

一基础单表查询
1.1查询表结构
desc 表名
SQL> desc emp
Name Null? Type
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
1.2查找空值
使用 is null
SQL> select empno from emp where comm is null;
EMPNO 7369
7566
7698
7782
7839
7900
7902
79348 rows selected.
1.3 将空值转换成实际值,推荐使用coalesce
SQL> select empno,nvl(comm,0) from emp where comm is null;
EMPNO NVL(COMM,0) 7369 0
7566 0
7698 0
7782 0
7839 0
7900 0
7902 0
7934 08 rows selected.
SQL> select empno,nvl2(comm,comm,0) from emp where comm is null;
EMPNO NVL2(COMM,COMM,0) 7369 0
7566 0
7698 0
7782 0
7839 0
7900 0
7902 0
7934 08 rows selected.
SQL> select empno,nullif(0,comm) from emp where comm is null;
EMPNO NULLIF(0,COMM) 7369 0
7566 0
7698 0
7782 0
7839 0
7900 0
7902 0
7934 08 rows selected.
SQL> select empno,coalesce(comm,0) from emp where comm is null;
EMPNO COALESCE(COMM,0) 7369 0
7566 0
7698 0
7782 0
7839 0
7900 0
7902 0
7934 08 rows selected.
NVL(expr1,expr2)
如果expr1和expr2的数据类型一致,则:
如果expr1为空(null),那么显示expr2,
如果expr1的值不为空,则显示expr1。
NVL2(expr1,expr2, expr3)
如果expr1不为NULL,返回expr2; expr1为NULL,返回expr3。
expr2和expr3类型不同的话,expr3会转换为expr2的类型,转换不了,则报错。
NULLIF(expr1,expr2)
如果expr1和expr2相等则返回空(NULL),否则返回expr1。
coalesce(expr1, expr2, expr3….. exprn)
返回表达式中第一个非空表达式,如果都为空则返回空值。
所有表达式必须是相同类型,或者可以隐式转换为相同的类型,否则报错。
Coalese函数和NVL函数功能类似,只不过选项更多。
1.4 在SELECT语句中使用条件逻辑
SQL> select empno,
2 ename,
3 sal,
4 case
5 when sal<=2000 then '过低'
6 when sal>=4000 then '过高'
7 else 'OK'
8 end as status
9 from emp
10 where deptno=10;
EMPNO ENAME SAL STATUS 7782 CLARK 2450 OK
7839 KING 5000 过高
7934 MILLER 1300 过低1.5限制返回行数
SQL> select empno from emp where rownum<=2;
EMPNO 7369
74991.6从表中随机返回n条记录
SQL> select empno,ename from (select empno,ename from emp order by dbms_random.value()) where rownum<=3;
EMPNO ENAME 7839 KING
7521 WARD
7566 JONESSQL> select empno,ename from (select empno,ename from emp order by dbms_random.value()) where rownum<=3;
EMPNO ENAME 7499 ALLEN
7698 BLAKE
7654 MARTIN1.7 TRANSLATE替换
2.SQL> select TRANSLATE('ab 你好 abcdef','abcdef','123456') as newstring from dual;
NEWSTRING
12 你好 123456
SQL> select TRANSLATE('ab 你好 abcdef','abcdef','1234') as newstring from dual;
NEWSTRING
12 你好 1234
SQL> select TRANSLATE('ab 你好 abcdef','acdef','1234') as newstring from dual;
NEWSTRING
1b 你好 1b234
SQL> select TRANSLATE('ab 你好 abcdef','acdef','') as newstring from dual;
N
替换值为空,返回空
SQL> select TRANSLATE('ab 你好 abcdef','1abcdef','1') as newstring from dual;
NEWSTRING
你好
替换wei位置没有字符则删除
1.8 混合字符串按字母排序
SQL> set line 100
SQL> col TRANSLATE(EMPNO||''||ENAME,'-1234567890','-') format A40
SQL> select empno||' '||ename as data,translate(empno||' '||ename,'- 1234567890','-') from emp e order by 2 ;
7499 ALLEN ALLEN
7698 BLAKE BLAKE
7782 CLARK CLARK
7902 FORD FORD
7900 JAMES JAMES
7566 JONES JONES
7839 KING KING
7654 MARTIN MARTIN
7934 MILLER MILLER
7369 SMITH SMITH
7844 TURNER TURNER
7521 WARD WARD
12 rows selected.
SQL> select empno||' '||ename as data from emp e order by translate(empno||' '||ename,'- 1234567890','-') ;
DATA
7499 ALLEN
7698 BLAKE
7782 CLARK
7902 FORD
7900 JAMES
7566 JONES
7839 KING
7654 MARTIN
7934 MILLER
7369 SMITH
7844 TURNER
DATA
7521 WARD
12 rows selected.
1.9 NULL排序使用NULLS FIRST/LAST
1.10按条件区不同列中值来排序
SQL> select empno,
2 ename,
3 sal
4 from emp
5 where deptno=30
6 order by Case
7 when sal>=1000 and sal <2000 then
8 empno
9 else ename
10 end,
11 sal;
ename,
*
ERROR at line 2:
ORA-00932: inconsistent datatypes: expected NUMBER got CHAR
SQL> select empno,
2 ename,
3 sal
4 from emp
5 where deptno=30
6 order by Case
7 when sal>=1000 and sal <2000 then 1
8 else 2
9 end, 3;
EMPNO ENAME SAL 7654 MARTIN 1250
7521 WARD 1250
7844 TURNER 1500
7499 ALLEN 1600
7900 JAMES 950
7698 BLAKE 28506 rows selected.
二 多表操作
2.1 union all与空字符串
SQL> select 'a' as c1 from dual
2 union all
3 select '' as c1 from dual;
C
a
2.2 union与or
SQL> select empno,ename from emp where empno=7782 or ename='WARD';
EMPNO ENAME 7521 WARD
7782 CLARKSQL> select empno,ename from emp where empno=7782
2 union
3 select empno,ename from emp where ename='WARD';
EMPNO ENAME 7521 WARD
7782 CLARKSQL> alter session set"_b_tree_bitmap_plans"=false;
Session altered.
SQL> explain plan for select empno,ename from emp where empno=7782 or ename='WARD';
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
Plan hash value: 3956160932
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 2 | 20 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 2 | 20 | 3 (0)| 00:00:01 |
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
1 - filter("EMPNO"=7782 OR "ENAME"='WARD')
13 rows selected.
SQL> explain plan for select empno,ename from emp where empno=7782
2 union
3 select empno,ename from emp where ename='WARD';
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
Plan hash value: 1027572458
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
PLAN_TABLE_OUTPUT
| 0 | SELECT STATEMENT | | 2 | 20 | 6 (34)| 00
:00:01 |
| 1 | SORT UNIQUE | | 2 | 20 | 6 (34)| 00
:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 10 | 1 (0)| 00
:00:01 |
PLAN_TABLE_OUTPUT
|* 4 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00
:00:01 |
|* 5 | TABLE ACCESS FULL | EMP | 1 | 10 | 3 (0)| 00
:00:01 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
4 - access("EMPNO"=7782)
5 - filter("ENAME"='WARD')
18 rows selected.
实际上ENAME也可以建索引那样更快
需要注意的
SQL> select deptno from emp where EMPNO=7698 or job='SALESMAN' ORDER BY 1;
DEPTNO 30
30
30
30
30SQL> select deptno,empno from emp where EMPNO=7698 or job='SALESMAN' ORDER BY 1;
DEPTNO EMPNO 30 7499
30 7521
30 7844
30 7698
30 7654
SQL> select deptno from emp where EMPNO=76982 union
3 select deptno from emp where job='SALESMAN';
DEPTNO 30避免这样问题出现可以用唯一列,主键列或rowid
SQL> select deptno,empno from emp where EMPNO=7698
2 union
3 select deptno,empno from emp where job='SALESMAN';
DEPTNO EMPNO 30 7499
30 7521
30 7654
30 7698
30 7844SQL> with
2 e as (select rownum as sn,deptno,empno,job from emp)
3 select deptno
4 from
5 (
6 select sn,deptno from e where EMPNO=7698
7 union
8 select sn,deptno from e where job='SALESMAN'
9 )
10 order by 1;
DEPTNO 30
30
30
30
302.3 组合相关的行
SQL> select e.empno,e.ename,d.dname,d.loc
2 from emp e
3 inner join dept d on (e.deptno=d.deptno)
4 where e.deptno =10;
EMPNO ENAME DNAME LOC 7782 CLARK ACCOUNTING NEW YORK
7839 KING ACCOUNTING NEW YORK
7934 MILLER ACCOUNTING NEW YORK
SQL> select e.empno,e.ename,d.dname,d.loc2 from emp e
3 inner join dept d using(deptno)
4 where deptno =10;
EMPNO ENAME DNAME LOC 7782 CLARK ACCOUNTING NEW YORK
7839 KING ACCOUNTING NEW YORK
7934 MILLER ACCOUNTING NEW YORK 2.4 IN,EXISTS和INNER JOIN
SQL> alter session set"_b_tree_bitmap_plans"=false;
alter session set"_b_tree_bitmap_plans"=false
*
ERROR at line 1:
ORA-12571: TNS:packet writer failure
SQL> conn scott/tiger@clonepdb_plug
Connected.
SQL> alter session set"_b_tree_bitmap_plans"=false;
Session altered.
SQL> explain plan for select empno,ename,job,deptno,sal
2 from emp
3 where (empno,ename,sal) in (select empno,ename,sal from emp )
4 ;
Explained.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
Plan hash value: 3956160932
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 12 | 300 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 12 | 300 | 3 (0)| 00:00:01 |
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
1 - filter("ENAME" IS NOT NULL AND "SAL" IS NOT NULL)
13 rows selected.
SQL> explain plan for select empno,ename,job,deptno,sal
2 from emp a
3 where exists (select null
4 from emp b
5 where b.ename=a.ename
6 and b.job=a.job
7 and b.sal=a.sal);
Explained.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
Plan hash value: 977554918
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 12 | 516 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN SEMI | | 12 | 516 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 12 | 300 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| EMP | 12 | 216 | 3 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
1 - access("B"."ENAME"="A"."ENAME" AND "B"."JOB"="A"."JOB" AND
"B"."SAL"="A"."SAL")
16 rows selected.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
Plan hash value: 3638257876
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 12 | 516 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN | | 12 | 516 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 12 | 300 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| EMP | 12 | 216 | 3 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
1 - access("B"."JOB"="A"."JOB" AND "B"."ENAME"="A"."ENAME" AND
"B"."SAL"="A"."SAL")
16 rows selected.
SQL> explain plan for select a.empno,ename,job,sal,a.deptno
2 from emp a inner join emp b using(job,ename,sal)
3 ;
Explained.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
Plan hash value: 3638257876
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 12 | 516 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN | | 12 | 516 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 12 | 300 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| EMP | 12 | 216 | 3 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
1 - access("A"."SAL"="B"."SAL" AND "A"."ENAME"="B"."ENAME" AND
"A"."JOB"="B"."JOB")
16 rows selected.
2.5 INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN区别
INNER JOIN 返回必配数据
LEFT JOIN 左表为主,右表只返回左表匹配数据,右表没有显示的为空 等同于右(+)
RIGHT JOIN与上面相反等同于左(+)
FULL JOIN 左右表均返回索引数据,匹配的显示一行
2.6 自关联
SQL> run/
1 select a.empno as "员工编号",
2 a.ename as "员工姓名",
3 a.job as "职位",
4 b.empno as "主管编号",
5 b.ename as "主管姓名"
6 from emp a
7 left join emp b on(a.mgr=b.empno)
8* order by 1
员工编号 员工姓名 职位 主管编号 主管姓名
7369 SMITH CLERK 7902 FORD
7499 ALLEN SALESMAN 7698 BLAKE
7521 WARD SALESMAN 7698 BLAKE
7566 JONES MANAGER 7839 KING
7654 MARTIN SALESMAN 7698 BLAKE
7698 BLAKE MANAGER 7839 KING
7782 CLARK MANAGER 7839 KING
7839 KING PRESIDENT
7844 TURNER SALESMAN 7698 BLAKE
7900 JAMES CLERK 7698 BLAKE
7902 FORD ANALYST 7566 JONES员工编号 员工姓名 职位 主管编号 主管姓名
7934 MILLER CLERK 7782 CLARK12 rows selected.
2.7 NOT IN、NOT EXISTS和 LEFT JOIN
SQL> select count(*) from emp where deptno =40;
COUNT(*)
0SQL> select * from dept where deptno not in (select deptno from emp where deptno is null);
DEPTNO DNAME LOC 10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
SQL> select * from dept where not exists (select null from emp where emp.deptno=dept.deptno );no rows selected
SQL> select dept.* from dept left join emp on dept.deptno=emp.deptno where emp.deptno is null;
no rows selected
2.8 外连接的条件不能乱放
SQL> select dept.* from dept left join emp on(dept.deptno=emp.deptno and emp.deptno is null);
DEPTNO DNAME LOC 10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGOSQL> alter session set"_b_tree_bitmap_plans"=false;
Session altered.
SQL> explain plan for select dept.* from dept left join emp on(dept.deptno=emp.deptno and emp.deptno is null);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
Plan hash value: 2251696546
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
PLAN_TABLE_OUTPUT
| 0 | SELECT STATEMENT | | 3 | 69 | 6 (17)| 00
:00:01 |
| 1 | MERGE JOIN OUTER | | 3 | 69 | 6 (17)| 00
:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 3 | 60 | 2 (0)| 00
:00:01 |
| 3 | INDEX FULL SCAN | PK_DEPT | 3 | | 1 (0)| 00
:00:01 |
PLAN_TABLE_OUTPUT
|* 4 | SORT JOIN | | 1 | 3 | 4 (25)| 00
:00:01 |
|* 5 | TABLE ACCESS FULL | EMP | 1 | 3 | 3 (0)| 00
:00:01 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
4 - access("DEPT"."DEPTNO"="EMP"."DEPTNO"(+))
filter("DEPT"."DEPTNO"="EMP"."DEPTNO"(+))
5 - filter("EMP"."DEPTNO"(+) IS NULL)
19 rows selected.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
Plan hash value: 1353548327
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
PLAN_TABLE_OUTPUT
| 0 | SELECT STATEMENT | | 1 | 23 | 6 (17)| 00
:00:01 |
| 1 | MERGE JOIN ANTI | | 1 | 23 | 6 (17)| 00
:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 3 | 60 | 2 (0)| 00
:00:01 |
| 3 | INDEX FULL SCAN | PK_DEPT | 3 | | 1 (0)| 00
:00:01 |
PLAN_TABLE_OUTPUT
|* 4 | SORT UNIQUE | | 12 | 36 | 4 (25)| 00
:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 12 | 36 | 3 (0)| 00
:00:01 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
4 - access("DEPT"."DEPTNO"="EMP"."DEPTNO")
filter("DEPT"."DEPTNO"="EMP"."DEPTNO")
18 rows selected.
2.9 检查两个表中数据及对应数据条数是否相等
SQL> run
1 select a.empno,a.ename,b.empno,b.ename
2 from emp a
3 full join emp b on(b.empno=a.empno)
4* where b.empno is null or b.empno is null
no rows selected
SQL> 4
4 where b.empno is null or b.empno is null
SQL> del
SQL> run
1 select a.empno,a.ename,b.empno,b.ename
2 from emp a
3 full join emp b on(b.empno=a.empno)
EMPNO ENAME EMPNO ENAME 7369 SMITH 7369 SMITH
7499 ALLEN 7499 ALLEN
7521 WARD 7521 WARD
7566 JONES 7566 JONES
7654 MARTIN 7654 MARTIN
7698 BLAKE 7698 BLAKE
7782 CLARK 7782 CLARK
7839 KING 7839 KING
7844 TURNER 7844 TURNER
7900 JAMES 7900 JAMES
7902 FORD 7902 FORD
EMPNO ENAME EMPNO ENAME 7934 MILLER 7934 MILLER12 rows selected.
2.10多表查询的空值处理
比ALLEN提成低的
SQL> select a.ename,a.comm
2 from emp a
3 where coalesce(a.comm,0)<(select b.comm from emp b where b.ename='ALLEN');
ENAME COMM
SMITH
JONES
BLAKE
CLARK
KING
TURNER 0
JAMES
FORD
MILLER
9 rows selected.
第三插入、更新与删除
SQL> create table test(
2 c1 varchar2(10) default '默认1',
3 c2 varchar2(10) default '默认2',
4 c3 varchar2(10) default '默认3',
5 c4 date default sysdate
6 );
Table created.
SQL> insert into test(c1,c2,c3) values(default,null,'test');
1 row created.
SQL> select * from test
2 ;
C1 C2 C3 C4
默认1 test 2017-12-26 09:46:20
3.1阻止对某几列插入
SQL> create or replace view v_test as select c1,c2,c3 from test;
View created.
SQL> insert into V_TEST values ('手输1',null,'不改4');
1 row created.
SQL> select * from test;
C1 C2 C3 C4
默认1 test 2017-12-26 09:46:20
手输1 不改4 2017-12-26 09:57:36
SQL> insert into V_TEST values (default,null,'不改4');
insert into V_TEST values (default,null,'不改4')
*
ERROR at line 1:
ORA-32575: Explicit column default is not supported for modifying views
3.2复制表定义与结构
SQL> create table test1 as select * from test where 1=2;
Table created.
SQL> select * from test1;
no rows selected
SQL> create table test2 as select * from test;
Table created.
SQL> select * from test2;
C1 C2 C3 C4
默认1 test 2017-12-26 09:46:20
手输1 不改4 2017-12-26 09:57:36
3.3利用with check option限制数据输入
SQL> alter table test modify c3 not null;
Table altered.
SQL> create or replace view v_test1 as select c1,c2,c3 from test with check option;
View created.
SQL> insert into V_TEST1 values ('test',null,null);
insert into V_TEST1 values ('test',null,null)
*
ERROR at line 1:
ORA-01400: cannot insert NULL into ("SCOTT"."TEST"."C3")
3.4多表插入语句
无条件insert
SQL> insert all
2 into test1(c1,c2,c3) values ('1','2','3')
3 into test2(c1,c2,c3) values ('1','2','3')
4 into test(c1,c2,c3) values ('1','2','3')
5 select from test1 ;
插入次数取决于select 行数
要一行的话建议用select from dual;
有条件insert
SQL> run
1 insert all
2 when job in ('CLERK','SALESMAN') then
3 into test (c1,c2,c3) values (ENAME,JOB,mgr)
4 when job='MANAGER' then
5 into test1 (c1,c2,c3) values (ENAME,JOB,mgr)
6 else
7 into test2 (c1,c2,c3) values (ENAME,JOB,mgr)
8 select from emp
12 rows created.
SQL> select * from test
2 ;
C1 C2 C3 C4
默认1 test 2017-12-26 09:46:20
手输1 不改4 2017-12-26 09:57:36
1 2 3 2017-12-26 10:29:31
SMITH CLERK 7902 2017-12-26 10:39:54
ALLEN SALESMAN 7698 2017-12-26 10:39:54
WARD SALESMAN 7698 2017-12-26 10:39:54
MARTIN SALESMAN 7698 2017-12-26 10:39:54
TURNER SALESMAN 7698 2017-12-26 10:39:54
JAMES CLERK 7698 2017-12-26 10:39:54
MILLER CLERK 7782 2017-12-26 10:39:54
10 rows selected.
SQL> select * from test1;
C1 C2 C3 C4
11 12 13
JONES MANAGER 7839
BLAKE MANAGER 7839
CLARK MANAGER 7839
SQL> select * from test2;
C1 C2 C3 C4
默认1 test 2017-12-26 09:46:20
手输1 不改4 2017-12-26 09:57:36
21 22 23
KING PRESIDENT
FORD ANALYST 7566
SQL> insert first
2 when job in ('CLERK','SALESMAN') then
3 into test (c1,c2,c3) values (ENAME,JOB,mgr)
4 when empno in (7900,7934,7566) then
5 into test1 (c1,c2,c3) values (ENAME,JOB,mgr)
6 else
7 into test2 (c1,c2,c3) values (ENAME,JOB,mgr)
8 select job,ename,mgr,empno from emp;
12 rows created.
SQL> select * from test;
C1 C2 C3 C4
SMITH CLERK 7902 2017-12-26 10:53:18
ALLEN SALESMAN 7698 2017-12-26 10:53:18
WARD SALESMAN 7698 2017-12-26 10:53:18
MARTIN SALESMAN 7698 2017-12-26 10:53:18
TURNER SALESMAN 7698 2017-12-26 10:53:18
JAMES CLERK 7698 2017-12-26 10:53:18
MILLER CLERK 7782 2017-12-26 10:53:18
7 rows selected.
SQL> select * from test1;
C1 C2 C3 C4
JONES MANAGER 7839
SQL> select * from test2;
C1 C2 C3 C4
BLAKE MANAGER 7839
CLARK MANAGER 7839
KING PRESIDENT
FORD ANALYST 7566
3.5Merge into用法总结
MERGE INTO table_name alias1
USING (table|view|sub_query) alias2
ON (join condition)
WHEN MATCHED THEN
UPDATE table_name
SET col1 = col_val1,
col2 = col_val2
WHEN NOT MATCHED THEN
INSERT (column_list) VALUES (column_values);
严格意义上讲,”在一个同时存在Insert和Update语法的Merge语句中,总共Insert/Update的记录数,就是Using语句中alias2的记录数”。
3.6删除重复记录
SQL> insert into test values (1,2,3,default)
2 ;
1 row created.
SQL> insert into test values (1,2,3,default);
1 row created.
SQL> select * from test;
C1 C2 C3 C4
1 2 3 2017-12-26 11:08:14
1 2 3 2017-12-26 11:08:18
SQL> select rowid as rid,
2 c1,
3 row_number() over(partition by c1 order by c4) as seq
4 from test
5 order by 2,3;
RID C1 SEQ
AAASXpAALAAAACuAAA 1 1
AAASXpAALAAAACuAAB 1 2
SQL> delete
2 from test
3 where rowid in (select rid
4 from (select rowid as rid,
5 row_number() over(partition by c1 order by c4) as seq
6 from test)
7 where seq>1);
1 row deleted.
SQL> select * from test;
C1 C2 C3 C4
1 2 3 2017-12-26 11:08:14
SQL> delete
2 from test a
3 where exists(select /+hash_sj/ null from test b where b.c1=a.c1 and b.rowid>a.rowid);
保留最新的<保留老的
1 row deleted.
SQL> select * from test;
C1 C2 C3 C4
1 2 3 2017-12-26 13:32:18
第四字符串
4.1 遍历字符串
SQL> select level from dual connect by level<=4;
LEVEL 1
2
3
4SQL> select "拼音",level,substr("拼音",level,1) from (select 'TTXS' as "拼音" FROM DUAL) connect by level <=4;
拼音 LEVEL SUB
TTXS 1 T
TTXS 2 T
TTXS 3 X
TTXS 4 S
4.2 字符串'
SQL> select 'g''day mate' qmarks from dual;
QMARKS
g'day mate
下面是10g
SQL> select q'[g'day mate]' qmarks from dual;
QMARKS
g'day mate
SQL> select q'{g'day mate}' qmarks from dual;
QMARKS
g'day mate
SQL> select q'<g'day mate>' qmarks from dual;
QMARKS
g'day mate
SQL> select q'(g'day mate)' qmarks from dual;
QMARKS
g'day mate
4.3 统计字符串出现次数
11g
SQL> select regexp_count('wo shi wo','o') from dual;
REGEXP_COUNT('WOSHIWO','O')
2SQL> select length(translate('wo shi wo','wo shi wo','o')) from dual;
LENGTH(TRANSLATE('WOSHIWO','WOSHIWO','O'))
2 4.4 从字符里面删除不需要的
SQL> select ename,translate(ename,'1AEIOU','1') from emp;
ENAME TRANSLATE(ENAME,'1AEIOU','1')
SMITH SMTH
ALLEN LLN
WARD WRD
JONES JNS
MARTIN MRTN
BLAKE BLK
CLARK CLRK
KING KNG
TURNER TRNR
JAMES JMS
FORD FRD
ENAME TRANSLATE(ENAME,'1AEIOU','1')
MILLER MLLR
12 rows selected.
SQL> select ename,regexp_replace(ename,'[AEIOU]') from emp;
ENAME REGEXP_REPLACE(ENAME,'[AEIOU]'
SMITH SMTH
ALLEN LLN
WARD WRD
JONES JNS
MARTIN MRTN
BLAKE BLK
CLARK CLRK
KING KNG
TURNER TRNR
JAMES JMS
FORD FRD
ENAME REGEXP_REPLACE(ENAME,'[AEIOU]'
MILLER MLLR
12 rows selected.
4.5 将字母与数字分开
SQL> select dname||deptno,translate(dname||deptno,'a0123456789','a') as data,translate(DNAME||DEPTNO,'0123456789'||dname||deptno,'0123456789') as data1 from dept;
ACCOUNTING10 ACCOUNTING 10
RESEARCH20 RESEARCH 20
SALES30 SALES 30
SQL> select dname||deptno,regexp_replace(dname||deptno,'[0-9]','') as data,regexp_replace(DNAME||DEPTNO,'[^0-9]','') as data1 from dept;
ACCOUNTING10 ACCOUNTING 10
RESEARCH20 RESEARCH 20
SALES30 SALES 30
4.6 ^,$.,+意义
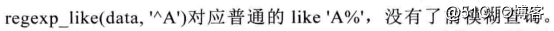

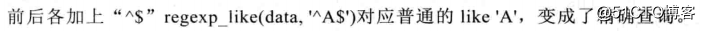
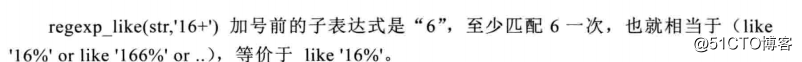
表示自少匹配6零次
4.7 姓名字母首字大写
SQL> select regexp_replace('Michael Hartstein','([[:upper:]])(.)([[:upper:]])(.)','\1.\3') from dual;
REG
M.H
4.8 按字符串中数字排序
SQL> select dname||deptno||loc from dept order by translate(dname||deptno||loc,'0123456789'||dname||deptno||loc,'0123456789') desc;
DNAME||DEPTNO||LOC
SALES30CHICAGO
RESEARCH20DALLAS
ACCOUNTING10NEW YORK
SQL> select dname||deptno||loc from dept order by regexp_replace(dname||deptno||loc,'[^0-9]') desc;
DNAME||DEPTNO||LOC
SALES30CHICAGO
RESEARCH20DALLAS
ACCOUNTING10NEW YORK
4.9 创建分割列表
SQL> select deptno,sal,ename from emp;
DEPTNO SAL ENAME 20 800 SMITH
30 1600 ALLEN
30 1250 WARD
20 2975 JONES
30 1250 MARTIN
30 2850 BLAKE
10 2450 CLARK
10 5000 KING
30 1500 TURNER
30 950 JAMES
20 3000 FORD
DEPTNO SAL ENAME 10 1300 MILLER12 rows selected.
SQL> col TOTAL_SAL format 999999
SQL> col TOTAL_name format A100
SQL> select deptno,
2 sum(sal) as total_sal,
3 listagg(ename,',') within group(order by ename) as total_name
4 from emp
5 group by deptno;
DEPTNO TOTAL_SAL TOTAL_NAME 10 8750 CLARK,KING,MILLER
20 6775 FORD,JONES,SMITH
30 9400 ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD4.10 提取第n个分割子串
SQL> run
1 with
2 a as
3 (
4 select listagg(ename,',') within group(order by ename) as name from emp where deptno in(10,20) group by deptno
5 )
6* select regexp_substr(a.name,'[^,]+',1,2) as "子串" from a
子串
KING
JONES
4.11 分解ip地址
SQL> run
1 select regexp_substr(v.ip,'[^.]+',1,1 ) a
2 ,regexp_substr(v.ip,'[^.]+',1,2 ) b
3 ,regexp_substr(v.ip,'[^.]+',1,3) c
4 ,regexp_substr(v.ip,'[^.]+',1,4 ) d
5* from (select '192.168.0.1' as ip from dual) v
A B C D
192 168 0 1
4.12 将分个数据转换成多值IN
SQL> var v_emps varchar2(30);
SQL> exec :v_emps :='CLARK,KING,MILLER';
PL/SQL procedure successfully completed.
SQL> SET LINE 1000
SQL> run
1 SELECT FROM EMP WHERE ENAME IN
2 (
3 SELECT REGEXP_SUBSTR(:v_emps,'[^,]+',1,level) as ename from dual
4 connect by level <=(length(translate(:v_emps,','||:v_emps,','))+1)
5 )
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450 10
7839 KING PRESIDENT 1981-11-17 00:00:00 5000 10
7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300 10第五 使用数字
5.1 累计和
SQL> select empno,
2 ename,
3 sal,
4 sum(sal) over (order by empno)
5 from emp
6 where deptno=30
7 order by empno;
EMPNO ENAME SAL SUM(SAL)OVER(ORDERBYEMPNO) 7499 ALLEN 1600 1600
7521 WARD 1250 2850
7654 MARTIN 1250 4100
7698 BLAKE 2850 6950
7844 TURNER 1500 8450
7900 JAMES 950 94006 rows selected.
5.2 返回各部门排行前三的员工
SQL> run
1 select deptno,
2 empno,
3 sal,
4 row_number() over (partition by deptno order by sal desc) as row_num,
5 rank() over (partition by deptno order by sal desc) as rank,
6 dense_rank() over (partition by deptno order by sal desc) as dense_rank
7 from emp
8 where deptno in (20,30)
9* order by 1,3 desc
DEPTNO EMPNO SAL ROW_NUM RANK DENSE_RANK 20 7902 3000 1 1 1
20 7566 2975 2 2 2
20 7369 800 3 3 3
30 7698 2850 1 1 1
30 7499 1600 2 2 2
30 7844 1500 3 3 3
30 7521 1250 4 4 4
30 7654 1250 5 4 4
30 7900 950 6 6 59 rows selected.
5.3 返回最大值所在行数据
SQL> run
1 select deptno,
2 empno,
3 max(ename) keep(dense_rank first order by sal) over (partition by deptno),
4 max(ename) keep(dense_rank last order by sal) over (partition by deptno),
5 ename,
6 sal
7 from emp
8 where deptno=10
9* order by 1,6 desc
DEPTNO EMPNO MAX(ENAME) MAX(ENAME) ENAME SAL 10 7839 MILLER KING KING 5000
10 7782 MILLER KING CLARK 2450
10 7934 MILLER KING MILLER 1300
SQL> select deptno,2 empno,
3 first_value(ename) over (partition by deptno),
4 ename,
5 sal
6 from emp
7 where deptno=10
8 order by 1,5 desc;
DEPTNO EMPNO FIRST_VALU ENAME SAL 10 7839 KING KING 5000
10 7782 KING CLARK 2450
10 7934 KING MILLER 13005.4 求和百分比
SQL> run
1 select deptno,
2 empno,
3 ename,
4 sal,
5 round(ratio_to_report(sal) over(partition by deptno)100,2)
6 from emp
7 order by 1,2
DEPTNO EMPNO ENAME SAL ROUND(RATIO_TO_REPORT(SAL)OVER(PARTITIONBYDEPTNO)*100,2) 10 7782 CLARK 2450 28
10 7839 KING 5000 57.14
10 7934 MILLER 1300 14.86
20 7369 SMITH 800 11.81
20 7566 JONES 2975 43.91
20 7902 FORD 3000 44.28
30 7499 ALLEN 1600 17.02
30 7521 WARD 1250 13.3
30 7654 MARTIN 1250 13.3
30 7698 BLAKE 2850 30.32
30 7844 TURNER 1500 15.96
DEPTNO EMPNO ENAME SAL ROUND(RATIO_TO_REPORT(SAL)OVER(PARTITIONBYDEPTNO)*100,2) 30 7900 JAMES 950 10.1112 rows selected.
第六 日期
6.1 年月日加减
SQL> select hiredate,
2 hiredate -5,
3 hiredate +5,
4 add_months(hiredate,-5),
5 add_months(hiredate,5),
6 add_months(hiredate,-512),
7 add_months(hiredate,512)
8 from emp
9 where rownum<=1;
HIREDATE HIREDATE-5 HIREDATE+5 ADD_MONTHS(HIREDATE ADD_MONTHS(HIREDATE ADD_MONTHS(HIREDATE ADD_MONTHS(HIREDATE
1980-12-17 00:00:00 1980-12-12 00:00:00 1980-12-22 00:00:00 1980-07-17 00:00:00 1981-05-17 00:00:00 1975-12-17 00:00:00 1985-12-17 00:00:00
6.2 时分秒加减
SQL> run
1 select hiredate,
2 hiredate -5/24/60/60,
3 hiredate +5/24/60/60,
4 hiredate -5/24/60,
5 hiredate +5/24/60,
6 hiredate -5/24,
7 hiredate +5/24
8 from emp
9* where rownum<=1
HIREDATE HIREDATE-5/24/60/60 HIREDATE+5/24/60/60 HIREDATE-5/24/60 HIREDATE+5/24/60 HIREDATE-5/24
HIREDATE+5/24
1980-12-17 00:00:00 1980-12-16 23:59:55 1980-12-17 00:00:05 1980-12-16 23:55:00 1980-12-17 00:05:00 1980-12-16 19:00:00 1980-12-17 05:00:00
6.3 时间间隔
SQL> select max(hiredate)-min(hiredate),
2 (max(hiredate)-min(hiredate))24,
3 (max(hiredate)-min(hiredate))2460,
4 (max(hiredate)-min(hiredate))246060
5 from emp
6 where ename in('WARD','ALLEN')
7 ;
MAX(HIREDATE)-MIN(HIREDATE) (MAX(HIREDATE)-MIN(HIREDATE))24 (MAX(HIREDATE)-MIN(HIREDATE))2460 (MAX(HIREDATE)-MIN(HIREDATE))246060
2 48 2880172800
6.4 日期间隔
SQL> run
1 select max(hiredate)-min(hiredate),
2 months_between(max(hiredate),min(hiredate)),
3 months_between(max(hiredate),min(hiredate))/12
4* from emp
MAX(HIREDATE)-MIN(HIREDATE) MONTHS_BETWEEN(MAX(HIREDATE),MIN(HIREDATE)) MONTHS_BETWEEN(MAX(HIREDATE),MIN(HIREDATE))/12
402 13.1935484 1.099462376.5 当前记录和下一条记录差
SQL> run
1 select deptno,
2 ename,
3 hiredate,
4 lead(hiredate) over(order by hiredate)
5 from emp
6* where deptno=10
DEPTNO ENAME HIREDATE LEAD(HIREDATE)OVER( 10 CLARK 1981-06-09 00:00:00 1981-11-17 00:00:00
10 KING 1981-11-17 00:00:00 1982-01-23 00:00:00
10 MILLER 1982-01-23 00:00:00
SQL> run1 select deptno,
2 ename,
3 hiredate,
4 lag(hiredate) over(order by hiredate)
5 from emp
6* where deptno=10
DEPTNO ENAME HIREDATE LAG(HIREDATE)OVER(O 10 CLARK 1981-06-09 00:00:00
10 KING 1981-11-17 00:00:00 1981-06-09 00:00:00
10 MILLER 1982-01-23 00:00:00 1981-11-17 00:00:00
6.6 sysdate
6.7 interval
SQL> select interval '50' month as month from dual;MONTH
+04-02
SQL> select interval '99' day as day from dual;
DAY
+99 00:00:00
SQL> select interval '80' hour as hour from dual;
HOUR
+03 08:00:00
SQL> select interval '5' year as year from dual;
YEAR
+05-00
6.8 extract
SQL> select extract(year from systimestamp) as year from dual;
YEAR 2017SQL> select extract(month from systimestamp) as month from dual;
MONTH 12SQL> select extract(day from systimestamp) as day from dual;
DAY 27SQL> select extract(hour from systimestamp) as hour from dual;
HOUR 3 
第七 报表和数据仓库
7.1 行转列
SQL> select job,
2 case deptno when 10 then sal end as deptno10,
3 case deptno when 20 then sal end as deptno20,
4 case deptno when 30 then sal end as deptno30,
5 sal
6 from emp
7 order by 1;
JOB DEPTNO10 DEPTNO20 DEPTNO30 SAL
ANALYST 3000 3000
CLERK 1300 1300
CLERK 950 950
CLERK 800 800
MANAGER 2975 2975
MANAGER 2850 2850
MANAGER 2450 2450
PRESIDENT 5000 5000
SALESMAN 1500 1500
SALESMAN 1250 1250
SALESMAN 1600 1600
JOB DEPTNO10 DEPTNO20 DEPTNO30 SAL
SALESMAN 1250 1250
12 rows selected.
SQL> select job,
2 sum(case deptno when 10 then sal end) as deptno10,
3 sum(case deptno when 20 then sal end) as deptno20,
4 sum(case deptno when 30 then sal end) as deptno30,
5 sum(sal) as sal
6 from emp
7 group by job
8 order by 1;
JOB DEPTNO10 DEPTNO20 DEPTNO30 SAL
ANALYST 3000 3000
CLERK 1300 800 950 3050
MANAGER 2450 2975 2850 8275
PRESIDENT 5000 5000
SALESMAN 5600 5600
SQL> select *
2 from (select job,
3 sal
4 ,deptno
5 from emp)
6 pivot(sum(sal) as s
7 for deptno in (10 as d10,
8 20 ,
9 30 as d30)
10 )
11 order by 1;
JOB D10_S 20_S D30_S
ANALYST 3000
CLERK 1300 800 950
MANAGER 2450 2975 2850
PRESIDENT 5000
SALESMAN 5600
7.2 控制结果集重复值
SQL> select job ,ename from emp where deptno=30 order by emp.job,ename;
JOB ENAME
CLERK JAMES
MANAGER BLAKE
SALESMAN ALLEN
SALESMAN MARTIN
SALESMAN TURNER
SALESMAN WARD
6 rows selected.
SQL> select case
2 when lag(job) over(order by job,ename)=job then
3 null
4 else
5 job
6 end as job,
7 ename
8 from emp
9 where deptno=30
10 order by emp.job,ename;
JOB ENAME
CLERK JAMES
MANAGER BLAKE
SALESMAN ALLEN
MARTIN
TURNER
WARD
6 rows selected.
7.3 简单小计
SQL> select deptno,sum(sal) as s_sal from emp group by rollup(deptno)
2 ;
DEPTNO S_SAL 10 8750
20 6775
30 9400
249257.4 分组函数详解
SQL> select DEPTNO,sum(sal) from emp group by deptno;
DEPTNO SUM(SAL) 30 9400
20 6775
10 8750
SQL> select DEPTNO,sum(sal) from emp group by rollup(deptno);
DEPTNO SUM(SAL) 10 8750
20 6775
30 9400
24925
SQL> select DEPTNO,job,sum(sal) from emp group by rollup(deptno,job);
DEPTNO JOB SUM(SAL) 10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 8750
20 CLERK 800
20 ANALYST 3000
20 MANAGER 2975
20 6775
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
DEPTNO JOB SUM(SAL) 30 9400
2492513 rows selected.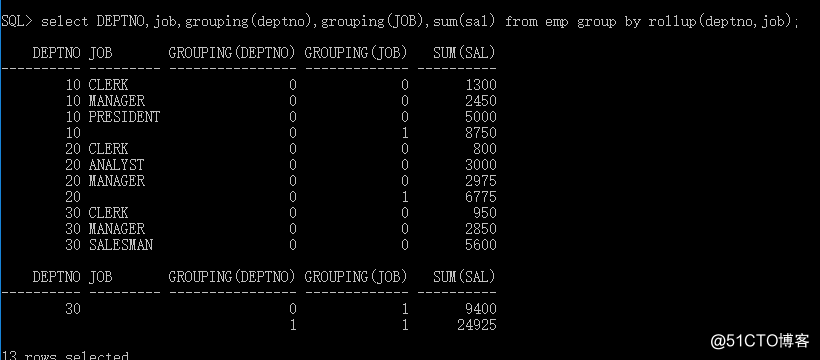
grouping值为0时说明这个值是数据库中本来的值,为1说明是统计的结果
SQL> select DEPTNO,sum(sal) from emp group by cube(deptno) order by 1;
DEPTNO SUM(SAL) 10 8750
20 6775
30 9400
24925
SQL> select DEPTNO,job,sum(sal) from emp group by cube(deptno,job) order by 1;
DEPTNO JOB SUM(SAL) 10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 8750
20 ANALYST 3000
20 CLERK 800
20 MANAGER 2975
20 6775
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
DEPTNO JOB SUM(SAL) 30 9400
ANALYST 3000
CLERK 3050
MANAGER 8275
PRESIDENT 5000
SALESMAN 5600
2492518 rows selected.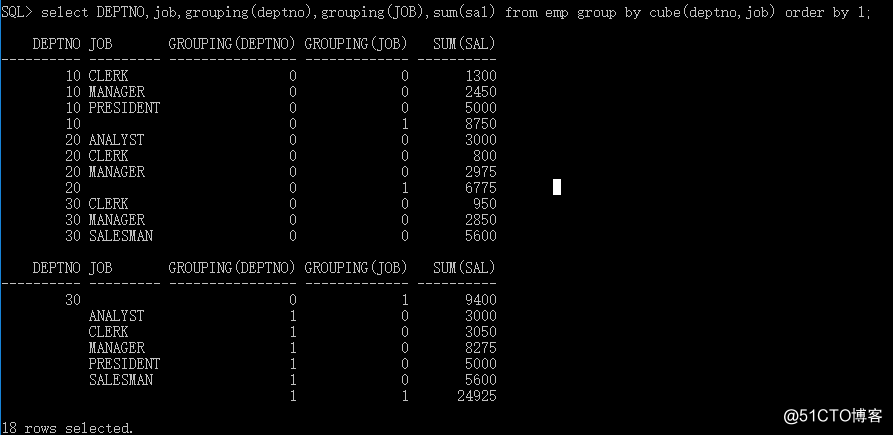
仔细观察一下,CUBE与ROLLUP之间的细微差别
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
……以此类推ing……
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
CUBE在ROLLUP的基础上进一步从各种维度上给出细化的统计汇总结果。
SQL> select DEPTNO,job,sum(sal) from emp group by grouping sets(deptno,job) order by 1;
DEPTNO JOB SUM(SAL) 10 8750
20 6775
30 9400
ANALYST 3000
MANAGER 8275
SALESMAN 5600
CLERK 3050
PRESIDENT 5000
grouping sets就是对參数中的每一个參数做grouping。假设使用group by grouping sets(a,b)。则对(a),(b)进行group by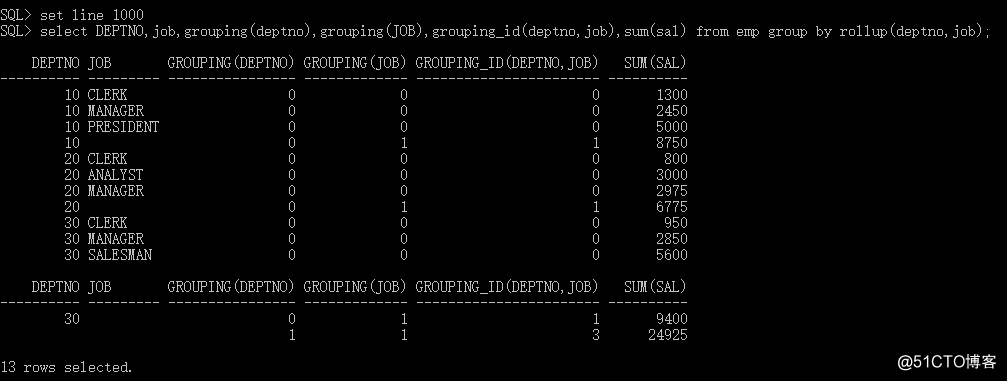
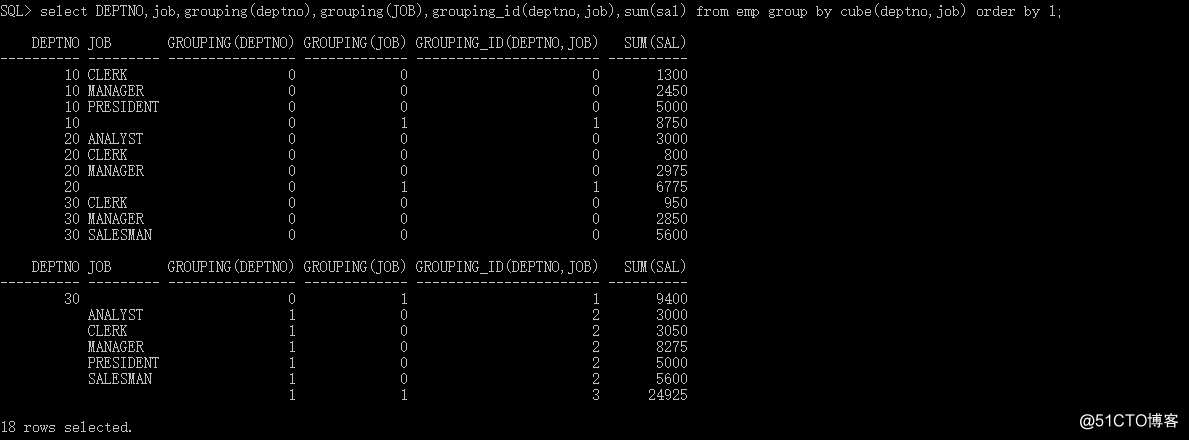
Grouping_id()的返回值事实上就是參数中的每列的grouping()值的二进制向量。假设grouping(a)=1,grouping(b)=1,则grouping_id(A,B)的返回值就是二进制的11。转成10进制就是3。
參数能够是多个,但必须为group by中出现的列。
7.5 不同组进行统计
SQL> select ename,deptno,count() over(partition by deptno),job,count()over(partition by job),count(*) over()
2 from emp;
ENAME DEPTNO COUNT()OVER(PARTITIONBYDEPTNO) JOB COUNT()OVER(PARTITIONBYJOB) COUNT(*)OVER()
KING 10 3 PRESIDENT 1 12
CLARK 10 3 MANAGER 3 12
MILLER 10 3 CLERK 3 12
JONES 20 3 MANAGER 3 12
SMITH 20 3 CLERK 3 12
FORD 20 3 ANALYST 1 12
ALLEN 30 6 SALESMAN 4 12
WARD 30 6 SALESMAN 4 12
TURNER 30 6 SALESMAN 4 12
MARTIN 30 6 SALESMAN 4 12
JAMES 30 6 CLERK 3 12
ENAME DEPTNO COUNT()OVER(PARTITIONBYDEPTNO) JOB COUNT()OVER(PARTITIONBYJOB) COUNT(*)OVER()
BLAKE 30 6 MANAGER 3 12
12 rows selected.
7.6 移动范围内值计算
SQL> select hiredate,
2 sal,
3 sum(sal) over(order by hiredate range between interval '3' month preceding and current row)
4 from emp
5 where deptno=30
6 order by 1;
HIREDATE SAL SUM(SAL)OVER(ORDERBYHIREDATERANGEBETWEENINTERVAL'3'MONTHPRECEDINGANDCURRENTROW)
1981-02-20 00:00:00 1600 1600
1981-02-22 00:00:00 1250 2850
1981-05-01 00:00:00 2850 5700
1981-09-08 00:00:00 1500 1500
1981-09-28 00:00:00 1250 2750
1981-12-03 00:00:00 950 3700
6 rows selected.
第八 分层查询
8.1 简单树形结构
SQL> run
1 select empno,
2 ename,
3 mgr,
4 prior ename
5 from emp
6 start with empno=7566
7 connect by(prior empno)=mgr
8*
EMPNO ENAME MGR PRIORENAME 7566 JONES 7839
7902 FORD 7566 JONES
7369 SMITH 7902 FORD8.2 根节点,分支节点,叶子节点
SQL> run
1 select lpad('-',(level-1)2,'-')||empno as empno,
2 ename,
3 mgr,
4 level,
5 decode(level,1,1) as root,
6 decode(connect_by_isleaf,1,1) as leaf,
7 case
8 when(connect_by_isleaf=0 and level>1) then
9 1
10 end as fenzi
11 from emp
12 start with empno=7566
13 connect by (prior empno)=mgr
EMPNO ENAME MGR LEVEL ROOT LEAF FENZI
7566 JONES 7839 1 1
--7902 FORD 7566 2 1
----7369 SMITH 7902 3 1
8.3 sys_connect_by_path ==listagg
SQL> run
1 select empno,
2 ename,
3 mgr,
4 sys_connect_by_path(ename,',') as enames
5 from emp
6 start with empno=7566
7* connect by (prior empno)=mgr
EMPNO ENAME MGR ENAMES
7566 JONES 7839 ,JONES
7902 FORD 7566 ,JONES,FORD
7369 SMITH 7902 ,JONES,FORD,SMITH
8.4 树形查询排序
SQL> select lpad('-',(level-1)*2,'-')||empno as empno,
2 ename,
3 mgr
4 from emp
5 start with empno=7839
6 connect by (prior empno)=mgr
7 order siblings by emp.empno desc;
EMPNO ENAME MGR
7839 KING
--7782 CLARK 7839
----7934 MILLER 7782
--7698 BLAKE 7839
----7900 JAMES 7698
----7844 TURNER 7698
----7654 MARTIN 7698
----7521 WARD 7698
----7499 ALLEN 7698
--7566 JONES 7839
----7902 FORD 7566
EMPNO ENAME MGR
------7369 SMITH 7902
12 rows selected.
8.5 树型查询使用where
SQL> select empno,
2 mgr,
3 ename,
4 deptno
5 from(select * from emp where deptno=20) emp
6 start with mgr is null
7 connect by(prior empno)=mgr;
no rows selected
8.6 查询树型的一个分支
SQL> run
1 select empno,
2 mgr,
3 ename,
4 level
5 from emp
6 start with empno=7698
7* connect by (prior empno)=mgr
EMPNO MGR ENAME LEVEL
7698 7839 BLAKE 1
7499 7698 ALLEN 2
7521 7698 WARD 2
7654 7698 MARTIN 2
7844 7698 TURNER 2
7900 7698 JAMES 2
8.7 减去一个分支
SQL> run
1 select empno,
2 mgr,
3 ename,
4 level
5 from emp
6 start with mgr is NULL
7* connect by (prior empno)=mgr
EMPNO MGR ENAME LEVEL
7839 KING 1
7566 7839 JONES 2
7902 7566 FORD 3
7369 7902 SMITH 4
7698 7839 BLAKE 2
7499 7698 ALLEN 3
7521 7698 WARD 3
7654 7698 MARTIN 3
7844 7698 TURNER 3
7900 7698 JAMES 3
7782 7839 CLARK 2
EMPNO MGR ENAME LEVEL
7934 7782 MILLER 3
12 rows selected.
SQL> RUN
1 select empno,
2 mgr,
3 ename,
4 level
5 from emp
6 start with mgr is NULL
7 connect by (prior empno)=mgr
8* and empno !=7698
EMPNO MGR ENAME LEVEL
7839 KING 1
7566 7839 JONES 2
7902 7566 FORD 3
7369 7902 SMITH 4
7782 7839 CLARK 2
7934 7782 MILLER 3
6 rows selected.
第九 调优案例分享
9.1 不建议使用标量子查询,使用left join优化标量子查询
SQL> select empno,
2 ename,
3 sal,
4 deptno,
5 (select dname from dept where dept.deptno=emp.deptno)
6 from emp;
EMPNO ENAME SAL DEPTNO (SELECTDNAMEFR
7369 SMITH 800 20 RESEARCH
7499 ALLEN 1600 30 SALES
7521 WARD 1250 30 SALES
7566 JONES 2975 20 RESEARCH
7654 MARTIN 1250 30 SALES
7698 BLAKE 2850 30 SALES
7782 CLARK 2450 10 ACCOUNTING
7839 KING 5000 10 ACCOUNTING
7844 TURNER 1500 30 SALES
7900 JAMES 950 30 SALES
7902 FORD 3000 20 RESEARCH
EMPNO ENAME SAL DEPTNO (SELECTDNAMEFR
7934 MILLER 1300 10 ACCOUNTING
12 rows selected.
SQL> select e.empno,
2 e.ename,
3 e.sal,
4 e.deptno,
5 d.dname
6 from emp e
7 left join dept d on(e.deptno=d.deptno);
EMPNO ENAME SAL DEPTNO DNAME
7782 CLARK 2450 10 ACCOUNTING
7839 KING 5000 10 ACCOUNTING
7934 MILLER 1300 10 ACCOUNTING
7369 SMITH 800 20 RESEARCH
7566 JONES 2975 20 RESEARCH
7902 FORD 3000 20 RESEARCH
7499 ALLEN 1600 30 SALES
7521 WARD 1250 30 SALES
7654 MARTIN 1250 30 SALES
7698 BLAKE 2850 30 SALES
7844 TURNER 1500 30 SALES
EMPNO ENAME SAL DEPTNO DNAME
7900 JAMES 950 30 SALES
12 rows selected.
SQL> run
1 select /+use_nl(e,d)/
2 e.ename,
3 e.sal,
4 e.deptno,
5 d.dname
6 from emp e
7* left join dept d on(e.deptno=d.deptno)
ENAME SAL DEPTNO DNAME
SMITH 800 20 RESEARCH
ALLEN 1600 30 SALES
WARD 1250 30 SALES
JONES 2975 20 RESEARCH
MARTIN 1250 30 SALES
BLAKE 2850 30 SALES
CLARK 2450 10 ACCOUNTING
KING 5000 10 ACCOUNTING
TURNER 1500 30 SALES
JAMES 950 30 SALES
FORD 3000 20 RESEARCH
ENAME SAL DEPTNO DNAME
MILLER 1300 10 ACCOUNTING
12 rows selected.
9.2 使用left jion 优化标量子查聚合
SQL> select d.department_id,
2 d.department_name,
3 d.location_id,
4 nvl((select sum(e.salary)
5 from employees e
6 where e.department_id=d.department_id),
7 0) as sum_sal
8 from departments d;
DEPARTMENT_ID DEPARTMENT_NAME LOCATION_ID SUM_SAL
10 Administration 1700 4400
20 Marketing 1800 19000
30 Purchasing 1700 24900
40 Human Resources 2400 6500
50 Shipping 1500 156400
60 IT 1400 28800
70 Public Relations 2700 10000
80 Sales 2500 304500
90 Executive 1700 58000
100 Finance 1700 51608
110 Accounting 1700 20308DEPARTMENT_ID DEPARTMENT_NAME LOCATION_ID SUM_SAL
120 Treasury 1700 0
130 Corporate Tax 1700 0
140 Control And Credit 1700 0
150 Shareholder Services 1700 0
160 Benefits 1700 0
170 Manufacturing 1700 0
180 Construction 1700 0
190 Contracting 1700 0
200 Operations 1700 0
210 IT Support 1700 0
220 NOC 1700 0DEPARTMENT_ID DEPARTMENT_NAME LOCATION_ID SUM_SAL
230 IT Helpdesk 1700 0
240 Government Sales 1700 0
250 Retail Sales 1700 0
260 Recruiting 1700 0
270 Payroll 1700 027 rows selected.
SQL> select d.department_id,
2 d.department_name,
3 d.location_id,
4 COALESCE(e.sum_sal,0) as sum_sal
5 from departments d
6 left join (select e.department_id,sum(e.salary) as sum_sal
7 from employees e
8 group by e.department_id) e on ( e.department_id=
9 d.department_id);
DEPARTMENT_ID DEPARTMENT_NAME LOCATION_ID SUM_SAL
10 Administration 1700 4400
20 Marketing 1800 19000
30 Purchasing 1700 24900
40 Human Resources 2400 6500
50 Shipping 1500 156400
60 IT 1400 28800
70 Public Relations 2700 10000
80 Sales 2500 304500
90 Executive 1700 58000
100 Finance 1700 51608
110 Accounting 1700 20308DEPARTMENT_ID DEPARTMENT_NAME LOCATION_ID SUM_SAL
120 Treasury 1700 0
130 Corporate Tax 1700 0
140 Control And Credit 1700 0
150 Shareholder Services 1700 0
160 Benefits 1700 0
170 Manufacturing 1700 0
180 Construction 1700 0
190 Contracting 1700 0
200 Operations 1700 0
210 IT Support 1700 0
220 NOC 1700 0DEPARTMENT_ID DEPARTMENT_NAME LOCATION_ID SUM_SAL
230 IT Helpdesk 1700 0
240 Government Sales 1700 0
250 Retail Sales 1700 0
260 Recruiting 1700 0
270 Payroll 1700 027 rows selected.
本文转自whshurk 51CTO博客,原文链接:http://blog.51cto.com/shurk/2054155,如需转载请自行联系原作者






