scrapy项目提供多个Spider
scrapy startproject project name
在终端输入上述命令后,会根据生成一个完整的爬虫项目
此时的项目树如下
|-- JobCrawler
|-- __init__.py
|-- items.py
|-- middlewares.py
|-- pipelines.py
|-- settings.py
`-- spiders
|-- __init__.py
|-- spider.py
scrapy.cfg
可以看到默认会生成一个名为spider.py的文件供我们编写spider.
如果这个时候我们要再写多一个spider, 但是不想手动去配置相应的文件, 可以用以下命令生成一个spider
# domain 域名
scrapy genspider [options] name domain
options可以选择自己需要的参数, 若留空, 则默认使用basic模板生成spider
这里我们以要爬取某网站首页入口为例, 生成一个entrance 的spider.Scrapy会为我们在spiders文件夹中生成一个entrance.py. 根据需要, 再item.py中添加相应的字段.
为每个Spider单独指定Pipeline
当我们编写完代码后可能会遇到一个问题, 在我们准备使用这个新的spider爬虫的时候, 并不准备让以前spider 的pipeline应用到新的spider身上.
一种笨的方法是, 你在用某个spider的时候, 先注释掉无关的pipeline设置(在settings.py中). 然而这并非长久之计, 且十分反程序猿, 何况后面我们还要考虑到多个spider并发的情况.
在看了一下spider的变量之后, 显然(逃, 我们可以用spider的name值来轻松指定.
在我们pipeline.py中, 为需要区分spider的方法添加一个spider参数, 主要是process_item(self, item, spider), close_spider(self, spider) 以及 open_spider(self, spider), 写一行if就搞定啦
if spider.name == 'jobCrawler':
后面再更新多个并发的情形