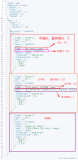
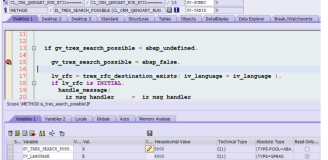
re.match
import res= '23432werwre2342werwrew' p = r'(\d*)([a-zA-Z]*)'m = re.match(p,s)print(m.group()) #返回所有匹配内容 23432werwreprint(m.group(0)) #和group()一样 23432werwreprint(m.group(1)) #返回字串第一个 23432,没有字串则报错print(m.group(2)) #返回字串第二个 werwreprint(m.groups()) #返回所有字串组成的元组 ('23432', 'werwre'),如果没有字串则为空元组
本文转自神ge 51CTO博客,原文链接:http://blog.51cto.com/12218412/1947405