前面主要和大家介绍了一下群集的种类,以及一些群集通用的基本知识,本章开始我们将专注于微软故障转移群集的深入研究与理论解析
微软故障转移群集即是我们上篇文章介绍的,一个典型的高可用性群集解决方案,它内置在Windows Server的角色与功能里面,不需要安装额外工具,故障转移群集通常情况下都是主从工作的模式,即一个群集应用同时只有一个节点对外提供服务,然后故障转移群集利用心跳检测机制检测节点存活状态,一旦检测到节点宕机,会通过查询群集数据库,来讲宕机节点承载的群集应用进行上线
同时故障转移群集也具备了完善的群集应用健康感知,节点健康状态感知,群集健康状态感知,这在2008时代之后开始得到增强,12R2时趋于成熟。
有的群集应用可以和DNS轮询相配合,或者群集应用本身具备的轮询技术,则可以基于故障转移群集来实现双活的群集应用工作模式,例如SOFS,SQL Server Always On等技术
微软故障转移群集于NT4时代就被引入,那时它叫做 MSCS(Microsoft Cluster Service),2003时代正式全面提供使用,更多企业开始采用MSCS搭建群集,但2003时代的群集,虽说2003是个出色的系统,上面跑业务也相对稳定,但是2003时代的MSCS群集配置也确实麻烦了一些,让很多人望而却步,不过话说回来,2003时代的群集,老王认为是最便于IT人员理解群集运作原理的版本之一
到了2008时,群集开始发生了改变,它改名叫做WSFC (Windows Server Failover Clustering),提供了群集创建向导,帮助相关人员可以更快更简单的创建使用高可用群集,以前2003时代可以能创建一个群集要花费一小天的时间,到了2008时代规划好了开始做可能也就1-2小时就可以完成
2008时代老王可以算是WSFC的一个转折点,这个时代,群集摒弃了2003时代的UI,换了新的群集UI,把原有的群集组等技术细节进行了屏蔽,换成了看起来更容易的添加群集角色,新增了全新的群集验证报告
2008R2,这个版本微软发布了大量的更新,其中针对于群集,微软推出了CSV群集文件系统,改变了群集虚拟化的运作模式,原来2008如果在群集上面跑虚拟机,都是以传统群集组的方式运作,假设10台虚拟机运行在一个群集磁盘上面,如果要迁移其中一台虚拟机,只能把其余9台一起迁移,因为他们是一个整体的传统群集组,到了2008R2有了CSV之后,这个做法发生了一些改变,所有节点都可以同时读取CSV文件系统,虚拟机也有了新的群集组模式,可以一次迁移一台虚拟机。
2012,2012R2时代是微软WSFC大放光彩的一代,2012时代微软推出了动态投票的概念,2012R2时代更新为动态仲裁,即群集可以自动帮助我们调整节点和见证的投票数,确保群集始终是奇数的投票,这在以前,是需要我们管理人员实现设计好的,群集可不会自动帮助我们做这些事
同时,2012时代,还对群集在少数投票,平等投票场景上面新增了很多新的属性,例如Lowerquorumprioritynodeid,可以帮助我们在分区两端投票数一致的情况下选择其中一方关闭,2012 2012R2时代的群集,针对于群集仲裁,群集节点维护,推出了很多很棒,很智能化的功能,例如
DrainOnShutdown,CAU等
简单说,2012 2012R2时代的群集,在成熟化的基础上更趋于智能化,群集可以自己进行一部分自我化的维护管理,来保证群集的持续高可用,也新增了一些智能化的功能,让管理员可以根据业务场景做更多的群集设计。
到了2016时代,老王认为群集更靠近了云端化,借助了部分云端的功能来帮助群集,也针对当前热门的超融合技术进行了支援,2016时代,群集仲裁可以使用Azure上面blob进行仲裁,这在之前,可能架构管理人员在设计仲裁位置的时候,可能会和其中一个站点的群集放在一起,或者单独放在第三个站点中,现在借助Azure上面的blob实现可以节省一部分成本,还可以利用Azure上面存储的冗余技术,2016群集也开始支援SDS技术,类似于VSAN,可以把多个服务器上面节点肚子里面的存储,贡献出来形成群集的存储池,然后基于这个贡献的群集存储池,上面再跑群集应用。
总结来说,2016时代的群集,借助了云的功能来优化群集,也针对于当下热门的技术,瞬时防断,滚动更新,SDS超融合,存储复制,延伸群集等技术进行了更新,可以看到WSFC不断在跟着时代的脚步进步,不断更新,可以满足更多场景的需求
以上老王简单的对微软故障转移群集的发展历史做了个基本介绍,其中涉及到了一些概念,例如群集组,仲裁,见证,我将在接下来为大家进行讲解,涉及到的2012及2016新功能,后续有时间也将写出博客与大家探讨,下文将对微软故障转移群集统一简称为WSFC
在正式介绍群集细节概念之前,我们先来看下WSFC对于硬件软件的要求
1.确保多个节点可以访问到相同内容的共享存储,不论是SAS,ISCSI,FCOE,JBOD,RBOD,或是SDS出来的都可以,确保同一个共享存储可以被所有群集内节点访问,以便发生故障转移时其它节点可以从共享存储上线资源
2.确保群集节点OS是正版,非盗版,否则可能会遇见一些奇奇怪怪的问题
3.确保群集节点是域成员,在2012时代开始发生了一些改变,2012时代提出了不依赖AD的群集架构,即是说,群集应用可以不创建VC0,但仍然需要节点加入域,2016时代开始支持真正的工作组群集,跨域,跨林架构的群集。
4.确保群集节点硬件相同,这个并非硬性要求,但是强烈建议各节点硬件采用完全一致的服务器,否则会出现虚拟机无法迁移等情况,老王还建议针对群集节点服务器采用模块化便于扩展的架构,充分利用例如冗余交换机,热拔插,RAID,MPIO,网卡组合,LBFO,ODX,RDMA,RSS等高可用技术和硬件卸载技术,消除单一故障点。
5.确保创建群集的账户是群集节点本机的本地管理员权限,同时也在AD具备一定的写入权限,或者是预先被AD管理员设置好的权限。
6.确保群集节点至少一块可用网卡,即使群集节点只有一个卡你也可以安装起一个群集,但是建议至少两块,原因之前博客已经说过,传送门:http://wzde2012.blog.51cto.com/6474289/1947451 ,如果不做虚拟化,最好三块卡,做虚拟化建议4块,群集对外的管理地址,可以是IPv6或者IPV4,可以是DHCP或者静态,到了2008时代之后微软并没有严格限制,但是通常我们都是采用静态IP地址,不过在多站点场景下DHCP有时候会减少一部分宕机时间,后续博客会提到。
针对于群集网络的设置这里多说几句,针对于群集通讯网卡,建议禁止netbios注册查找,这样做了之后群集名称就会仅解析到对外的网络,并不会在心跳网络上面试图进行netbios解析,DNS解析,防止进行干扰
建议调整网卡顺序将群集对外网卡设置优先级最高,其次是心跳卡或存储卡,微软也曾说过,2012时代之后网卡顺序开始不再重要,但还是建议遵守下
在2003时代,只有企业版和数据中心版可以安装MSCS群集功能,2008时代也是只有企业版,数据中心版可以安装WSFC功能,标准版和Web版只可以安装NLB群集,在2008时代开始有Core版本,Core版本也可以安装群集功能,但同样只有企业版和数据中心版可以,到了2012时代,只有标准版和数据中心版,两个版本功能一致都可以安装群集功能,区别只在于虚拟化OS授权,2016同2012一样。
WSFC群集支持节点是虚拟机也支持节点是物理机,你可以一个节点是物理机一个节点是虚拟机,也可以两个节点都是虚拟机,也可以在物理机群集上面再搭建虚拟群集,WSFC群集并不care你到底是物理还是虚拟,只要系统,网络,存储配置符合群集标准即可
以上为群集安装时的一些硬性要求,以及建议,实际操作的时候建议大家去看下technet,按照technet的文档进行执行,老王这里只选出安装要求
要点作为介绍,下面将开始介绍WSFC群集的工作原理和细部概念
首先我们先来看一下WSFC故障转移简单的工作原理,有个大概的印象
1.首先按照要求部署配置群集节点,确保群集服务器利用了冗余技术消除了服务器,网络,存储的单一故障点
2.保证群集内所有节点都可以访问到共享存储
3.群集应用将应用数据写入到群集共享存储
4.管理员新增节点1服务器上面功能角色,新增完成后节点1服务器群集数据库记录新增的角色功能以及相关联的信息,稍后会把信息同步至其它节点2,及群集仲裁磁盘
5.群集节点之间按照预定的心跳检测频率进行全网握手检测
6.节点1出现故障服务器忽然关机,这时节点2心跳检测频率达到阈值,判定节点1已经离线
7.节点2判定节点1已经离线后,会根据已经同步的群集数据库信息,查看节点1服务器当前承载的群集应用,重新将群集应用与关联IP地址,群集磁盘在节点2进行上线
8.客户端正常访问群集名称,使用群集服务,但原有节点1的群集应用,现已由节点2提供,故障转移结束
总结下这里关键的两个点
1.共享存储一定要确保是所有节点都可以访问,都可以做正常挂载卸载的,因为一个传统的群集应用数据一定是写入共享存储里面,共享存储成了权威的存储源,当其中节点宕机,其它节点会查看群集数据库的信息,然后挂载上共享存储,重新上线应用,因此共享存储的访问一定要确保
2.群集数据库是WSFC的运作的主要概念之一,群集数据库里面会记载着群集应用当前的状态,例如当前节点1运行了一个DHCP角色,状态是上线,运行了一个文件服务器角色,状态是离线,以及群集配置,群集成员配置,群集资源的添加,创建,启动,删除,停止,下线等状态变化,群集数据库就是为了帮助各个节点知道对方上面运行了什么样的群集服务,一旦对方宕机之后,将按照群集数据库里面的进行的状态信息连接上共享存储进行故障转移上线操作
说起群集的细部概念呢,老王想先从CNO和VCO讲起,因为经过考虑先讲这两个会便于后面概念的理解起来更顺畅
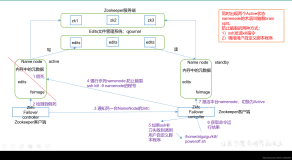
那么什么是CNO呢,之前还记得老王在写群集介绍的时候曾经和大家说过,群集就是让一组计算机协作工作,对外感觉就好像一台计算机在提供服务一样,这台让人感觉是一台对外提供的计算机,就是CNO了,也叫群集管理对象,当我们运行群集创建向导时会提示让我们输入一个群集名称和群集IP地址,实际上群集创建向导会用我们运行这个群集创建向导的账号,去群集中创建一个计算机对象,计算机对象的名称就是我们输入的群集名称,同时也会创建出相对的DNS记录,有计算机对象了,有DNS记录了,也有IP地址了,像是一台计算机了对不对。
这里关键的点,要确保运行群集创建向导的账户,有权限在AD中写入计算机对象,默认需要在AD域级别赋予权限,也可以采用实现创建好计算机对象的方式,创建好对应名称的CNO计算机对象,即创建向导账户对其具备完全控制权限,然后将账户加入到群集节点本地管理员组,这就是该账户所需要的权限
当创建出CNO后 , CNO即作为群集管理点,以后我们管理群集,直接输入CNO群集名称即可,除了作为群集管理点,一些不需要创建VCO的群集角色也可以直接使用CNO作为对外访问名称,CNO具备一定的自我管理特性,当CNO被正常创建出来之后,CNO就会维护群集角色虚拟计算机VCO,及VCO的DNS记录
所谓VCO,即是说,一些基于WSFC群集上面跑的应用,需要有自己单独计算机对象和名称的,例如SQL,文件服务器角色,当它们需要使用Kerberos 身份验证的时候就需要计算机对象,我们在群集中添加角色和功能的时候,VCO实际上是由CNO去AD里面相同OU中帮忙创建,因此也需要确保CNO在OU下面具备创建计算机对象的权限,VCO的DNS记录也会由CNO去帮忙建立,有些时候可能会出现群集资源名称无法连接,这时候就要看看是不是CNO VCO计算机对象离线了,或者是CNO没有权限创建DNS记录或VCO对象。
CNO或是VCO的DNS记录 IP地址实际运作时都会被绑定在一个节点上,该节点对于VCO CNO来说就是主节点,例如CNO的主节点可以是节点1,VCO的主节点可以是节点2,当节点1出现故障时候,CNO的IP地址和域名就会故障转移到节点2进行绑定,如果节点1活了,这时候节点2又挂掉,那么CNO和VCO的IP地址和域名都会转移至节点1绑定,这里的绑定可以理解为hosting
说完了CNO和VCO的概念之后,再来谈群集组的概念相对就更好理解了一些
群集组大家可以把它理解为群集最小故障转移单位,在2003时代,我们创建群集之后就可以直观的看到群集组的工作状态,这也就是上面我说2003时代的群集更便于大家理解群集工作状态,2003时代我们创建好了一个群集后,就会有一个群集组,群集组里面有群集IP地址,群集名称,群集见证磁盘,这就是群集所需要的最基本最重要的信息,这些东西活着,群集也就可以对外提供服务,这个概念一直延续至今,直至2016,群集创建完成后默认群集背后都会产生一个群集组,也叫做群集核心资源,它可以理解为其它群集角色群集组之父,一切的群集应用都是要因为已经已由群集核心资源组才可以被建立出来,我们打开群集管理控制台可以看到有个主服务器,核心资源组在那台机器上,那台机器就是群集主服务器。
当我们在群集中添加角色的时候,传统的群集应用都会让我们输入应用名称,应用IP地址,与可以用的群集磁盘,用于存放群集应用数据,这里的群集应用名称,应用IP地址,选择的群集磁盘,就构成了一个群集组
例如当前我们建立了个传统的文件服务器角色,要向把它进行计划内的故障转移,实质上我们会按照整体的一个群集组来进行迁移,将群集应用IP地址,群集应用DNS名称从节点1转移到节点2上面hosting,然后把挂载在节点1上面的共享磁盘,挂载到节点2。
在传统群集组中单个群集磁盘通常只能被一个群集应用占用,例如如果文件服务器使用了这块群集磁盘,那么其他群集应用则不能重复使用这块磁盘,而且要迁移只能整个群集组一起迁移
这对于虚拟机来说就很不方便,既然你一个群集应用只能用一个群集磁盘,那在2008时代,群集用虚拟化,如果虚拟机都创建在一个群集组中,虚拟机都在同一块群集磁盘上,即是说当你要迁移其中一台虚拟机,只能把上面的其它和你用同一个群集组的虚拟机都一起迁移走,很快微软发现这种传统群集组的方式并不太适合虚拟化,于是在2008R2开始,微软推出了CSV群集文件系统,同时也对群集虚拟机的运作方式做了改变,摒弃传统群集组的故障转移做法,针对于群集上面的虚拟机有了新的群集组模型,和传统的群集组都不一样,新的虚拟机群集组里面只包含单台虚拟机的虚拟机配置信息,虚拟机磁盘,虚拟机状态等单台虚拟机特定的信息,每次每台虚拟机的计划内或计划外迁移将只涉及到这些信息,再不需要被迫迁移所有虚拟机。
以上为群集组的简要介绍,只要大家知道群集组是群集最小的故障转移单位就可以,当我们计划内或计划外迁移一个传统群集应用的时候,实际上后台会发生把应用整体群集组一并迁移到其它节点进行hosting,针对于虚拟机2008R2开始我们则可以只迁移单虚拟机相关信息的群集组。
说完群集组之后,我们来看下群集验证报告的概念,在2003时代并没有这种东西,2003只是群集安装完成后会产生安装log,在2008时代开始,群集换了新的UI,也推出了群集验证报告,时至今日,群集验证报告也是很多微软支持员工的排错利器。
简单来说,群集验证报告是什么呢,可以把它理解为一个群集的私人医生,当我们创建群集的时候,强烈建议运行一次群集验证报告,它会帮助我们从系统配置,网络,存储等多个角度来诊断,当前环境是否适合创建群集,如果创建群集,那些条件是已经满足的,已经满足的会显示一片绿色的对勾,那些条件是没有遵守微软最佳实践,但是不会影响到群集建立的,这类报告会显示为黄色的惊叹号,那些条件如果不满足群集的要求,会导致群集创建出现错误的,会显示红色的叉叉,一定要进行处理才行。
通常老王建议创建群集的时候群集验证报告是一定要运行的,然后当针对于群集环境,例如变更了网络,存储,新增了节点,都建议运行一下群集验证报告,确保变更不会为现有群集带来故障
需要特别注意的是群集验证报告中的存储,在进行群集验证报告的时候我们可以选择,要验证什么,可以是系统配置,网络,或存储等,其中当验证存储的时候,可能会导致群集磁盘出现暂时的离线,如果上面跑了业务,也许会出现短暂的停机时间,因此当进行群集验证报告时勾选了存储一定要谨慎,如果不勾选存储验证,则不会导致宕机时间,一起都正常执行着。
群集验证报告是群集重要的的私人医生,它告诉我们那些是正确的,那些是不正确的,那些是可以改进的,当我们因为一个群集的问题给微软开case,微软的支持工程师可能首先就会叫你把群集验证报告导出生成,发给他一份,群集验证报告本身已经针对很多群集内容进行了验证,对WSFC感兴趣的朋友有时间可以好好看下群集验证报告。
接下来也是本文的重中之重,我们要讲解WSFC中的仲裁,见证,投票的概念,坦白说,之前刚做微软的产品的时候老王对于这些概念是一头雾水的,做可以,但从来搞不清楚真正含义,我相信很多刚踏入微软世界的朋友可能也会有同样的问题,接下来老王会试着把这些东西讲清楚
提到见证投票概念之前我们先来看下仲裁,群集到底为什么需要仲裁,仲裁到底起到什么作用,你有没有去思考过呢,最初老王就是总也搞不清仲裁到底起到一个什么作用,经过一段时间的学习研究,我有了一点自己的体会
仲裁,在老王看来,是一种群集用于维护群集持续可用的机制,例如,当群集里面宕机了一个节点,仲裁要根据仲裁模型决定宕机了一个节点,是否违背群集仲裁模型的要求,如果群集宕机节点超过了一定数量,违背了仲裁模型的要求,仲裁会认为,群集当前已经无法正常对外提供服务,而将群集关闭
因此,仲裁的第一个作用,老王认为是在群集节点发生状态变化下,根据预定的仲裁模型,来决定群集是否可以继续存活下去
第二个作用,则是当群集发生分区时,维持保证群集多数节点一方的分区正常运行,举个例子,例如当前群集在北京广州两个站点,北京站点有三台群集节点,广州站点有两台,当前他们使用的仲裁模型是多数节点,这时,北京广州直接出现一个网络故障,北京没办法访问广州,这时群集仲裁会去判断,阿,群集一共两个站点,北京站点还剩下三个节点,它是多数,它可以活下来,这时由北京三个节点重新组成群集,当广州节点网络恢复正常,群集将重新形成继续
除了维护多数,仲裁还需要解决处理脑裂的问题,例如当前群集在北京广州两个站点,北京有两个节点,广州也有两个节点,它们采用了多数节点仲裁模型,这时候如果北京与广州直接出现网络故障没办法联系,那么北京的节点和广州的节点都会试图去争取写入数据到共享磁盘,北京广州各自都以为自己活着,自己才是主节点,结果就会导致群集数据损坏,群集不正常工作,这种情况在2008R2的时代经常会遇到,可能两个站点之间节点数一致,忽然忘了不通,或者使用了见证磁盘,但是见证磁盘联系不上了,就会导致这种脑裂的情况发生
因此,仲裁的目的,就是要始终确保,群集分区情况下是由多数的节点负责运作,少数节点一方应该关闭,即应该始终确保群集投票数是奇数,因为一旦出现偶数投票,就又会出现脑裂各自为政的情况,怎么确保群集投票数始终是奇数呢,一方面我们可以利用群集现有的技术,一方面是架构设计人员的设计理念要准确,如果是四个节点,那么你就一定要设计成磁盘见证或共享见证,否则脑裂一触即发。
那么什么是见证呢,大家可能常常会听见仲裁盘,见证盘,其实所谓的见证,就是WSFC 2008时代为了帮助我们在偶数节点下避免脑裂而推出的一项技术
默认情况下,群集内每个节点都会有自己的投票,当节点可以通过网络状况检测,切当前与共享存储连接正常,系统也正常可用,则该节点的投票有效,假设当前是一个四个节点的群集,如果每个节点都工作正常的话,那么应该是有四个投票,如果是两个站点,即每个站点两票,当发生一个网络分区的时候群集就会出现脑裂,这时如果引入了见证磁盘的话,当出现一个50/50分区时,那一端可以联系到见证,就可以获取见证的票数,即见证磁盘也会具备自己分区的投票数,当发生50/50分区时,那一端可以先和见证磁盘建立连接,那一端就会获胜,继续运行群集,没能联系到见证磁盘的一方则会被关闭。
磁盘见证和共享文件夹都是同样的目的,是微软最初用于解决脑裂问题的方案,虽然可以解决一部分脑裂的问题,但有时还是会存在脑裂的情况,虽说磁盘见证和共享文件夹是做同样的目的,但是它们有些地方还是不太相同,磁盘见证和共享文件夹都可以处理脑裂的问题,但是一旦出现一个时间分区的时候,磁盘见证就可以很好的处理,而共享文件夹不行,例如,当前节点1 节点2 使用了共享文件夹,当节点1上面添加了DHCP角色,然后节点1宕机,这时只有节点2活着,我们在上面添加了文件服务器角色,然后节点2也宕机,这时我们开启节点1,会在群集中看到节点1群集无法启动对外提供服务
原因是节点1不具备最新的群集数据库,因为共享文件夹见证中没有存放群集数据库,因此群集检测到节点1没有最新的群集数据库,将会阻止该节点的启动,如果是使用磁盘见证则不会,因为磁盘见证中也存在群集数据库,群集节点的数据库也会同步至见证磁盘,如果使用磁盘见证的话,节点1开机会联系到磁盘见证,与磁盘见证同步最新的群集数据库,然后上线群集资源,因此,建议如果可以选择磁盘见证,尽量选择磁盘见证,磁盘见证是黄金法则!
到了2012时代,群集做出了重要的更新,推出了动态投票,动态见证的智能化方式,简单来说,你可以4个节点用磁盘见证了,3个节点也可以用磁盘见证,因为群集会自己动态的为你去调整见证的票数,例如,现在群集是3个节点加见证磁盘,那么会自动去掉见证磁盘的一票,群集现在是3票,如果又新增了一个节点进来,当前四个节点,又会重新加上见证的一票,群集现在是5票,因此在2012时代及之后,WSFC群集是始终建议大家针对群集配置磁盘见证的,不论是奇数或是偶数节点都可以,因为群集会自动帮我们去调整票数,通过动态仲裁可以几乎帮我们处理百分之80的脑裂场景。
在一些极端情况下,例如第三个站点的见证磁盘无法联系,我们也可以通过强制启动群集,或Lowerquorumprioritynodeid等技术,来在50/50的情况下处理脑裂,利用强制启动也可以在群集分区少数的一方将群集进行启动,例如当前5个节点的群集,四个节点都在站点1,1个站点在站点2,站点1全部崩溃,站点2还活着,但由于仲裁算法默认不会让少的票数一方提供服务,但有时少不少,能提供服务就行,我们也可以通过强制启动技术将站点2的一个节点强制启动起来提供服务,因此现在的WSFC已经可以很好的处理脑裂,50/50场景,以及少数节点存活场景。
以目前中国最多使用的2008R2群集为例,在2008R2中WSFC仲裁模型一共有四种
节点多数:每个群集节点具备自己的投票数,要求多数节点投票,群集才可以正常运行,例如5节点至少要有3个有效票,3节点至少要有2个有效票,低于有效票默认群集不会对外提供服务。
节点和磁盘多数:每个节点具备自己的投票数,见证磁盘也具备一票,当见证磁盘活着的时候,允许群集坏掉节点的半数,例如6节点群集,见证磁盘活着,则可以允许坏掉3个节点,加上见证磁盘的一票,群集依然可以正常活着,当见证磁盘挂掉,则节点必须有多数投票,群集才可以活着,例如,如果见证磁盘挂掉,5个节点的群集,最多只能坏两台,要至少保证3个可用票
节点和共享多数:同磁盘多数一致,不通点在于共享见证里面没有群集数据库,不会处理时间分区的问题,适用于没有见证存储的场景
仅硬盘:在这种仲裁模型下,只有见证磁盘具有一票,所有节点都会试图去争取到见证磁盘,当发生分区时能够和见证磁盘连接的节点即可以存活,例如如果是一个8节点的群集,那怕坏掉7个节点,只剩下一个节点,但是它可以和磁盘联系,那么群集也可以活下去,群集应用会尽可能的在这台节点上托管,这时最早2003时代引入的仲裁模型,优点是在磁盘可用的情况下,能够在群集只有一个节点的情况下存活。缺点是磁盘成为了单一故障点,在2003之后的版本微软已经不再推荐这种仲裁模型
以上我们介绍了仲裁,见证,投票,仲裁模型,下面我们把这些概念串起来看下是否会更加容易理解
群集需要仲裁来判定群集是否可以存活,仲裁根据仲裁模型的要求来评测群集内的投票数,当投票数按照仲裁模型设定,达到最少容许存活及以上,则仲裁判定群集可以存活,若超过仲裁模型的最少容许存活,则群集关闭,当出现脑裂分区时,仲裁会去利用见证的投票数,来选择其中一方分区继续提供服务,另外一方关闭
至于仲裁为什么默认会判定票数多的一方可以作为权威方存活,为什么不是选少的一方,老王认为微软可能是思考,多的一方可以承担更多的群集应用,随着技术的不断更新,仲裁也可以在50/50,或少数节点存活的情况下强制选择其中一方启动,另外一方关闭。
老王又想到一个形象的例子,来阐述仲裁,投票,我们以酒店的例子来说
诚意酒店要开张,首先得去工商部门注册,我们要开一个酒店,工商部门说,这里有几种运作模式,你们选一下吧,最少要有几个服务员一起干活才能算是合理的酒店,这个就是仲裁模型,比如老王选了我们酒店一共五个服务员,最少也应该提供3个服务员对外服务,工商部门说那好吧,记住哦,你们最少应该有3个服务员的时候才可以以酒店身份正常对外营业。
办完工商注册老王回店里开店,挂牌子,牌子就是群集对外名称,大家看到你这个名称,就都进来吃饭了,每个员工上班的时候都会自动打卡报告,我今天是健康的,我可以正常和别人沟通,我可以工作,这个就是投票,这时候服务员小李有病请假了,四个服务员仍然可以干活,然后又有一个服务员小黄要结婚也请假了,还剩下三个服务员,也可以干活,只是每个人干的活比以前多了一点,这时候小红又请假了,哎呀经理啊,我生病了不能来干活了,这时候只剩下两个服务员干活,这时候工商局立马就来了,说你们酒店当初不是说至少三个人提供服务吗,现在就剩下两个人了,你们酒店不能开了先关了吧,等人来了再开,这时候酒店虽然关了,但是内部装修什么的都没动,不过牌子暂时不能访问进来吃饭了,但是当服务员又齐了,就又可以恢复对外提供服务了。
不知道这个例子大家是否可以理解,仲裁就可以理解为你与群集签订的一个协议,群集会遵守这个协议来判断你这个群集是否可以存活
如果出现脑裂的情况呢,举个例子,比如诚意酒店在北京和天津都设有分公司,两个分公司都需要和工商部门报告工作,只有汇报了工作才可以正常对外提供服务,工商部门正常情况下只对应一个分公司,只有当这个分公司出现问题,才是另外分公司和它报告,然后呢,天津酒店有两个服务员,北京酒店也有两个服务员,正常情况下每天他们都要电话沟通,今天到底是你汇报还是我汇报。
这天忽然电话线路出故障了,北京联系不上天津,天津也联系不上北京,那怎么办,但是也得汇报啊,于是两边就都以为我应该汇报,我应该提供服务,于是两边就都给工商部打电话汇报工作,但是汇报的又都不一致,工商部领导一会听北京的,一会听天津的,于是工商部领导也蒙了,你们酒店到底怎么回事今天,能不能干了,一会这样一会那样,于是这就是脑裂了
如果有见证呢,那就是相当于两家分公司和工商部谈好了,领导,我们正常情况下都是通过通电话来确认是谁和您报告工作,一旦电话出现故障,我们就以人为准,您看这个大胖子,他是我们公司的专家,它在哪个分公司,您就听哪个分公司的就行,工商部领导说好的,然后过两天电话线路又坏了,但是大胖子在北京,和工商部领导一说,阿,大胖子在你们分公司,你们分公司人多,那就你们先对外提供服务把,天津那边等他线路修好再说
如果是强制仲裁呢,那就是说北京分店和天津分店又出现线路故障了,但是北京分店这边和工商部领导谈话了,领导啊,我们这边今天比较重要,您听我们的吧,于是工商部领导说,那好吧,既然你们着急今天就听你们的,然后北京分店和领导汇报完工作,好啦,北京分店现在可以正常提供服务了,但是天津那边我回头也要通知它一下呢,告诉他我今天听了北京的了,明天你们先休息一天。
到了2012R2之后呢,一旦发生这种强制仲裁,是不用再通知天津,告诉他明天你们先不要开的,等通知,2012R2之后一旦天津检测到北京这面发生了强制仲裁,天津自动就不会启动,它会知道北京这面已经存在了强制仲裁操作,我应该遵守它的操作。
如果是使用Lowerquorumprioritynodeid属性,或者2016里面的Site preferred属性呢,就是说,事先工商局那边已经订好规则了,当出现北京天津都是两个人,没有大胖子的时候,我应该不听谁的,例如设置了Lowerquorumprioritynodeid是天津的节点,那即是说当出现脑裂情况,直接北京的自动被提升对外提供服务。
以上为老王对于WSFC的基础知识简要介绍,希望看到的朋友都能够有自己的收获,理论奠基篇已经结束,下篇老王将使用一套2008R2的环境带大家实作群集仲裁发生时的真实形态,以及应对的正确方式。
本文转自 老收藏家 51CTO博客,原文链接:http://blog.51cto.com/wzde2012/1950557