中文分词把文本切分成词语,还可以反过来,把该拼一起的词再拼到一起,找到命名实体。
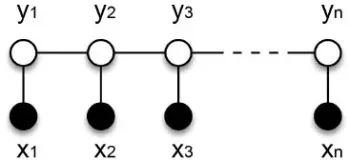
概率图模型条件随机场适用观测值条件下决定随机变量有有限个取值情况。给定观察序列X,某个特定标记序列Y概率,指数函数 exp(∑λt+∑μs)。符合最大熵原理。基于条件随机场命名实体识别方法属于有监督学习方法,利用已标注大规模语料库训练。
命名实体的放射性。命名实体的前后词。
特征模板,当前位置前后n个位置字/词/字母/数字/标点作为特征,基于已经标注好语料,词性、词形已知。特征模板选择和具体识别实体类别有关。
命名实体,人名(政治家、艺人等)、地名(城市、州、国家、建筑等)、组织机构名、时间、数字、专有名词(电影名、书名、项目名、电话号码等)。命名性指称、名词性指称和代词性指称。
词形上下文训练模型,给定词形上下文语境中产生实体概率。词性上下文训练模型,给定词性上下文语境中产生实体概率。给定实体词形串作为实体概率。给定实体词性串作为实体概率。
词性,名、动、形、数、量、代、副、介、连、助、叹、拟声。自然语言处理词性,区别词、方位词、成语、习用语、机构团体、时间词,多达100多种。汉语词性标注最大困难“兼类”,一个词在不同语境中有不同词性,很难从形式上识别。
词性标注过程。标注,根据规则或统计方法做词性标注。校验,一致性检查和自动校对方法修正。
统计模型词性标注方法。大量已标注语料库训练,选择合适训练用数学模型,概率图隐马尔科夫模型(HMM)适合词性标注基于观察序列标注情形。
隐马尔可夫模型参数初始化。模型参数初始化,在利用语料库前用最小成本和最接近最优解目标设定初值。HMM,基于条件概率生成式模型,模型参数生成概率,假设每个词生成概率是所有可能词性个数倒数,计算最简单最有可能接近最优解生成概率。每个词所有可能词性,已有词表标记,词表生成方法简单,已标注语料库,很好统计。生成概率初值设置0。
规则词性标注方法。既定搭配关系上下文语境规则,判断实际语境按照规则标注词性。适合既有规则,对兼词词性识别效果好,不适合网络新词层出不穷、网络用语新规则。机器学习自动提取规则,初始标注器标注结果和人工标注结果差距,生成修正标注转换规则,错误驱动学习方法。经过人工校总结大量有用信息补充调整规则库。
统计方法、规则方法相结合词性标注方法。规则排歧,统计标注,最后校对,得到正确标注结果。首选统计方法标注,同时计算计算置信度或错误率,判断结果是否可疑,在可疑情况下采用规则方法歧义消解,达到最佳效果。
词性标注校验。校验确定正确性,修正结果。检查词性标注一致性。一致性,所有标注结果,相同语境同一个词标注相同。兼类词,被标记不同词性。非兼类词,人工校验或其他原因导致标记不同词性。词数目多,词性多,一致性指标无法计算公式求得,基于聚类和分类方法,根据欧式距离定义一致性指标,设定阈值,保证一致性在阈值范围内。词性标注自动校对。不需要人参与,直接找出错误标注修正,适用一个词词性标注通篇全错,数据挖掘和规则学习方法判断相对准确。大规模训练语料生成词性校对决策表,找通篇全错词性标注自动修正。
句法分析树生成。把一句话按照句法逻辑组织成一棵树。
句法分析分句法结构分析和依存关系分析。句法结构分析是短语结构分析,提取出句子名词短语、动词短语等。分基于规则的分析方法和基于统计分析方法。基于规则方法存在很多局限性。基于统计方法,基于概率上下文无关文法(PCFG),终结符集合、非终结符集合、规则集。
先展示简单例子,感受计算过程,再叙述理论。
终结符集合,表示有哪些字可作句法分析树叶子节点。非终结符集合,表示树非页子节点,连接多个节点表达关系节点,句法规则符号。规则集,句法规则符号,模型训练概率值左部相同的概率和一定是1。
一句话句法结构树可能有多种,只选择概率最大作句子最佳结构。 设W={ω1ω2ω3……}表示一个句子,其中ω表示一个词(word),利用动态规划算法计算非终结符A推导出W中子串ωiωi+1ωi+2……ωj的概率,假设概率为αij(A),递归公式,αij(A)=P(A->ωi),αij(A)=∑∑P(A->BC)αik(B)α(k+1)j(C)。
句法规则提取方法与PCFG的概率参数估计。大量的树库,训练数据。树库中句法规则提取生成结构形式,进行合并、归纳等处理,得到终结符集合∑、非终结符集合N、规则集R。概率参数计算方法,给定参数一个随机初始值,采用EM迭代算法,不断训练数据,计算每条规则使用次数作为最大似然计算得到概率估值,不断迭代更新概率,最终得出概率符合最大似然估计精确值。
参考资料:
《Python 自然语言处理》
http://www.shareditor.com/blogshow?blogId=82
http://www.shareditor.com/blogshow?blogId=86
http://www.shareditor.com/blogshow?blogId=87
欢迎推荐上海机器学习工作机会,我的微信:qingxingfengzi

![深度学习应用篇-自然语言处理-命名实体识别[9]:BiLSTM+CRF实现命名实体识别、实体、关系、属性抽取实战项目合集(含智能标注)](https://ucc.alicdn.com/fnj5anauszhew_20230612_f6156a252ec749c2b2da136bddf3a09d.png?x-oss-process=image/resize,h_160,m_lfit)