前景图的度量对于物体分割算法的发展有着重要的作用,特别是在物体检测领域,其目的是在场景中精确地检测和分割出物体。但是,当前广泛应用的评估指标 (AP, AUC) 都是基于像素级别的误差度量,缺少结构相似性度量,从而导致评估不准确(优秀算法排名比拙劣算法靠后)进而影响了领域的发展。
天津南开大学媒体计算实验室、美国中佛罗里达大学机构的联合研究团队从人类视觉系统对场景结构非常敏感的角度出发,提出基于区域(Region-aware)和基于对象(Object-aware)的结构性度量 (S-measure) 方法来评估非二进制前景图,进而使得评估更加可靠。该方法在5个基准数据集上采用5个元度量证明了新度量方法远远优于已有的度量方法,并且和人的主观评价具有高度一致性(77%Ours VS. 23%AUC)。
问题引出:专门评价指标缺陷
评价指标的合理与否对一个领域中模型的发展起到决定性的作用,现有的前景图检测中应用最广泛的评价指标为:平均精度AP (average precision)和曲线下的面积AUC(area under the curve)。在评价非二进制前景图时,需要将输入图像进行阈值化得到多个阈值,再计算精度(precision)和召回率(recall)。
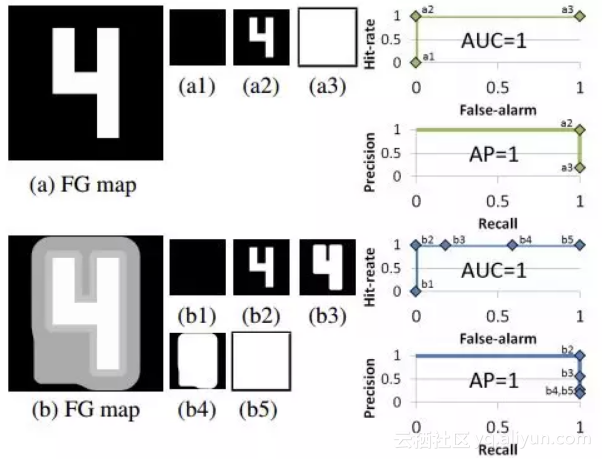
图1
然而,该方法已经被证明[1] 存在天然的缺陷。例如图1中(a)和(b)是两个完全不同的前景图,但是经过阈值化计算AP和AUC后,最后的评价结果是AP=1, AUC=1。这表示两个前景图的检测效果相当,这显然不合理。

图2
再来看另外一个实际的例子,图2中,根据应用排序(Application Ranking)以及人为排序(Human Ranking)认为蓝色框的检测结果由于红色框。然而,如图3所示,采用阈值化、再进行插值的方法(AUC)会评判红色框检测结果由于蓝色框。
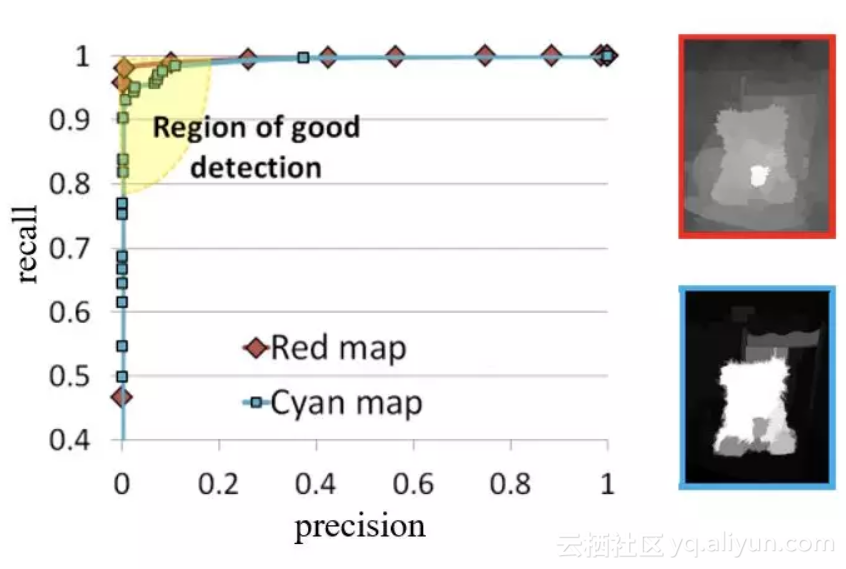
图3
因此,AUC评价方法完全依赖于插值的结果,忽略了错误发生的位置,也没有考虑到对象的结构性度量。原因在于,AUC曲线是多个领域通用的评价指标,前景图检测领域还没有一个简单高效的专有指标。为此,有必要为该领域设计一个专门的简单可靠的评价指标。
解决方案:面向区域和面向对象的结构度量
由于当前的评价指标都是考虑单个像素点的误差,缺少结构相似性度量,从而导致评估不准确。为此,研究团队根据人类视觉系统对场景结构非常敏感的角度出发,分别从2个角度去解决结构度量的问题。
如图4所示:(a)面向区域(Region-aware)结构度量和(b)面向对象(Object-aware)结构度量。
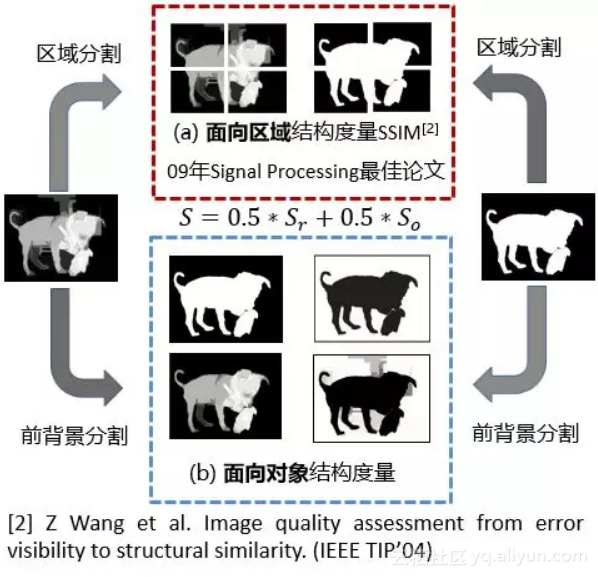
图4
-
面向区域的结构度量将区域的前背景整体度量,作为面向对象(前背景分离度量)的补充,进而为可靠的整体结构度量提供支撑。
在计算面向区域部分,首先延着Ground-truth的重心部分采取2*2分块法切割开,相应地为检测结果图切割,这样得到4局部块,后每块相似性度量方法采用著名的结构性评价指标SSIM来度量。最后,根据每个分块占整个前景图的比例进行自适应加权求和得到面向区域的结构相似度。
b. 面向对象的结构度量从物体角度出发,将前背景分离度量,与面向区域(前背景聚合成区域)互为补充,为度量对象级别的结构提供保障。
通过大量的研究发现,高质量的前景图检测结果具有如下特性:
-
-
前景与背景形成强烈的亮度对比。
-
前景与背景部分都近似均匀分布。
-
如图5所示,result1检测结果中对象内部和背景部分相对均匀,唯独亮度对比不够强烈,result2检测结果中内部对象分布不均匀,背景部分大体均匀。
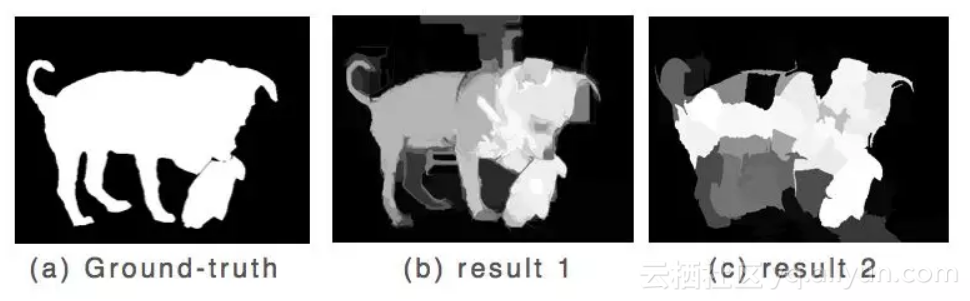
图5
研究团队通过设计一个简单的亮度差异和均匀性项来度量结构相似性。

元度量实验证明有效性
为了证明指标的有效性和可靠性,研究人员采用元度量的方法来进行实验。通过提出一系列合理的假设,然后验证指标符合这些假设的程度就可以得到指标的性能。简而言之,元度量就是一种评测指标的指标。实验采用了5个元度量:
元度量1:应用排序
推动模型发展的一个重要原因就是应用需求,因此一个指标的排序结果应该和应用的排序结果具有高度的一致性。即,将一系列前景图输入到应用程序中,由应用程序得到其标准前景图的排序结果,一个优秀的评价指标得到的评价结果应该与其应用程序标准前景图的排序结果具有高度一致性。如下图6所示。
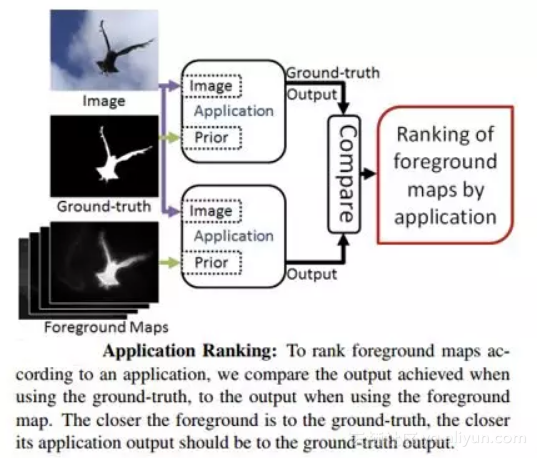
图6
元度量2:最新水平 vs.随机结果
一个指标的评价原则应该倾向于选择那些采用最先进算法得到的检测结果而不是那些没有考虑图像内容的随机结果(例如中心高斯图)。如下图7所示。

图7
元度量3:参考GT随机替换
原来指标认定为检测结果较好的模型,在参考的Ground-truth替换为错误的Ground-truth时,分数应该降低。如图8所示。

图8
元度量4:轻微标注错误
评价指标应该具有鲁棒性,一个好的评价指标不应对GT边界轻微的手工标注误差敏感。如图9所示

图9
元度量5:人工排序
人作为高级灵长类动物,擅长捕捉对象的结构,因此前景图检测的评价指标的排序结果,应该和人的主观排序具有高度一致性。我们通过收集45个不同年龄,学历,性别,专业背景的受试者的排序结果进一步证明了提出的评价指标与人的评价具有高度的一致性(最高可达77%)。下图10所示为用户调研的手机平台。
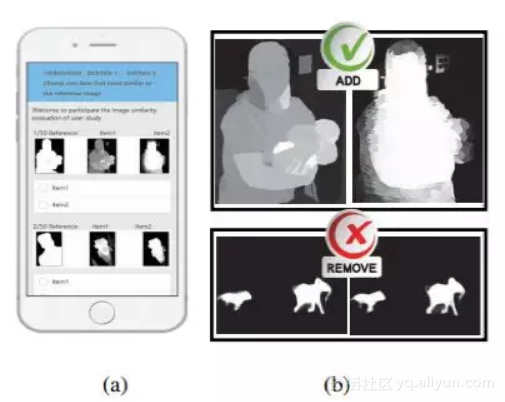
图10
实验结果
为了公平的比较,指标首先在公开的一个前景图检测数据集ASD[3]上对4个元度量进行评测。评测结果显示我们的结果取得了最佳性能:
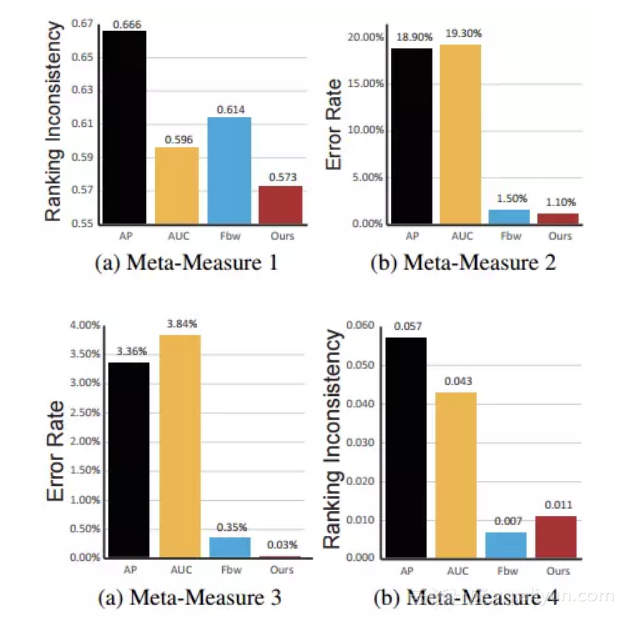
除了在基准数据集上进行评测外,还在另外4个具有不同特点的、更具挑战性数据集上进行了广泛的测试,以验证指标的稳定性、鲁棒性。
实验结果表明:我们的指标分别在PASCAL, ECSSD, SOD和 HKU-IS数据集上比排名第二的指标错误率降低了67.62%,44.05%,17.81%,69.23%。这清楚地表明新的指标具有更强的鲁棒性和稳定性。
HKU-IS数据集上比排名第二的指标错误率降低了67.62%,44.05%,17.81%,69.23%。这清楚地表明新的指标具有更强的鲁棒性和稳定性。
总结
该评测指标将很快出现在标准的Opencv库以及Matlab中,届时可以直接调用。
评测指标的代码计算简单,仅需对均值、方差进行加减乘除即可,无需阈值256次得到多个精度和召回率,再画进行繁琐的插值计算得到AUC曲线。因此,S-measure计算量非常小,在单线程CUP(4GHz)上度量一张图像仅需要5.3ms.
原文发布时间为:2018-04-16
本文作者:范登平(南开大学)
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”。
