热门的消息队列中间件RabbitMQ,分布式任务处理平台Celery,大数据分布式处理的三大重量级武器:Hadoop、Spark、Storm,以及新一代的数据采集和分析引擎Elasticsearch。
RabbitMQ
RabbitMQ是一个支持Advanced Message Queuing Protocol(AMQP)的开源消息队列实现,由Erlang编写,因以高性能、高可用以及可伸缩性出名。它支持多种客户端,如:Java、Python、PHP、.NET、Ruby、JavaScript等。它主要用于在分布式系统中存储和转发消息,方便组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP架构中有两个主要组件:Exchange和Queue,两者都在服务端,又称Broker,由RabbitMQ实现的。客户端通常有Producer和Consumer两种类型。
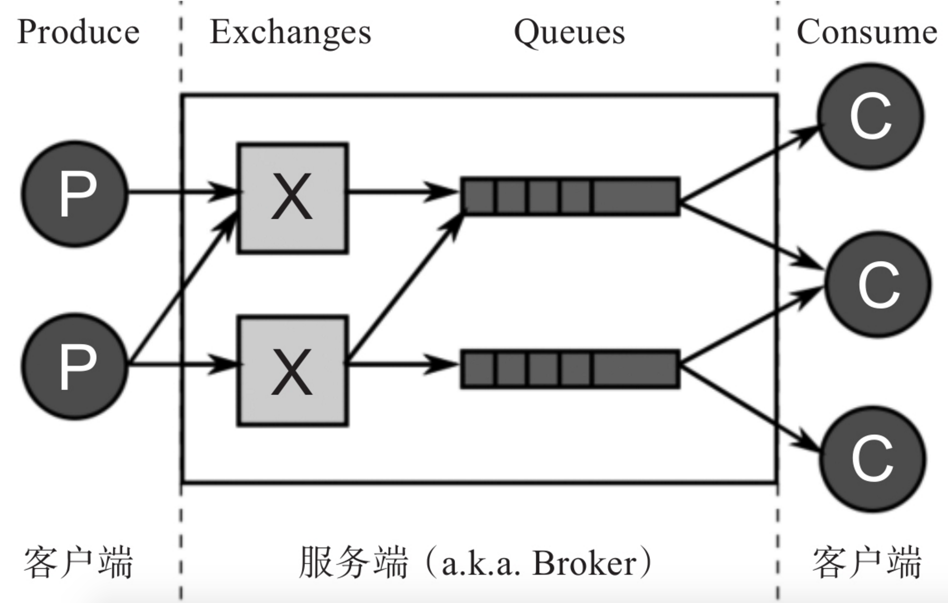
在使用RabbitMQ过程中需要注意的是,它将数据存储在Node中,默认情况为hostname。因此在使用docker run指令运行容器的时候,应该通过-h/--hostname参数指定每一个rabbitmq daemon运行的主机名。这样就可以轻松地管理和维护数据了:
$ docker run -d --hostname my-rabbit --name some-rabbit rabbitmq:3
3f28f6290e05375363ee661151170d37fbc89ada004c3235f02997b711b4cb2b
用户使用rabbitmqctl工具进行远程管理,或跨容器管理的时候,会需要设置持久化的cookie。这里可以使用RABBITMQ_ERLANG_COOKIE参数进行设置:
$ docker run -d --hostname my-rabbit --name some-rabbit -e RABBITMQ_ERLANG_COOKIE='secret cookie here' rabbitmq:3
使用cookie连接至一个独立的实例:
$ docker run -it --rm --link some-rabbit:my-rabbit -e RABBITMQ_ERLANG_COOKIE='secret cookie here' rabbitmq:3 bash
root@f2a2d3d27c75:/# rabbitmqctl -n rabbit@my-rabbit list_users
Listing users ...
guest [administrator]
同样,用户也可以使用RABBITMQ_NODENAME简化指令:
$ docker run -it --rm --link some-rabbit:my-rabbit -e RABBITMQ_ERLANG_COOKIE='secret cookie here' -e RABBITMQ_NODENAME=rabbit@my-rabbit rabbitmq:3 bash
root@f2a2d3d27c75:/# rabbitmqctl list_users
Listing users ...
guest [administrator]
默认情况下,rabbitmq会安装并启动一些管控插件,如rabbitmq:3-management。通常可以通过默认用户名密码以及标准管控端口15672访问这些插件:
$ docker run -d --hostname my-rabbit --name some-rabbit rabbitmq:3-management
用户可以通过浏览器访问http://container-ip:15672,如果需要从宿主机外访问,则使用8080端口:
$ docker run -d --hostname my-rabbit --name some-rabbit -p 8080:15672 rabbitmq:3-management
如果需要修改默认用户名与密码(guest:guest),则可以使用RABBITMQ_DEFAULT_USER和RABBITMQ_DEFAULT_PASS环境变量:
$ docker run -d --hostname my-rabbit --name some-rabbit -e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password rabbitmq:3-management
如果需要修改默认vhost,可以修改RABBITMQ_DEFAULT_VHOST环境变量:
$ docker run -d --hostname my-rabbit --name some-rabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost rabbitmq:3-management
然后连接至daemon:
$ docker run --name some-app --link some-rabbit:rabbit -d application-that-uses-rabbitmq
用户也可以访问官方镜像仓库,并对Dockerfile进行更多定制。
Celery
除了通用的消息队列外,任务队列在分布式处理中也十分重要。任务队列的输入是工作的一个单元,称为任务,有多个工作者监听队列来获取任务并执行。
Celery是一个简单、灵活、高可用、高性能的开源(BSD许可)分布式任务处理系统,专注于实时处理的任务队列管理,同时也支持任务调度。Celery基于Python实现,跟包括Django、Pyramid、Pylons、Flask、Tornado等Web框架都无缝集成,有庞大的用户与贡献者社区。Celery可以单机运行,也可以在多台机器上运行,甚至可以跨越数据中心运行。
1.使用官方镜像
启动一个celery worker,即RabbitMQ Broker:
$ docker run --link some-rabbit:rabbit --name some-celery -d celery:latest
检查集群状态:
$ docker run --link some-rabbit:rabbit --rm celery celery status
启动一个celery worker,即Redis Broker:
$ docker run --link some-redis:redis -e CELERY_BROKER_URL=redis://redis --name some-celery -d celery
检查集群状态:
$ docker run --link some-redis:redis -e CELERY_BROKER_URL=redis://redis --rm celery celery status
2.使用Celery库
如果用户使用的框架已有Celery库,那么使用起来会更方便。
下面是Python中调用Celery的hello world程序:
from celery import Celery app = Celery('hello', broker='amqp://guest@localhost//') @app.task def hello(): return 'hello world'
Hadoop
作为当今大数据处理领域的经典分布式平台,Apache Hadoop主要基于Java语言实现,由三个核心子系统组成:HDFS、YARN、MapReduce,其中,HDFS是一套分布式文件系统;YARN是资源管理系统,MapReduce是运行在YARN上的应用,负责分布式处理管理。如果从操作系统的角度看,HDFS相当于Linux的ext3/ext4文件系统,而Yarn相当于Linux的进程调度和内存分配模块。
1.使用官方镜像
可以通过docker run指令运行镜像,同时打开bash命令行,如下所示:
$ docker run -it sequenceiq/hadoop-docker:2.7.0 /etc/bootstrap.sh -bash
bash-4.1#
此时可以查看各种配置信息和执行操作,例如查看namenode日志等信息:
bash-4.1# cat /usr/local/hadoop/logs/hadoop-root-namenode-d4e1e9d8f24f.out
ulimit -a for user root core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 7758 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 1048576 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) unlimited virtual memory (kbytes, -v) unlimited file locks (-x) unlimited
2.安装验证
需要验证Hadoop环境是否安装成功。打开容器的bash命令行环境,进入Hadoop目录:
bash-4.1# cd $HADOOP_PREFIX
bash-4.1# pwd
/usr/local/hadoop
然后通过运行Hadoop内置的实例程序来进行测试:
bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
16/08/31 10:00:11 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/08/31 10:00:15 INFO input.FileInputFormat: Total input paths to process : 31 16/08/31 10:00:16 INFO mapreduce.JobSubmitter: number of splits:31 ...
最后可以使用hdfs指令检查输出结果:
bash-4.1# bin/hdfs dfs -cat output/*
Spark
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,基于Scala开发。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark支持更灵活的函数定义,可以将应用处理速度提升一到两个数量级,并且提供了众多方便的实用工具,包括SQL查询、流处理、机器学习和图处理等。
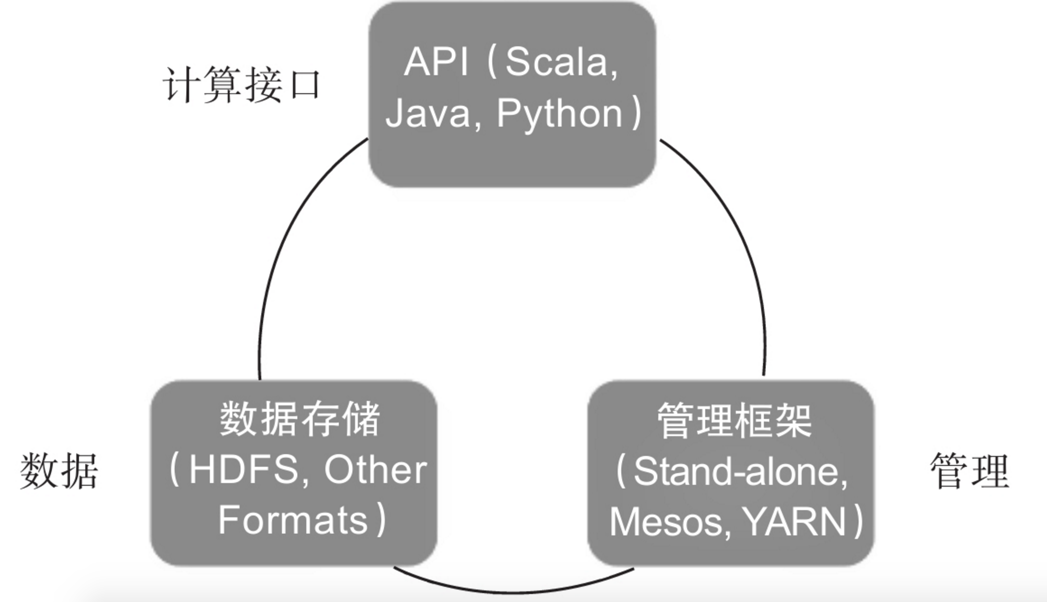
Spark体系架构包括如下三个主要组件:数据存储、API、管理框架,如图13-3所示。
1.使用官方镜像
用户可以使用sequenceiq/spark镜像,版本方面支持Hadoop 2.6.0,Apache Spark v1.6.0(CentOS)。同时此镜像还包含Dockerfile,用户可以基于它构建自定义的Apache Spark镜像。
用户使用docker pull指令直接获取镜像:
$ docker pull sequenceiq/spark:1.6.0
也可以使用docker build指令构建spark镜像:
$ docker build --rm -t sequenceiq/spark:1.6.0 .
另外,用户在运行容器时,需要映射YARN UI需要的端口:
$ docker run -it -p 8088:8088 -p 8042:8042 -h sandbox sequenceiq/spark:1.6.0 bash
启动后,可以使用bash命令行来查看namenode日志等信息:
bash-4.1# cat /usr/local/hadoop/logs/hadoop-root-namenode-sandbox.out
2.验证
基于YARN部署Spark系统时,用户有两种部署方式可选:YARN客户端模式和YARN集群模式。
下面分别论述两种部署方式。
1.YARN客户端模式
在YARN客户端模式中,SparkContext(或称为驱动程序,driver program)运行在客户端进程中,应用的master仅处理来自YARN的资源管理请求:
#运行spark shell spark-shell \ --master yarn-client \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 #执行以下指令,若返回1000则符合预期 scala> sc.parallelize(1 to 1000).count()
2.YARN集群模式
在YARN集群模式中,Spark driver驱动程序运行于应用master的进程中,即由YARN从集群层面进行管理。
下面,用户以Pi值计算为例子,展现两种模式的区别:
Pi计算(YARN集群模式):
#执行以下指令,成功后,日志中会新增记录"Pi is roughly 3.1418" #集群模式下用户必须制定--files参数,以开启metrics spark-submit \ --class org.apache.spark.examples.SparkPi \ --files $SPARK_HOME/conf/metrics.properties \ --master yarn-cluster \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \ $SPARK_HOME/lib/spark-examples-1.6.0-hadoop2.6.0.jar
Pi计算(YARN客户端模式):
#执行以下指令,成功后,命令行将显示"Pi is roughly 3.1418" spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn-client \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \ $SPARK_HOME/lib/spark-examples-1.6.0-hadoop2.6.0.jar
3.容器外访问Spark
如果需要从容器外访问Spark环境,则需要设置YARN_CONF_DIR环境变量。只能使用根用户访问Docker的HDFS环境。
yarn-remote-client文件夹内置远程访问的配置信息:
export YARN_CONF_DIR="`pwd`/yarn-remote-client"
当用户从容器集群外部,使用非根用户访问Spark环境时,则需要配置HADOOP_USER_NAME环境变量:
export HADOOP_USER_NAME=root
Storm
Apache Storm是一个实时流计算框架,由Twitter在2014年正式开源,遵循Eclipse Public License 1.0。Storm基于Clojure等语言实现。
Storm集群与Hadoop集群在工作方式上十分相似,唯一区别在于Hadoop上运行的是MapReduce任务,在Storm上运行的则是topology。MapReduce任务完成处理即会结束,而topology则永远在等待消息并处理(直到被停止)。
使用Compose搭建Storm集群
利用Docker Compose模板,用户可以在本地单机Docker环境快速地搭建一个Apache Storm集群,进行应用开发测试。
1.Storm示例架构,Storm架构图。
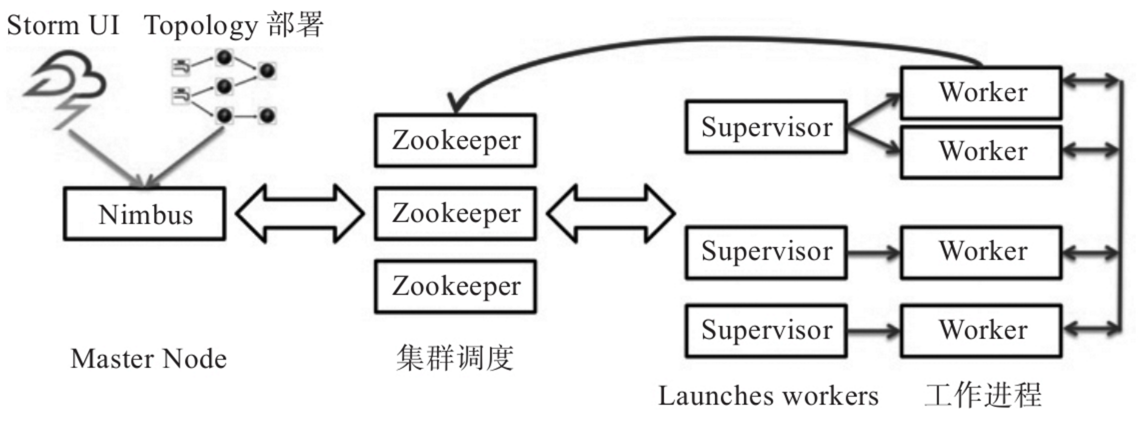
其中包含如下容器:
·Zookeeper:Apache Zookeeper三节点部署。
·Nimbus:Storm Nimbus。
·Ui:Storm UI
·Supervisor:Storm Supervisor(一个或多个)。
·Topology:Topology部署工具,其中示例应用基于官方示例storm-starter代码构建。
2.本地开发测试
首先从Github下载需要的代码:
$ git clone https://github.com/denverdino/docker-storm.git
$ cd docker-swarm/local
代码库中的docker-compose.yml文件描述了典型的Storm应用架构。
用户可以直接运行下列命令构建测试镜像:
$ docker-compose build
现在可以用下面的命令来一键部署一个Storm应用:
$ docker-compose up -d
当UI容器启动后,用户可以访问容器的8080端口来打开操作界面。
利用如下命令,可以伸缩supervisor的数量,比如伸缩到3个实例:
$ docker-compose scale supervisor=3
用户也许会发现Web界面中并没有运行中的topology。这是因为Docker Compose目前只能保证容器的启动顺序,但是无法确保所依赖容器中的应用已经完全启动并可以被正常访问了。为了解决这个问题,需要运行下面的命令来再次启动topolgoy服务应用来提交更新的拓扑:
$ docker-compose start topology
稍后刷新Storm UI,可以发现Storm应用已经部署成功了。
Elasticsearch
Elasticsearch是一个基于Lucene的开源搜索服务器,主要基于Java实现。它提供了一个分布式的,多租户的全文搜索引擎,内含RESTful web接口。
Elasticsearch提供了实时的分布式数据存储和分析查询功能,很容易扩展到上百台服务器,支持处理PB级结构化或非结构化数据。配合Logstash、Kibana等组件,可以快速构建一套对日志消息的分析平台。
可以使用官方镜像,快速运行Elasticsearch容器:
$ docker run -d elasticsearch
也可以在启动时传入一些额外的配置参数:
$ docker run -d elasticsearch elasticsearch -Des.node.name="TestNode"
目前使用的镜像内含默认配置文件,包含了预先定义好的默认配置。
如果用户要使用自定义配置,可以使用数据卷,挂载自定义配置文件至/usr/share/elasticsearch/config:
$ docker run -d -v "$PWD/config":/usr/share/elasticsearch/config elasticsearch
如果需要数据持久化,可以使用数据卷指令,挂载至/usr/share/elasticsearch/data:
$ docker run -d -v "$PWD/esdata":/usr/share/elasticsearch/data elasticsearch
此镜像会暴露9200 9300两个默认的HTTP端口,可以通过此端口进行服务访问。9200端口是对外提供服务的API使用的端口。9300端口是内部通信端口,这些通信包括心跳,集群内部信息同步。
小结
分布式处理与大数据处理领域的典型热门工具,包括Rabbitmq、Celery、Hadoop、Spark、Storm和Elasticsearch等。这些开源项目的出现,极大降低了开发者进行分布式处理和数据分析的门槛。
实际上,摩尔定律的失效,必将导致越来越多的复杂任务必须采用分布式架构进行处理。在新的架构和平台下,如何实现高性能、高可用性,如何让应用容易开发、方便调试,都是十分复杂的问题。已有的开源平台项目提供了很好的实现参考,方便用户将更多的精力放到核心业务的维护上。通过基于容器的部署和使用,极大简化了对如此复杂系统的使用和维护。

